 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROMA: Recursive Open Meta-Agent Framework for Long-Horizon Multi-Agent Systems
Feb 02, 2026Current agentic frameworks underperform on long-horizon tasks. As reasoning depth increases, sequential orchestration becomes brittle, context windows impose hard limits that degrade performance, and opaque execution traces make failures difficult to localize or debug. We introduce ROMA (Recursive Open Meta-Agents), a domain-agnostic framework that addresses these limitations through recursive task decomposition and structured aggregation. ROMA decomposes goals into dependency-aware subtask trees that can be executed in parallel, while aggregation compresses and validates intermediate results to control context growth. Our framework standardizes agent construction around four modular roles --Atomizer (which decides whether a task should be decomposed), Planner, Executor, and Aggregator -- which cleanly separate orchestration from model selection and enable transparent, hierarchical execution traces. This design supports heterogeneous multi-agent systems that mix models and tools according to cost, latency, and capability. To adapt ROMA to specific tasks without fine-tuning, we further introduce GEPA$+$, an improved Genetic-Pareto prompt proposer that searches over prompts within ROMA's component hierarchy while preserving interface contracts. We show that ROMA, combined with GEPA+, delivers leading system-level performance on reasoning and long-form generation benchmarks. On SEAL-0, which evaluates reasoning over conflicting web evidence, ROMA instantiated with GLM-4.6 improves accuracy by 9.9\% over Kimi-Researcher. On EQ-Bench, a long-form writing benchmark, ROMA enables DeepSeek-V3 to match the performance of leading closed-source models such as Claude Sonnet 4.5. Our results demonstrate that recursive, modular agent architectures can scale reasoning depth while remaining interpretable, flexible, and model-agnostic.
AbGen: Evaluating Large Language Models in Ablation Study Design and Evaluation for Scientific Research
Jul 17, 2025We introduce AbGen, the first benchmark designed to evaluate the capabilities of LLMs in designing ablation studies for scientific research. AbGen consists of 1,500 expert-annotated examples derived from 807 NLP papers. In this benchmark, LLMs are tasked with generating detailed ablation study designs for a specified module or process based on the given research context. Our evaluation of leading LLMs, such as DeepSeek-R1-0528 and o4-mini, highlights a significant performance gap between these models and human experts in terms of the importance, faithfulness, and soundness of the ablation study designs. Moreover, we demonstrate that current automated evaluation methods are not reliable for our task, as they show a significant discrepancy when compared to human assessment. To better investigate this, we develop AbGen-Eval, a meta-evaluation benchmark designed to assess the reliability of commonly used automated evaluation systems in measuring LLM performance on our task. We investigate various LLM-as-Judge systems on AbGen-Eval, providing insights for future research on developing more effective and reliable LLM-based evaluation systems for complex scientific tasks.
MMVU: Measuring Expert-Level Multi-Discipline Video Understanding
Jan 21, 2025



We introduce MMVU, a comprehensive expert-level, multi-discipline benchmark for evaluating foundation models in video understanding. MMVU includes 3,000 expert-annotated questions spanning 27 subjects across four core disciplines: Science, Healthcare, Humanities & Social Sciences, and Engineering. Compared to prior benchmarks, MMVU features three key advancements. First, it challenges models to apply domain-specific knowledge and perform expert-level reasoning to analyze specialized-domain videos, moving beyond the basic visual perception typically assessed in current video benchmarks. Second, each example is annotated by human experts from scratch. We implement strict data quality controls to ensure the high quality of the dataset. Finally, each example is enriched with expert-annotated reasoning rationals and relevant domain knowledge, facilitating in-depth analysis. We conduct an extensive evaluation of 32 frontier multimodal foundation models on MMVU. The latest System-2-capable models, o1 and Gemini 2.0 Flash Thinking, achieve the highest performance among the tested models. However, they still fall short of matching human expertise. Through in-depth error analyses and case studies, we offer actionable insights for future advancements in expert-level, knowledge-intensive video understanding for specialized domains.
FinDVer: Explainable Claim Verification over Long and Hybrid-Content Financial Documents
Nov 08, 2024
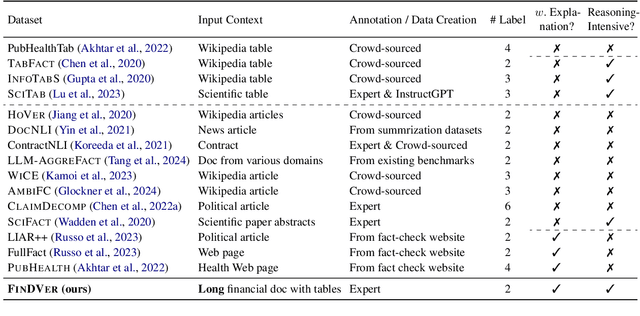
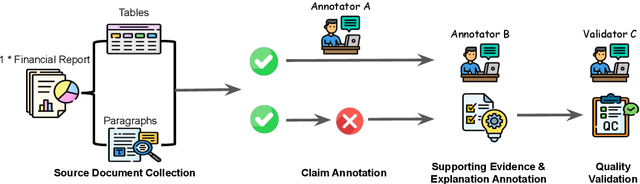
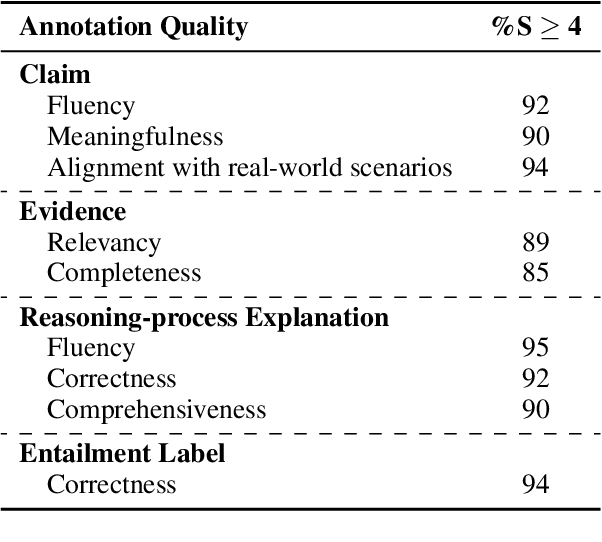
We introduce FinDVer, a comprehensive benchmark specifically designed to evaluate the explainable claim verification capabilities of LLMs in the context of understanding and analyzing long, hybrid-content financial documents. FinDVer contains 2,400 expert-annotated examples, divided into three subsets: information extraction, numerical reasoning, and knowledge-intensive reasoning, each addressing common scenarios encountered in real-world financial contexts. We assess a broad spectrum of LLMs under long-context and RAG settings. Our results show that even the current best-performing system, GPT-4o, still lags behind human experts. We further provide in-depth analysis on long-context and RAG setting, Chain-of-Thought reasoning, and model reasoning errors, offering insights to drive future advancements. We believe that FinDVer can serve as a valuable benchmark for evaluating LLMs in claim verification over complex, expert-domain documents.