 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCo: A One-Stop Shop for Model Collaboration Research
Jan 29, 2026Advancing beyond single monolithic language models (LMs), recent research increasingly recognizes the importance of model collaboration, where multiple LMs collaborate, compose, and complement each other. Existing research on this topic has mostly been disparate and disconnected, from different research communities, and lacks rigorous comparison. To consolidate existing research and establish model collaboration as a school of thought, we present MoCo: a one-stop Python library of executing, benchmarking, and comparing model collaboration algorithms at scale. MoCo features 26 model collaboration methods, spanning diverse levels of cross-model information exchange such as routing, text, logit, and model parameters. MoCo integrates 25 evaluation datasets spanning reasoning, QA, code, safety, and more, while users could flexibly bring their own data. Extensive experiments with MoCo demonstrate that most collaboration strategies outperform models without collaboration in 61.0% of (model, data) settings on average, with the most effective methods outperforming by up to 25.8%. We further analyze the scaling of model collaboration strategies, the training/inference efficiency of diverse methods, highlight that the collaborative system solves problems where single LMs struggle, and discuss future work in model collaboration, all made possible by MoCo. We envision MoCo as a valuable toolkit to facilitate and turbocharge the quest for an open, modular, decentralized, and collaborative AI future.
SPARTA ALIGNMENT: Collectively Aligning Multiple Language Models through Combat
Jun 05, 2025We propose SPARTA ALIGNMENT, an algorithm to collectively align multiple LLMs through competition and combat. To complement a single model's lack of diversity in generation and biases in evaluation, multiple LLMs form a "sparta tribe" to compete against each other in fulfilling instructions while serving as judges for the competition of others. For each iteration, one instruction and two models are selected for a duel, the other models evaluate the two responses, and their evaluation scores are aggregated through a adapted elo-ranking based reputation system, where winners/losers of combat gain/lose weight in evaluating others. The peer-evaluated combat results then become preference pairs where the winning response is preferred over the losing one, and all models learn from these preferences at the end of each iteration. SPARTA ALIGNMENT enables the self-evolution of multiple LLMs in an iterative and collective competition process. Extensive experiments demonstrate that SPARTA ALIGNMENT outperforms initial models and 4 self-alignment baselines across 10 out of 12 tasks and datasets with 7.0% average improvement. Further analysis reveals that SPARTA ALIGNMENT generalizes more effectively to unseen tasks and leverages the expertise diversity of participating models to produce more logical, direct and informative outputs.
ProtPainter: Draw or Drag Protein via Topology-guided Diffusion
Apr 19, 2025Recent advances in protein backbone generation have achieved promising results under structural, functional, or physical constraints. However, existing methods lack the flexibility for precise topology control, limiting navigation of the backbone space. We present ProtPainter, a diffusion-based approach for generating protein backbones conditioned on 3D curves. ProtPainter follows a two-stage process: curve-based sketching and sketch-guided backbone generation. For the first stage, we propose CurveEncoder, which predicts secondary structure annotations from a curve to parametrize sketch generation. For the second stage, the sketch guides the generative process in Denoising Diffusion Probabilistic Modeling (DDPM) to generate backbones. During this process, we further introduce a fusion scheduling scheme, Helix-Gating, to control the scaling factors. To evaluate, we propose the first benchmark for topology-conditioned protein generation, introducing Protein Restoration Task and a new metric, self-consistency Topology Fitness (scTF). Experiments demonstrate ProtPainter's ability to generate topology-fit (scTF > 0.8) and designable (scTM > 0.5) backbones, with drawing and dragging tasks showcasing its flexibility and versatility.
FinDVer: Explainable Claim Verification over Long and Hybrid-Content Financial Documents
Nov 08, 2024
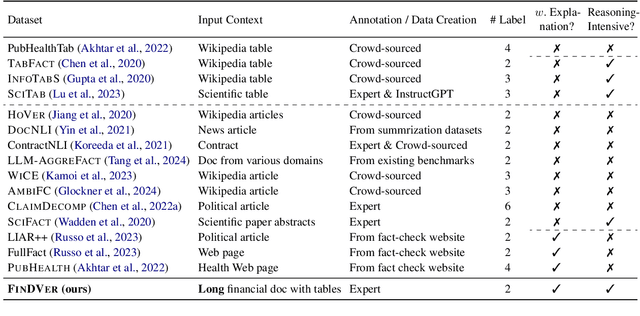
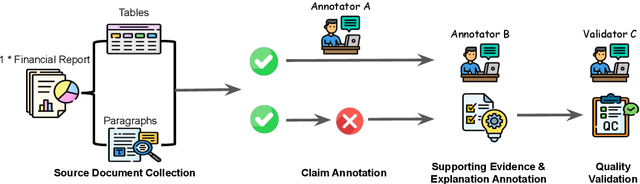
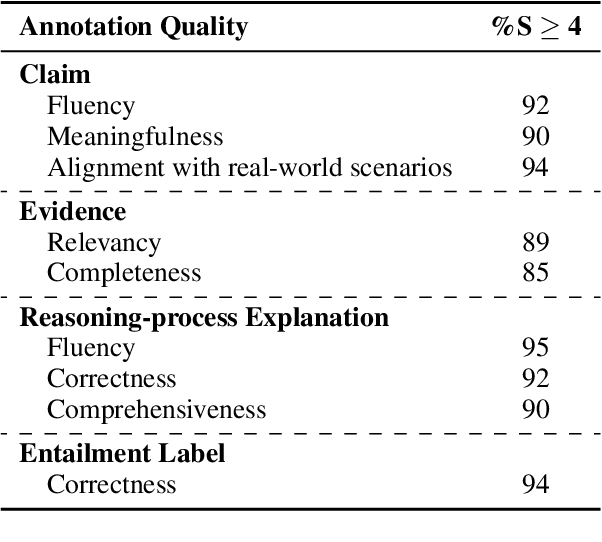
We introduce FinDVer, a comprehensive benchmark specifically designed to evaluate the explainable claim verification capabilities of LLMs in the context of understanding and analyzing long, hybrid-content financial documents. FinDVer contains 2,400 expert-annotated examples, divided into three subsets: information extraction, numerical reasoning, and knowledge-intensive reasoning, each addressing common scenarios encountered in real-world financial contexts. We assess a broad spectrum of LLMs under long-context and RAG settings. Our results show that even the current best-performing system, GPT-4o, still lags behind human experts. We further provide in-depth analysis on long-context and RAG setting, Chain-of-Thought reasoning, and model reasoning errors, offering insights to drive future advancements. We believe that FinDVer can serve as a valuable benchmark for evaluating LLMs in claim verification over complex, expert-domain documents.