 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Universal Time Series Foundation Models Rest on a Category Error
Feb 05, 2026This position paper argues that the pursuit of "Universal Foundation Models for Time Series" rests on a fundamental category error, mistaking a structural Container for a semantic Modality. We contend that because time series hold incompatible generative processes (e.g., finance vs. fluid dynamics), monolithic models degenerate into expensive "Generic Filters" that fail to generalize under distributional drift. To address this, we introduce the "Autoregressive Blindness Bound," a theoretical limit proving that history-only models cannot predict intervention-driven regime shifts. We advocate replacing universality with a Causal Control Agent paradigm, where an agent leverages external context to orchestrate a hierarchy of specialized solvers, from frozen domain experts to lightweight Just-in-Time adaptors. We conclude by calling for a shift in benchmarks from "Zero-Shot Accuracy" to "Drift Adaptation Speed" to prioritize robust, control-theoretic systems.
AbGen: Evaluating Large Language Models in Ablation Study Design and Evaluation for Scientific Research
Jul 17, 2025We introduce AbGen, the first benchmark designed to evaluate the capabilities of LLMs in designing ablation studies for scientific research. AbGen consists of 1,500 expert-annotated examples derived from 807 NLP papers. In this benchmark, LLMs are tasked with generating detailed ablation study designs for a specified module or process based on the given research context. Our evaluation of leading LLMs, such as DeepSeek-R1-0528 and o4-mini, highlights a significant performance gap between these models and human experts in terms of the importance, faithfulness, and soundness of the ablation study designs. Moreover, we demonstrate that current automated evaluation methods are not reliable for our task, as they show a significant discrepancy when compared to human assessment. To better investigate this, we develop AbGen-Eval, a meta-evaluation benchmark designed to assess the reliability of commonly used automated evaluation systems in measuring LLM performance on our task. We investigate various LLM-as-Judge systems on AbGen-Eval, providing insights for future research on developing more effective and reliable LLM-based evaluation systems for complex scientific tasks.
Can LLMs Identify Critical Limitations within Scientific Research? A Systematic Evaluation on AI Research Papers
Jul 03, 2025Peer review is fundamental to scientific research, but the growing volume of publications has intensified the challenges of this expertise-intensive process. While LLMs show promise in various scientific tasks, their potential to assist with peer review, particularly in identifying paper limitations, remains understudied. We first present a comprehensive taxonomy of limitation types in scientific research, with a focus on AI. Guided by this taxonomy, for studying limitations, we present LimitGen, the first comprehensive benchmark for evaluating LLMs' capability to support early-stage feedback and complement human peer review. Our benchmark consists of two subsets: LimitGen-Syn, a synthetic dataset carefully created through controlled perturbations of high-quality papers, and LimitGen-Human, a collection of real human-written limitations. To improve the ability of LLM systems to identify limitations, we augment them with literature retrieval, which is essential for grounding identifying limitations in prior scientific findings. Our approach enhances the capabilities of LLM systems to generate limitations in research papers, enabling them to provide more concrete and constructive feedback.
Mixture of Low Rank Adaptation with Partial Parameter Sharing for Time Series Forecasting
May 23, 2025Multi-task forecasting has become the standard approach for time-series forecasting (TSF). However, we show that it suffers from an Expressiveness Bottleneck, where predictions at different time steps share the same representation, leading to unavoidable errors even with optimal representations. To address this issue, we propose a two-stage framework: first, pre-train a foundation model for one-step-ahead prediction; then, adapt it using step-specific LoRA modules.This design enables the foundation model to handle any number of forecast steps while avoiding the expressiveness bottleneck. We further introduce the Mixture-of-LoRA (MoLA) model, which employs adaptively weighted LoRA experts to achieve partial parameter sharing across steps. This approach enhances both efficiency and forecasting performance by exploiting interdependencies between forecast steps. Experiments show that MoLA significantly improves model expressiveness and outperforms state-of-the-art time-series forecasting methods. Code is available at https://anonymous.4open.science/r/MoLA-BC92.
Solve-Detect-Verify: Inference-Time Scaling with Flexible Generative Verifier
May 17, 2025
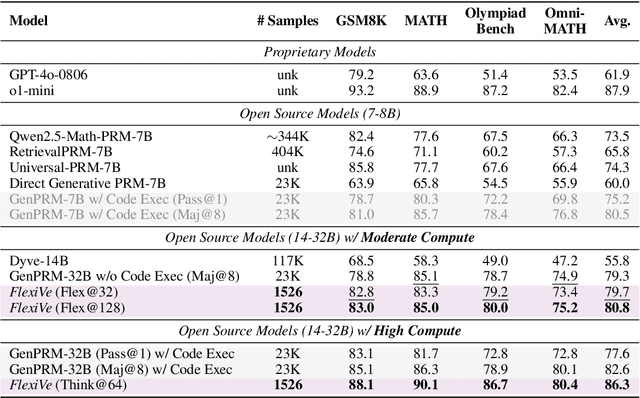
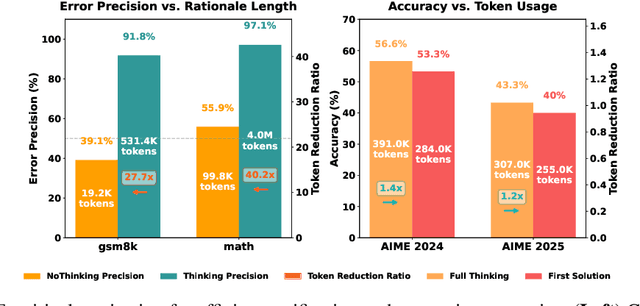
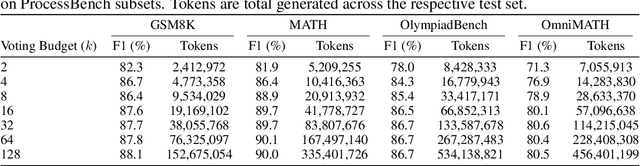
Large Language Model (LLM) reasoning for complex tasks inherently involves a trade-off between solution accuracy and computational efficiency. The subsequent step of verification, while intended to improve performance, further complicates this landscape by introducing its own challenging trade-off: sophisticated Generative Reward Models (GenRMs) can be computationally prohibitive if naively integrated with LLMs at test-time, while simpler, faster methods may lack reliability. To overcome these challenges, we introduce FlexiVe, a novel generative verifier that flexibly balances computational resources between rapid, reliable fast thinking and meticulous slow thinking using a Flexible Allocation of Verification Budget strategy. We further propose the Solve-Detect-Verify pipeline, an efficient inference-time scaling framework that intelligently integrates FlexiVe, proactively identifying solution completion points to trigger targeted verification and provide focused solver feedback. Experiments show FlexiVe achieves superior accuracy in pinpointing errors within reasoning traces on ProcessBench. Furthermore, on challenging mathematical reasoning benchmarks (AIME 2024, AIME 2025, and CNMO), our full approach outperforms baselines like self-consistency in reasoning accuracy and inference efficiency. Our system offers a scalable and effective solution to enhance LLM reasoning at test time.
MMVU: Measuring Expert-Level Multi-Discipline Video Understanding
Jan 21, 2025



We introduce MMVU, a comprehensive expert-level, multi-discipline benchmark for evaluating foundation models in video understanding. MMVU includes 3,000 expert-annotated questions spanning 27 subjects across four core disciplines: Science, Healthcare, Humanities & Social Sciences, and Engineering. Compared to prior benchmarks, MMVU features three key advancements. First, it challenges models to apply domain-specific knowledge and perform expert-level reasoning to analyze specialized-domain videos, moving beyond the basic visual perception typically assessed in current video benchmarks. Second, each example is annotated by human experts from scratch. We implement strict data quality controls to ensure the high quality of the dataset. Finally, each example is enriched with expert-annotated reasoning rationals and relevant domain knowledge, facilitating in-depth analysis. We conduct an extensive evaluation of 32 frontier multimodal foundation models on MMVU. The latest System-2-capable models, o1 and Gemini 2.0 Flash Thinking, achieve the highest performance among the tested models. However, they still fall short of matching human expertise. Through in-depth error analyses and case studies, we offer actionable insights for future advancements in expert-level, knowledge-intensive video understanding for specialized domains.
Beyond Trend and Periodicity: Guiding Time Series Forecasting with Textual Cues
May 22, 2024This work introduces a novel Text-Guided Time Series Forecasting (TGTSF) task. By integrating textual cues, such as channel descriptions and dynamic news, TGTSF addresses the critical limitations of traditional methods that rely purely on historical data. To support this task, we propose TGForecaster, a robust baseline model that fuses textual cues and time series data using cross-attention mechanisms. We then present four meticulously curated benchmark datasets to validate the proposed framework, ranging from simple periodic data to complex, event-driven fluctuations. Our comprehensive evaluations demonstrate that TGForecaster consistently achieves state-of-the-art performance, highlighting the transformative potential of incorporating textual information into time series forecasting. This work not only pioneers a novel forecasting task but also establishes a new benchmark for future research, driving advancements in multimodal data integration for time series models.
Multi-Patch Prediction: Adapting LLMs for Time Series Representation Learning
Feb 07, 2024In this study, we present aLLM4TS, an innovative framework that adapts Large Language Models (LLMs) for time-series representation learning. Central to our approach is that we reconceive time-series forecasting as a self-supervised, multi-patch prediction task, which, compared to traditional mask-and-reconstruction methods, captures temporal dynamics in patch representations more effectively. Our strategy encompasses two-stage training: (i). a causal continual pre-training phase on various time-series datasets, anchored on next patch prediction, effectively syncing LLM capabilities with the intricacies of time-series data; (ii). fine-tuning for multi-patch prediction in the targeted time-series context. A distinctive element of our framework is the patch-wise decoding layer, which departs from previous methods reliant on sequence-level decoding. Such a design directly transposes individual patches into temporal sequences, thereby significantly bolstering the model's proficiency in mastering temporal patch-based representations. aLLM4TS demonstrates superior performance in several downstream tasks, proving its effectiveness in deriving temporal representations with enhanced transferability and marking a pivotal advancement in the adaptation of LLMs for time-series analysis.
Preliminary Study on Incremental Learning for Large Language Model-based Recommender Systems
Dec 25, 2023Adapting Large Language Models for recommendation (LLM4Rec)has garnered substantial attention and demonstrated promising results. However, the challenges of practically deploying LLM4Rec are largely unexplored, with the need for incremental adaptation to evolving user preferences being a critical concern. Nevertheless, the suitability of traditional incremental learning within LLM4Rec remains ambiguous, given the unique characteristics of LLMs. In this study, we empirically evaluate the commonly used incremental learning strategies (full retraining and fine-tuning) for LLM4Rec. Surprisingly, neither approach leads to evident improvements in LLM4Rec's performance. Rather than directly dismissing the role of incremental learning, we ascribe this lack of anticipated performance improvement to the mismatch between the LLM4Recarchitecture and incremental learning: LLM4Rec employs a single adaptation module for learning recommendation, hampering its ability to simultaneously capture long-term and short-term user preferences in the incremental learning context. To validate this speculation, we develop a Long- and Short-term Adaptation-aware Tuning (LSAT) framework for LLM4Rec incremental learning. Instead of relying on a single adaptation module, LSAT utilizes two adaptation modules to separately learn long-term and short-term user preferences. Empirical results demonstrate that LSAT could enhance performance, validating our speculation.
FITS: Modeling Time Series with $10k$ Parameters
Jul 06, 2023In this paper, we introduce FITS, a lightweight yet powerful model for time series analysis. Unlike existing models that directly process raw time-domain data, FITS operates on the principle that time series can be manipulated through interpolation in the complex frequency domain. By discarding high-frequency components with negligible impact on time series data, FITS achieves performance comparable to state-of-the-art models for time series forecasting and anomaly detection tasks, while having a remarkably compact size of only approximately $10k$ parameters. Such a lightweight model can be easily trained and deployed in edge devices, creating opportunities for various applications. The anonymous code repo is available in: \url{https://anonymous.4open.science/r/FITS}