 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinDVer: Explainable Claim Verification over Long and Hybrid-Content Financial Documents
Paper and Code

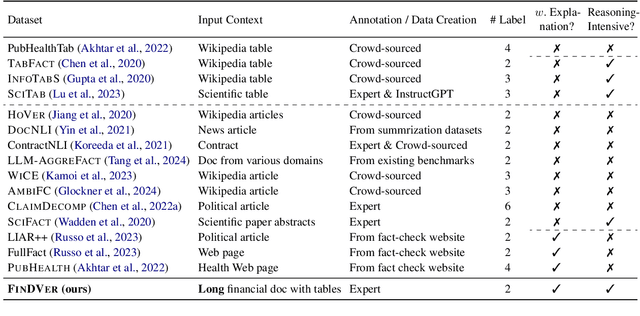
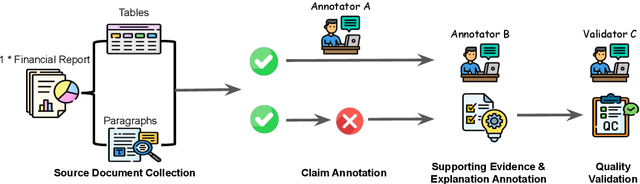
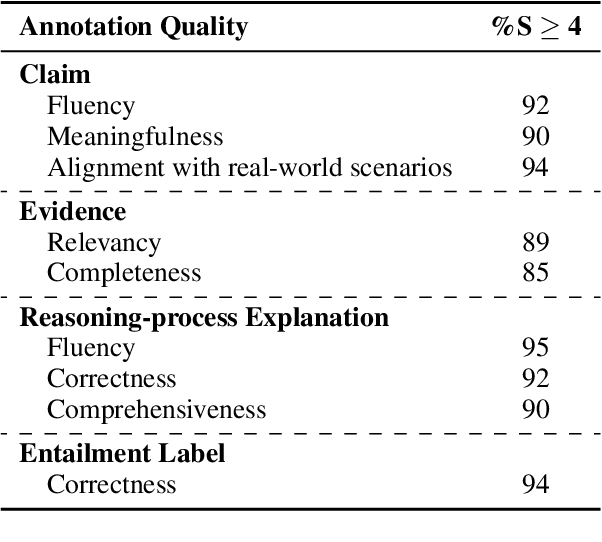
We introduce FinDVer, a comprehensive benchmark specifically designed to evaluate the explainable claim verification capabilities of LLMs in the context of understanding and analyzing long, hybrid-content financial documents. FinDVer contains 2,400 expert-annotated examples, divided into three subsets: information extraction, numerical reasoning, and knowledge-intensive reasoning, each addressing common scenarios encountered in real-world financial contexts. We assess a broad spectrum of LLMs under long-context and RAG settings. Our results show that even the current best-performing system, GPT-4o, still lags behind human experts. We further provide in-depth analysis on long-context and RAG setting, Chain-of-Thought reasoning, and model reasoning errors, offering insights to drive future advancements. We believe that FinDVer can serve as a valuable benchmark for evaluating LLMs in claim verification over complex, expert-domain documents.