 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperclass-Guided Representation Disentanglement for Spurious Correlation Mitigation
Aug 12, 2025



To enhance group robustness to spurious correlations, prior work often relies on auxiliary annotations for groups or spurious features and assumes identical sets of groups across source and target domains. These two requirements are both unnatural and impractical in real-world settings. To overcome these limitations, we propose a method that leverages the semantic structure inherent in class labels--specifically, superclass information--to naturally reduce reliance on spurious features. Our model employs gradient-based attention guided by a pre-trained vision-language model to disentangle superclass-relevant and irrelevant features. Then, by promoting the use of all superclass-relevant features for prediction, our approach achieves robustness to more complex spurious correlations without the need to annotate any source samples. Experiments across diverse datasets demonstrate that our method significantly outperforms baselines in domain generalization tasks, with clear improvements in both quantitative metrics and qualitative visualizations.
SUCEA: Reasoning-Intensive Retrieval for Adversarial Fact-checking through Claim Decomposition and Editing
Jun 05, 2025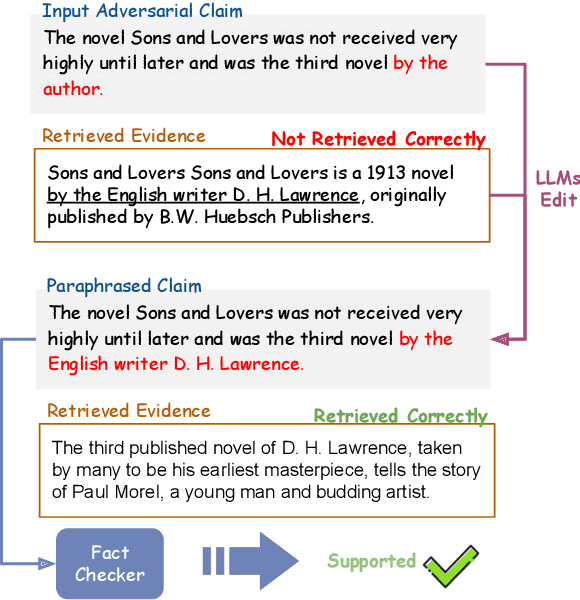
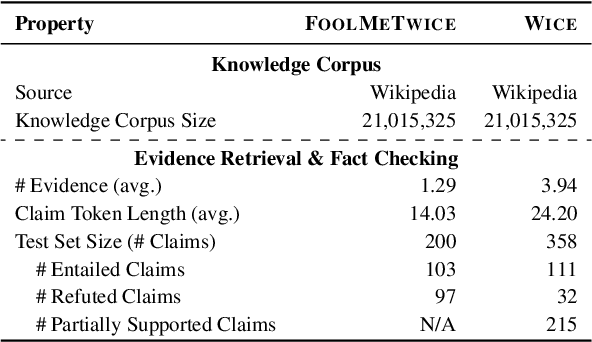
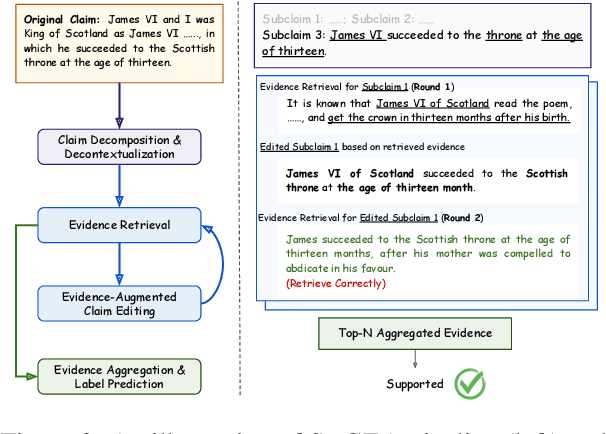
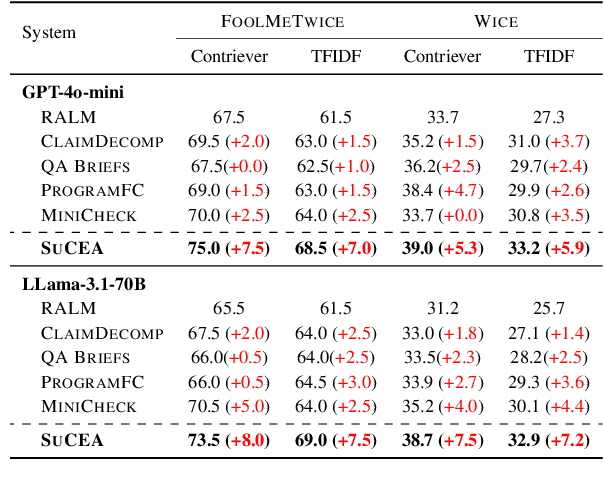
Automatic fact-checking has recently received more attention as a means of combating misinformation. Despite significant advancements, fact-checking systems based on retrieval-augmented language models still struggle to tackle adversarial claims, which are intentionally designed by humans to challenge fact-checking systems. To address these challenges, we propose a training-free method designed to rephrase the original claim, making it easier to locate supporting evidence. Our modular framework, SUCEA, decomposes the task into three steps: 1) Claim Segmentation and Decontextualization that segments adversarial claims into independent sub-claims; 2) Iterative Evidence Retrieval and Claim Editing that iteratively retrieves evidence and edits the subclaim based on the retrieved evidence; 3) Evidence Aggregation and Label Prediction that aggregates all retrieved evidence and predicts the entailment label. Experiments on two challenging fact-checking datasets demonstrate that our framework significantly improves on both retrieval and entailment label accuracy, outperforming four strong claim-decomposition-based baselines.
Comparative Analysis of Pre-trained Deep Learning Models and DINOv2 for Cushing's Syndrome Diagnosis in Facial Analysis
Jan 21, 2025



Cushing's syndrome is a condition caused by excessive glucocorticoid secretion from the adrenal cortex, often manifesting with moon facies and plethora, making facial data crucial for diagnosis. Previous studies have used pre-trained convolutional neural networks (CNNs) for diagnosing Cushing's syndrome using frontal facial images. However, CNNs are better at capturing local features, while Cushing's syndrome often presents with global facial features. Transformer-based models like ViT and SWIN, which utilize self-attention mechanisms, can better capture long-range dependencies and global features. Recently, DINOv2, a foundation model based on visual Transformers, has gained interest. This study compares the performance of various pre-trained models, including CNNs, Transformer-based models, and DINOv2, in diagnosing Cushing's syndrome. We also analyze gender bias and the impact of freezing mechanisms on DINOv2. Our results show that Transformer-based models and DINOv2 outperformed CNNs, with ViT achieving the highest F1 score of 85.74%. Both the pre-trained model and DINOv2 had higher accuracy for female samples. DINOv2 also showed improved performance when freezing parameters. In conclusion, Transformer-based models and DINOv2 are effective for Cushing's syndrome classification.
FinDVer: Explainable Claim Verification over Long and Hybrid-Content Financial Documents
Nov 08, 2024
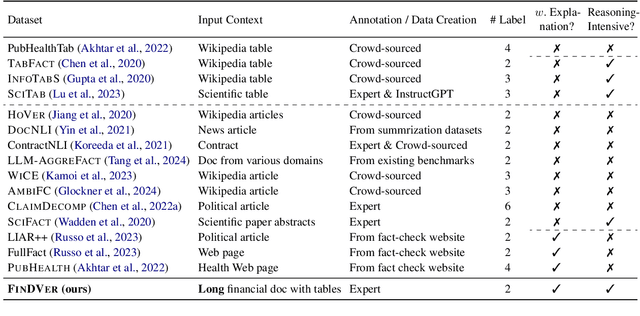
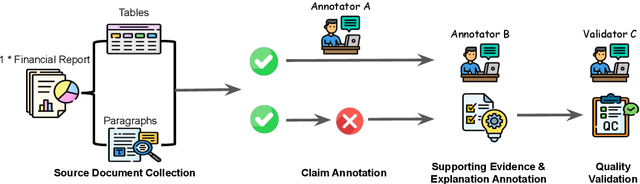
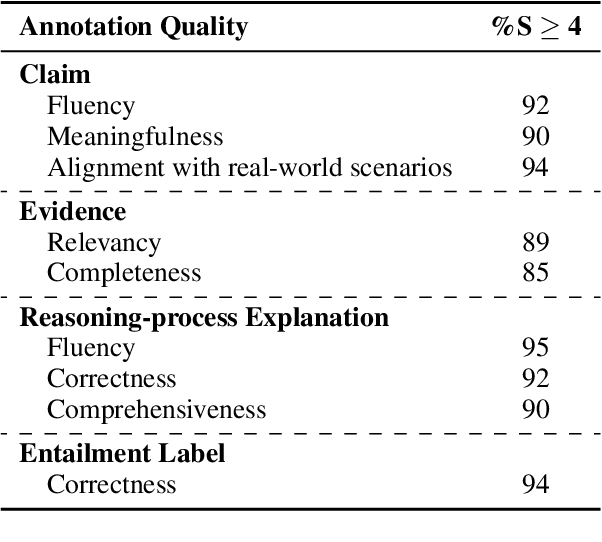
We introduce FinDVer, a comprehensive benchmark specifically designed to evaluate the explainable claim verification capabilities of LLMs in the context of understanding and analyzing long, hybrid-content financial documents. FinDVer contains 2,400 expert-annotated examples, divided into three subsets: information extraction, numerical reasoning, and knowledge-intensive reasoning, each addressing common scenarios encountered in real-world financial contexts. We assess a broad spectrum of LLMs under long-context and RAG settings. Our results show that even the current best-performing system, GPT-4o, still lags behind human experts. We further provide in-depth analysis on long-context and RAG setting, Chain-of-Thought reasoning, and model reasoning errors, offering insights to drive future advancements. We believe that FinDVer can serve as a valuable benchmark for evaluating LLMs in claim verification over complex, expert-domain documents.
KnowledgeMath: Knowledge-Intensive Math Word Problem Solving in Finance Domains
Nov 16, 2023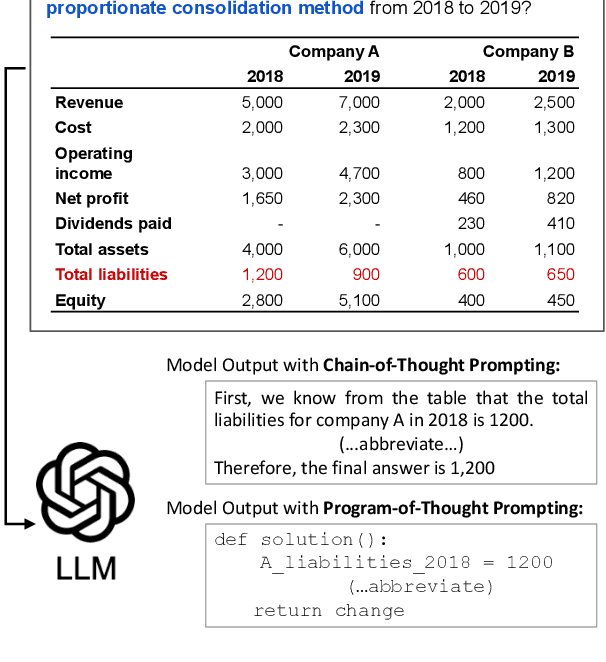
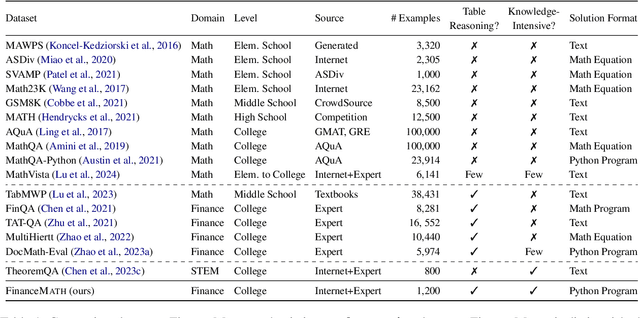

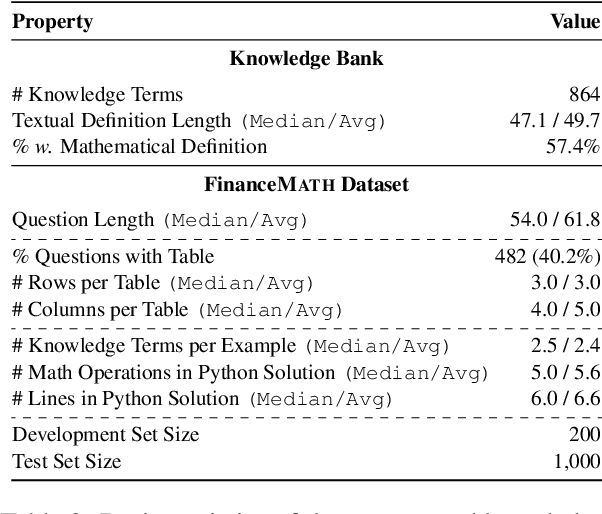
We introduce KnowledgeMath, a novel benchmark designed to evaluate LLMs' capabilities in applying financial knowledge to solve complex math word problems. Compared to prior works, this study features three core advancements. First, KnowledgeMath includes 1,259 problems with a hybrid of textual and tabular content and require college-level knowledge in the finance domain for effective resolution. Second, we provide expert-annotated, detailed solution references in Python program format, ensuring a high-quality benchmark for LLM assessment. Finally, we evaluate a wide spectrum of 14 LLMs with different prompting strategies like Chain-of-Thoughts and Program-of-Thoughts. The current best-performing system (i.e., GPT-4 with Program-of-Thoughts) achieves only 45.4% accuracy, leaving substantial room for improvement. While knowledge-augmented LLMs can improve the performance (e.g., from 23.9% to 32.0% for GPT-3.5), it is still significantly lower the estimated human expert performance of 94%. We believe that KnowledgeMath can facilitate future research on domain-specific knowledge retrieval and augmentation into the math word problem-solving process. We will release the benchmark and code at https://github.com/yale-nlp/KnowledgeMath.
DocMath-Eval: Evaluating Numerical Reasoning Capabilities of LLMs in Understanding Long Documents with Tabular Data
Nov 16, 2023
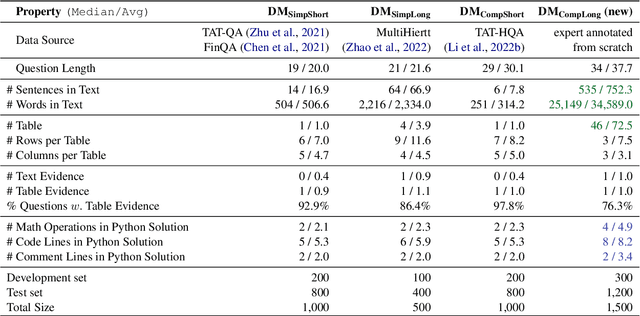

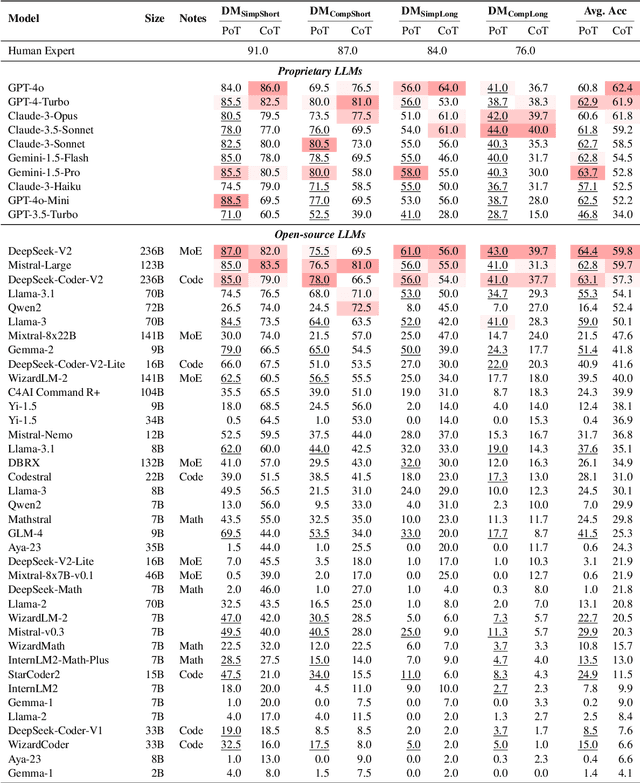
Recent LLMs have demonstrated remarkable performance in solving exam-like math word problems. However, the degree to which these numerical reasoning skills are effective in real-world scenarios, particularly in expert domains, is still largely unexplored. This paper introduces DocMath-Eval, a comprehensive benchmark specifically designed to evaluate the numerical reasoning and problem-solving capabilities of LLMs in the context of understanding and analyzing financial documents containing both text and tables. We evaluate a wide spectrum of 19 LLMs, including those specialized in coding and finance. We also incorporate different prompting strategies (i.e., Chain-of-Thoughts and Program-of-Thoughts) to comprehensively assess the capabilities and limitations of existing LLMs in DocMath-Eval. We found that, although the current best-performing system (i.e., GPT-4), can perform well on simple problems such as calculating the rate of increase in a financial metric within a short document context, it significantly lags behind human experts in more complex problems grounded in longer contexts. We believe DocMath-Eval can be used as a valuable benchmark to evaluate LLMs' capabilities to solve challenging numerical reasoning problems in expert domains. We will release the benchmark and code at https://github.com/yale-nlp/DocMath-Eval.