 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Know-Act Gap via Task-Level Autoregressive Reasoning
Mar 23, 2026LLMs often generate seemingly valid answers to flawed or ill-posed inputs. This is not due to missing knowledge: under discriminative prompting, the same models can mostly identify such issues, yet fail to reflect this in standard generative responses. This reveals a fundamental know-act gap between discriminative recognition and generative behavior. Prior work largely characterizes this issue in narrow settings, such as math word problems or question answering, with limited focus on how to integrate these two modes. In this work, we present a comprehensive analysis using FaultyScience, a newly constructed large-scale, cross-disciplinary benchmark of faulty scientific questions. We show that the gap is pervasive and stems from token-level autoregression, which entangles task selection (validate vs. answer) with content generation, preventing discriminative knowledge from being utilized. To address this, we propose DeIllusionLLM, a task-level autoregressive framework that explicitly models this decision. Through self-distillation, the model unifies discriminative judgment and generative reasoning within a single backbone. Empirically, DeIllusionLLM substantially reduces answer-despite-error failures under natural prompting while maintaining general reasoning performance, demonstrating that self-distillation is an effective and scalable solution for bridging the discriminative-generative know-act gap
Evaluating LLM-Simulated Conversations in Modeling Inconsistent and Uncollaborative Behaviors in Human Social Interaction
Mar 17, 2026Simulating human conversations using large language models (LLMs) has emerged as a scalable methodology for modeling human social interaction. However, simulating human conversations is challenging because they inherently involve inconsistent and uncollaborative behaviors, such as misunderstandings and interruptions. Analysis comparing inconsistent and uncollaborative behaviors in human- and LLM-generated conversations remains limited, although reproducing these behaviors is integral to simulating human-like and complex social interaction. In this work, we introduce CoCoEval, an evaluation framework that analyzes LLM-simulated conversations by detecting 10 types of inconsistent and uncollaborative behaviors at the turn level using an LLM-as-a-Judge. Using CoCoEval, we evaluate GPT-4.1, GPT-5.1, and Claude Opus 4 by comparing the frequencies of detected behaviors in conversations simulated by each model and in human conversations across academic, business, and governmental meetings, as well as debates. Our analysis shows that (1) under vanilla prompting, LLM-simulated conversations exhibit far fewer inconsistent and uncollaborative behaviors than human conversations; (2) prompt engineering does not provide reliable control over these behaviors, as our results show that different prompts lead to their under- or overproduction; and (3) supervised fine-tuning on human conversations can lead LLMs to overproduce a narrow set of behaviors, such as repetition. Our findings highlight the difficulty of simulating human conversations, raising concerns about the use of LLMs as a proxy for human social interaction.
One Model, All Roles: Multi-Turn, Multi-Agent Self-Play Reinforcement Learning for Conversational Social Intelligence
Feb 03, 2026This paper introduces OMAR: One Model, All Roles, a reinforcement learning framework that enables AI to develop social intelligence through multi-turn, multi-agent conversational self-play. Unlike traditional paradigms that rely on static, single-turn optimizations, OMAR allows a single model to role-play all participants in a conversation simultaneously, learning to achieve long-term goals and complex social norms directly from dynamic social interaction. To ensure training stability across long dialogues, we implement a hierarchical advantage estimation that calculates turn-level and token-level advantages. Evaluations in the SOTOPIA social environment and Werewolf strategy games show that our trained models develop fine-grained, emergent social intelligence, such as empathy, persuasion, and compromise seeking, demonstrating the effectiveness of learning collaboration even under competitive scenarios. While we identify practical challenges like reward hacking, our results show that rich social intelligence can emerge without human supervision. We hope this work incentivizes further research on AI social intelligence in group conversations.
Training Step-Level Reasoning Verifiers with Formal Verification Tools
May 21, 2025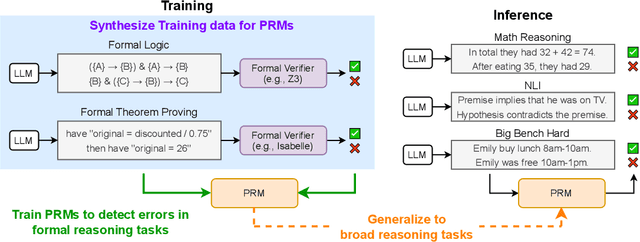


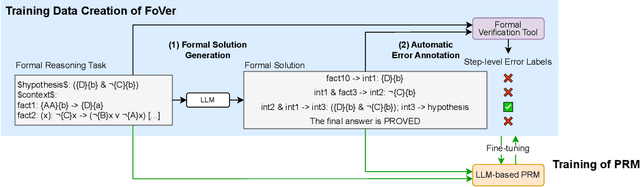
Process Reward Models (PRMs), which provide step-by-step feedback on the reasoning generated by Large Language Models (LLMs), are receiving increasing attention. However, two key research gaps remain: collecting accurate step-level error labels for training typically requires costly human annotation, and existing PRMs are limited to math reasoning problems. In response to these gaps, this paper aims to address the challenges of automatic dataset creation and the generalization of PRMs to diverse reasoning tasks. To achieve this goal, we propose FoVer, an approach for training PRMs on step-level error labels automatically annotated by formal verification tools, such as Z3 for formal logic and Isabelle for theorem proof, which provide automatic and accurate verification for symbolic tasks. Using this approach, we synthesize a training dataset with error labels on LLM responses for formal logic and theorem proof tasks without human annotation. Although this data synthesis is feasible only for tasks compatible with formal verification, we observe that LLM-based PRMs trained on our dataset exhibit cross-task generalization, improving verification across diverse reasoning tasks. Specifically, PRMs trained with FoVer significantly outperform baseline PRMs based on the original LLMs and achieve competitive or superior results compared to state-of-the-art PRMs trained on labels annotated by humans or stronger models, as measured by step-level verification on ProcessBench and Best-of-K performance across 12 reasoning benchmarks, including MATH, AIME, ANLI, MMLU, and BBH. The datasets, models, and code are provided at https://github.com/psunlpgroup/FoVer.
HRScene: How Far Are VLMs from Effective High-Resolution Image Understanding?
Apr 29, 2025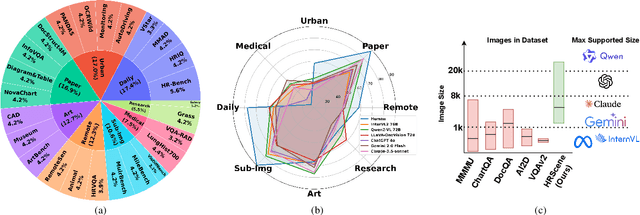
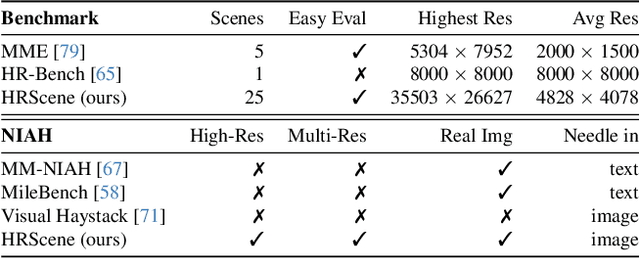
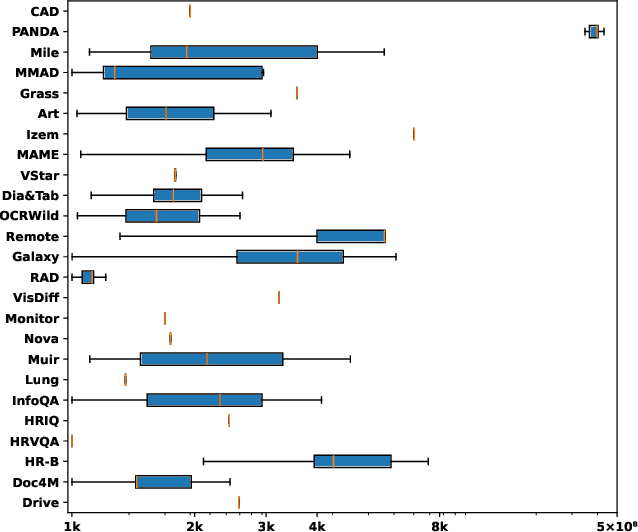
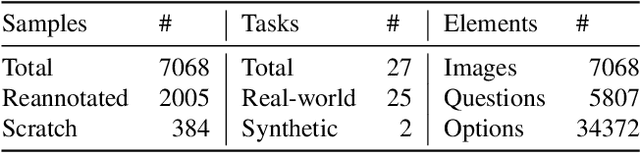
High-resolution image (HRI) understanding aims to process images with a large number of pixels, such as pathological images and agricultural aerial images, both of which can exceed 1 million pixels. Vision Large Language Models (VLMs) can allegedly handle HRIs, however, there is a lack of a comprehensive benchmark for VLMs to evaluate HRI understanding. To address this gap, we introduce HRScene, a novel unified benchmark for HRI understanding with rich scenes. HRScene incorporates 25 real-world datasets and 2 synthetic diagnostic datasets with resolutions ranging from 1,024 $\times$ 1,024 to 35,503 $\times$ 26,627. HRScene is collected and re-annotated by 10 graduate-level annotators, covering 25 scenarios, ranging from microscopic to radiology images, street views, long-range pictures, and telescope images. It includes HRIs of real-world objects, scanned documents, and composite multi-image. The two diagnostic evaluation datasets are synthesized by combining the target image with the gold answer and distracting images in different orders, assessing how well models utilize regions in HRI. We conduct extensive experiments involving 28 VLMs, including Gemini 2.0 Flash and GPT-4o. Experiments on HRScene show that current VLMs achieve an average accuracy of around 50% on real-world tasks, revealing significant gaps in HRI understanding. Results on synthetic datasets reveal that VLMs struggle to effectively utilize HRI regions, showing significant Regional Divergence and lost-in-middle, shedding light on future research.
GReaTer: Gradients over Reasoning Makes Smaller Language Models Strong Prompt Optimizers
Dec 12, 2024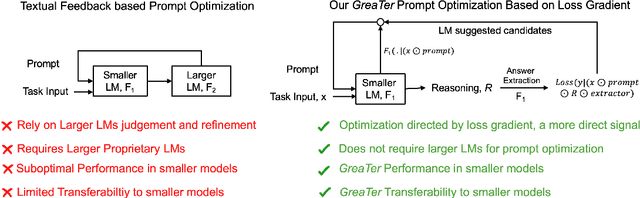
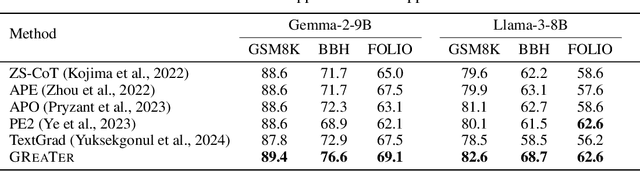
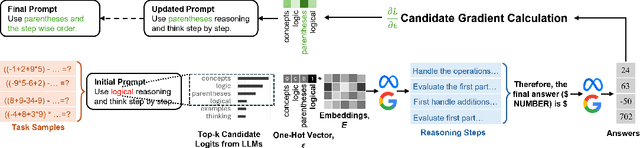
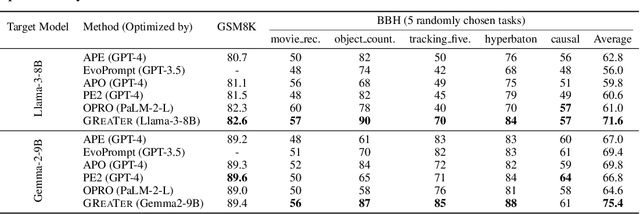
The effectiveness of large language models (LLMs) is closely tied to the design of prompts, making prompt optimization essential for enhancing their performance across a wide range of tasks. Many existing approaches to automating prompt engineering rely exclusively on textual feedback, refining prompts based solely on inference errors identified by large, computationally expensive LLMs. Unfortunately, smaller models struggle to generate high-quality feedback, resulting in complete dependence on large LLM judgment. Moreover, these methods fail to leverage more direct and finer-grained information, such as gradients, due to operating purely in text space. To this end, we introduce GReaTer, a novel prompt optimization technique that directly incorporates gradient information over task-specific reasoning. By utilizing task loss gradients, GReaTer enables self-optimization of prompts for open-source, lightweight language models without the need for costly closed-source LLMs. This allows high-performance prompt optimization without dependence on massive LLMs, closing the gap between smaller models and the sophisticated reasoning often needed for prompt refinement. Extensive evaluations across diverse reasoning tasks including BBH, GSM8k, and FOLIO demonstrate that GReaTer consistently outperforms previous state-of-the-art prompt optimization methods, even those reliant on powerful LLMs. Additionally, GReaTer-optimized prompts frequently exhibit better transferability and, in some cases, boost task performance to levels comparable to or surpassing those achieved by larger language models, highlighting the effectiveness of prompt optimization guided by gradients over reasoning. Code of GReaTer is available at https://github.com/psunlpgroup/GreaTer.
VisOnlyQA: Large Vision Language Models Still Struggle with Visual Perception of Geometric Information
Dec 01, 2024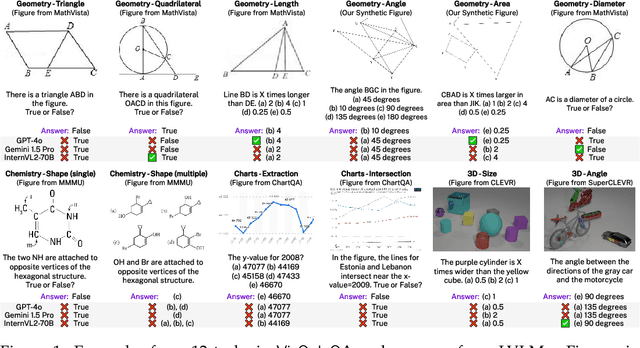

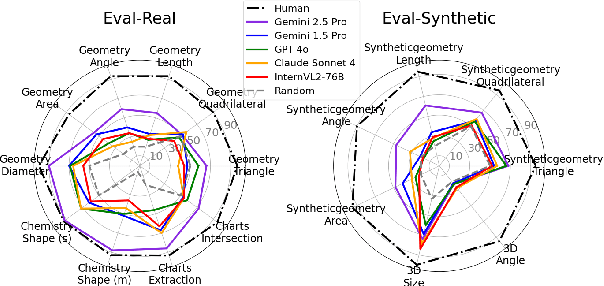
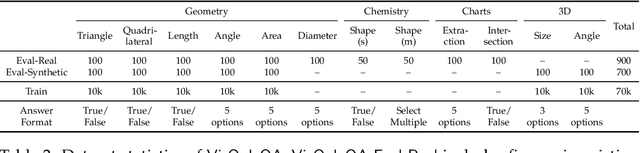
Errors in understanding visual information in images (i.e., visual perception errors) remain a major source of mistakes in Large Vision Language Models (LVLMs). While further analysis is essential, there is a deficiency in datasets for evaluating the visual perception of LVLMs. In this work, we introduce VisOnlyQA, a new dataset designed to directly evaluate the visual perception capabilities of LVLMs on questions about geometric and numerical information in scientific figures. Our dataset enables us to analyze the visual perception of LVLMs for fine-grained visual information, independent of other capabilities such as reasoning. The evaluation set of VisOnlyQA includes 1,200 multiple-choice questions in 12 tasks on four categories of figures. We also provide synthetic training data consisting of 70k instances. Our experiments on VisOnlyQA highlight the following findings: (i) 20 LVLMs we evaluate, including GPT-4o and Gemini 1.5 Pro, work poorly on the visual perception tasks in VisOnlyQA, while human performance is nearly perfect. (ii) Fine-tuning on synthetic training data demonstrates the potential for enhancing the visual perception of LVLMs, but observed improvements are limited to certain tasks and specific models. (iii) Stronger language models improve the visual perception of LVLMs. In summary, our experiments suggest that both training data and model architectures should be improved to enhance the visual perception capabilities of LVLMs. The datasets, code, and model responses are provided at https://github.com/psunlpgroup/VisOnlyQA.
AAAR-1.0: Assessing AI's Potential to Assist Research
Oct 29, 2024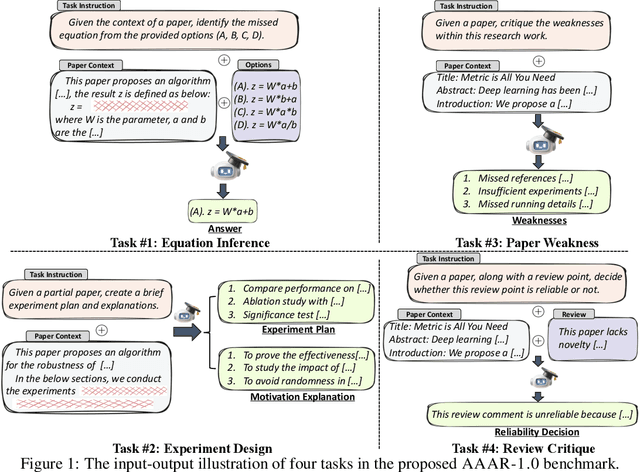
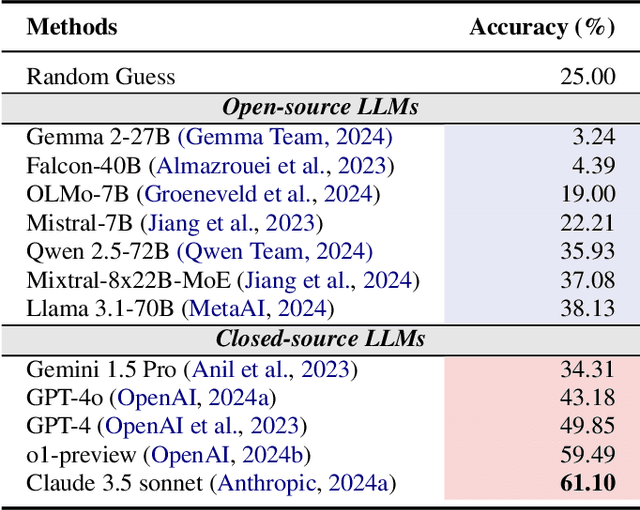
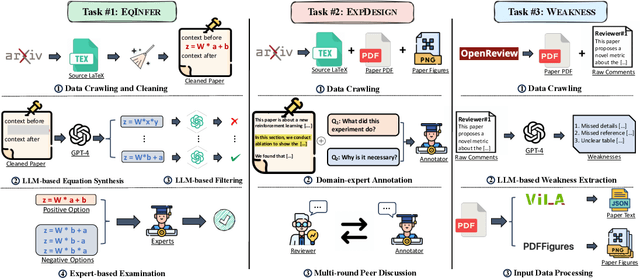
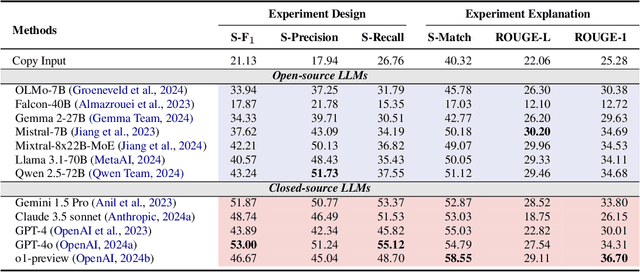
Numerous studies have assessed the proficiency of AI systems, particularly large language models (LLMs), in facilitating everyday tasks such as email writing, question answering, and creative content generation. However, researchers face unique challenges and opportunities in leveraging LLMs for their own work, such as brainstorming research ideas, designing experiments, and writing or reviewing papers. In this study, we introduce AAAR-1.0, a benchmark dataset designed to evaluate LLM performance in three fundamental, expertise-intensive research tasks: (i) EquationInference, assessing the correctness of equations based on the contextual information in paper submissions; (ii) ExperimentDesign, designing experiments to validate research ideas and solutions; (iii) PaperWeakness, identifying weaknesses in paper submissions; and (iv) REVIEWCRITIQUE, identifying each segment in human reviews is deficient or not. AAAR-1.0 differs from prior benchmarks in two key ways: first, it is explicitly research-oriented, with tasks requiring deep domain expertise; second, it is researcher-oriented, mirroring the primary activities that researchers engage in on a daily basis. An evaluation of both open-source and proprietary LLMs reveals their potential as well as limitations in conducting sophisticated research tasks. We will keep iterating AAAR-1.0 to new versions.
When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs
Jun 03, 2024Self-correction is an approach to improving responses from large language models (LLMs) by refining the responses using LLMs during inference. Prior work has proposed various self-correction frameworks using different sources of feedback, including self-evaluation and external feedback. However, there is still no consensus on the question of when LLMs can correct their own mistakes, as recent studies also report negative results. In this work, we critically survey broad papers and discuss the conditions required for successful self-correction. We first find that prior studies often do not define their research questions in detail and involve impractical frameworks or unfair evaluations that over-evaluate self-correction. To tackle these issues, we categorize research questions in self-correction research and provide a checklist for designing appropriate experiments. Our critical survey based on the newly categorized research questions shows that (1) no prior work demonstrates successful self-correction with feedback from prompted LLMs in general tasks, (2) self-correction works well in tasks that can use reliable external feedback, and (3) large-scale fine-tuning enables self-correction.
Evaluating LLMs at Detecting Errors in LLM Responses
Apr 04, 2024



With Large Language Models (LLMs) being widely used across various tasks, detecting errors in their responses is increasingly crucial. However, little research has been conducted on error detection of LLM responses. Collecting error annotations on LLM responses is challenging due to the subjective nature of many NLP tasks, and thus previous research focuses on tasks of little practical value (e.g., word sorting) or limited error types (e.g., faithfulness in summarization). This work introduces ReaLMistake, the first error detection benchmark consisting of objective, realistic, and diverse errors made by LLMs. ReaLMistake contains three challenging and meaningful tasks that introduce objectively assessable errors in four categories (reasoning correctness, instruction-following, context-faithfulness, and parameterized knowledge), eliciting naturally observed and diverse errors in responses of GPT-4 and Llama 2 70B annotated by experts. We use ReaLMistake to evaluate error detectors based on 12 LLMs. Our findings show: 1) Top LLMs like GPT-4 and Claude 3 detect errors made by LLMs at very low recall, and all LLM-based error detectors perform much worse than humans. 2) Explanations by LLM-based error detectors lack reliability. 3) LLMs-based error detection is sensitive to small changes in prompts but remains challenging to improve. 4) Popular approaches to improving LLMs, including self-consistency and majority vote, do not improve the error detection performance. Our benchmark and code are provided at https://github.com/psunlpgroup/ReaLMistake.