 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMVU: Measuring Expert-Level Multi-Discipline Video Understanding
Jan 21, 2025



We introduce MMVU, a comprehensive expert-level, multi-discipline benchmark for evaluating foundation models in video understanding. MMVU includes 3,000 expert-annotated questions spanning 27 subjects across four core disciplines: Science, Healthcare, Humanities & Social Sciences, and Engineering. Compared to prior benchmarks, MMVU features three key advancements. First, it challenges models to apply domain-specific knowledge and perform expert-level reasoning to analyze specialized-domain videos, moving beyond the basic visual perception typically assessed in current video benchmarks. Second, each example is annotated by human experts from scratch. We implement strict data quality controls to ensure the high quality of the dataset. Finally, each example is enriched with expert-annotated reasoning rationals and relevant domain knowledge, facilitating in-depth analysis. We conduct an extensive evaluation of 32 frontier multimodal foundation models on MMVU. The latest System-2-capable models, o1 and Gemini 2.0 Flash Thinking, achieve the highest performance among the tested models. However, they still fall short of matching human expertise. Through in-depth error analyses and case studies, we offer actionable insights for future advancements in expert-level, knowledge-intensive video understanding for specialized domains.
FinDVer: Explainable Claim Verification over Long and Hybrid-Content Financial Documents
Nov 08, 2024
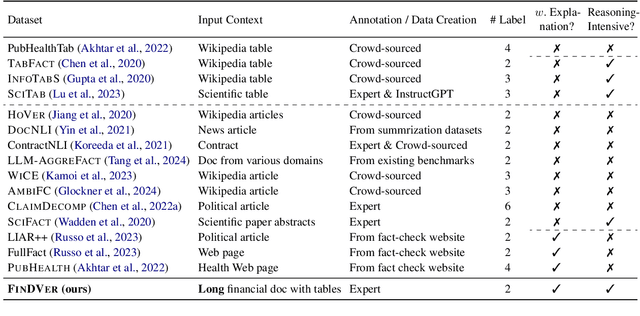
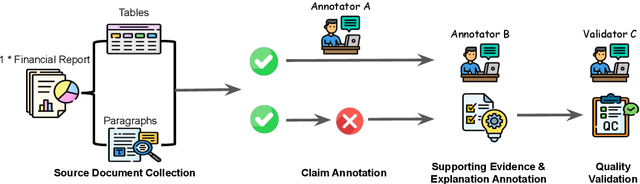
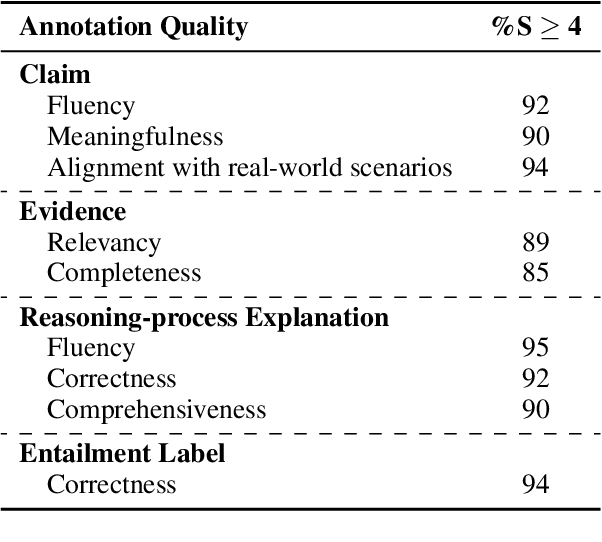
We introduce FinDVer, a comprehensive benchmark specifically designed to evaluate the explainable claim verification capabilities of LLMs in the context of understanding and analyzing long, hybrid-content financial documents. FinDVer contains 2,400 expert-annotated examples, divided into three subsets: information extraction, numerical reasoning, and knowledge-intensive reasoning, each addressing common scenarios encountered in real-world financial contexts. We assess a broad spectrum of LLMs under long-context and RAG settings. Our results show that even the current best-performing system, GPT-4o, still lags behind human experts. We further provide in-depth analysis on long-context and RAG setting, Chain-of-Thought reasoning, and model reasoning errors, offering insights to drive future advancements. We believe that FinDVer can serve as a valuable benchmark for evaluating LLMs in claim verification over complex, expert-domain documents.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
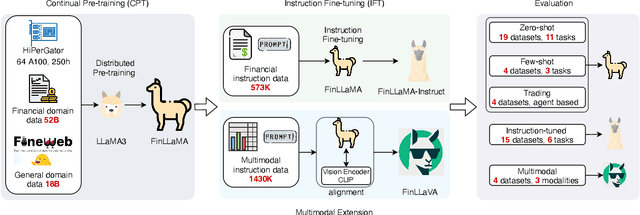
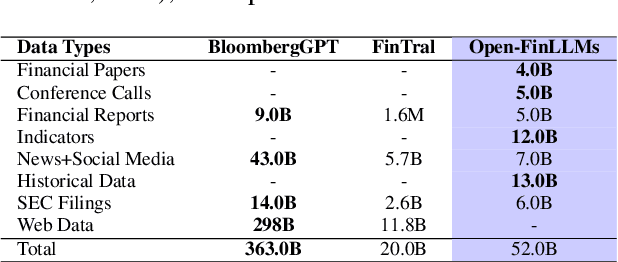
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
DocMath-Eval: Evaluating Numerical Reasoning Capabilities of LLMs in Understanding Long Documents with Tabular Data
Nov 16, 2023
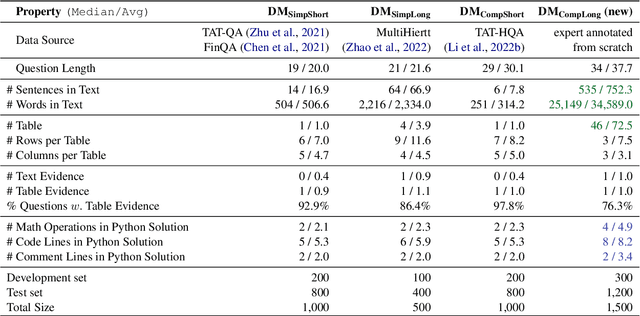

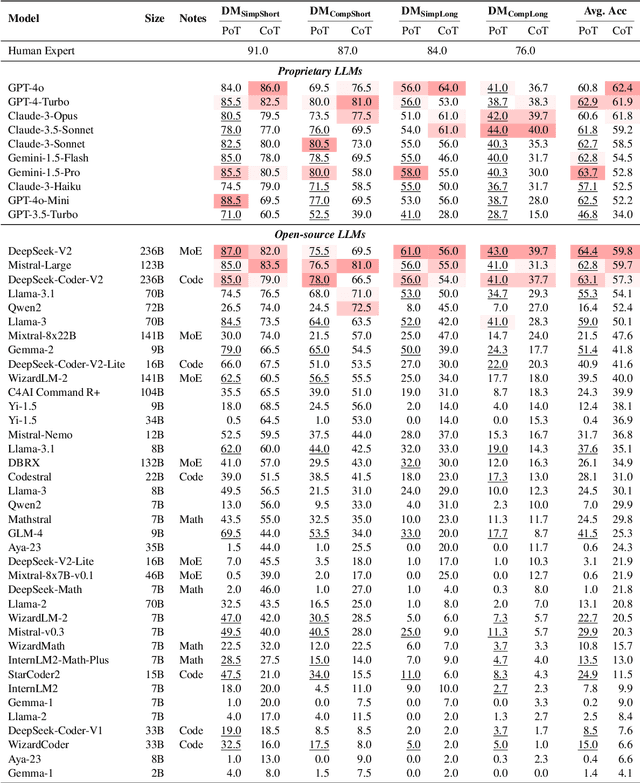
Recent LLMs have demonstrated remarkable performance in solving exam-like math word problems. However, the degree to which these numerical reasoning skills are effective in real-world scenarios, particularly in expert domains, is still largely unexplored. This paper introduces DocMath-Eval, a comprehensive benchmark specifically designed to evaluate the numerical reasoning and problem-solving capabilities of LLMs in the context of understanding and analyzing financial documents containing both text and tables. We evaluate a wide spectrum of 19 LLMs, including those specialized in coding and finance. We also incorporate different prompting strategies (i.e., Chain-of-Thoughts and Program-of-Thoughts) to comprehensively assess the capabilities and limitations of existing LLMs in DocMath-Eval. We found that, although the current best-performing system (i.e., GPT-4), can perform well on simple problems such as calculating the rate of increase in a financial metric within a short document context, it significantly lags behind human experts in more complex problems grounded in longer contexts. We believe DocMath-Eval can be used as a valuable benchmark to evaluate LLMs' capabilities to solve challenging numerical reasoning problems in expert domains. We will release the benchmark and code at https://github.com/yale-nlp/DocMath-Eval.
KnowledgeMath: Knowledge-Intensive Math Word Problem Solving in Finance Domains
Nov 16, 2023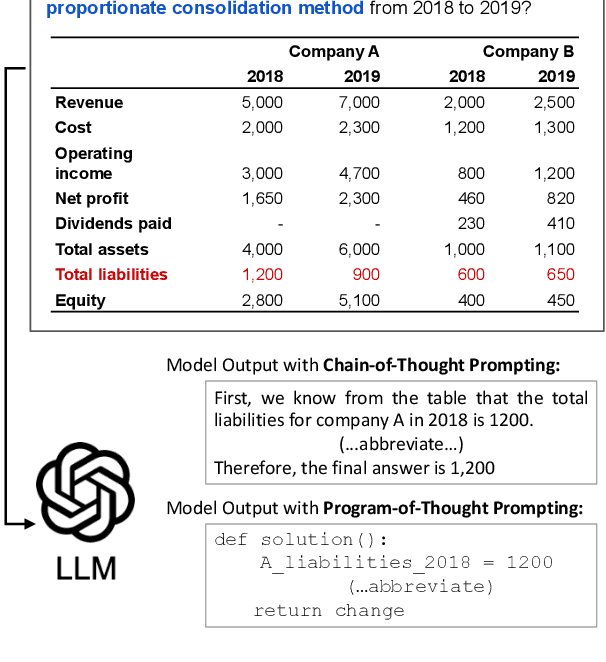
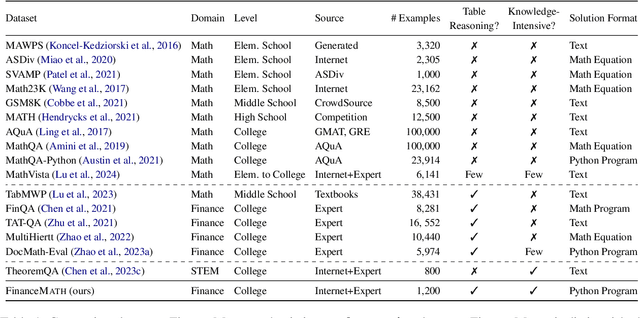

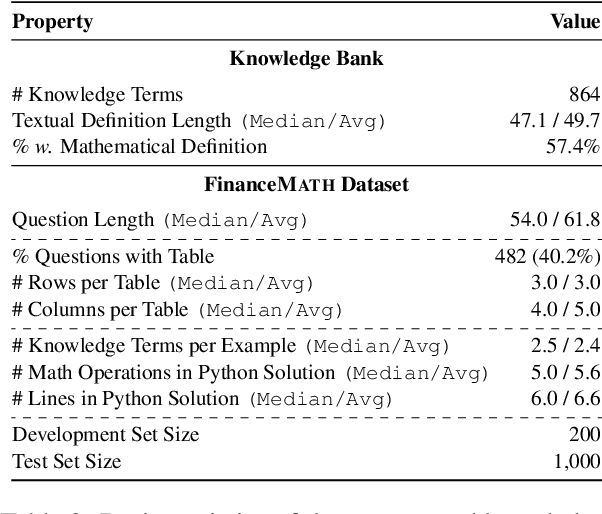
We introduce KnowledgeMath, a novel benchmark designed to evaluate LLMs' capabilities in applying financial knowledge to solve complex math word problems. Compared to prior works, this study features three core advancements. First, KnowledgeMath includes 1,259 problems with a hybrid of textual and tabular content and require college-level knowledge in the finance domain for effective resolution. Second, we provide expert-annotated, detailed solution references in Python program format, ensuring a high-quality benchmark for LLM assessment. Finally, we evaluate a wide spectrum of 14 LLMs with different prompting strategies like Chain-of-Thoughts and Program-of-Thoughts. The current best-performing system (i.e., GPT-4 with Program-of-Thoughts) achieves only 45.4% accuracy, leaving substantial room for improvement. While knowledge-augmented LLMs can improve the performance (e.g., from 23.9% to 32.0% for GPT-3.5), it is still significantly lower the estimated human expert performance of 94%. We believe that KnowledgeMath can facilitate future research on domain-specific knowledge retrieval and augmentation into the math word problem-solving process. We will release the benchmark and code at https://github.com/yale-nlp/KnowledgeMath.