 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixRea: Benchmarking Explicit-Implicit Reasoning in Large Language Models
May 19, 2026Large language models (LLMs) are increasingly integrated into high-stakes decision-making. Inspired by the theory of \emph{inattentional blindness} in human cognition, we investigate whether LLMs, trained on human-preferred corpora that embed attentional biases, exhibit a similar limitation: \emph{failing to attend to subtle yet important contextual cues under explicit task instructions}. To evaluate this, we introduce the task of \textbf{explicit-implicit reasoning} and present \textbf{MixRea}, a benchmark of 2,246 multiple-choice questions across 9 reasoning types with varying distributions of explicit and implicit information. Evaluation of 21 advanced LLMs shows that even the best-performing reasoning model (Gemini 2.5 Pro) achieves only 42.8\% consistency, revealing widespread inattentional blindness. To mitigate this, we propose \textbf{Potential Relation Completion Prompting (PRCP)}, a prompting method that improves reasoning by recovering overlooked causal relations. Further analysis shows that this limitation persists across diverse multi-source reasoning tasks, highlighting the need for more cognitively aligned models.
TimeCatcher: A Variational Framework for Volatility-Aware Forecasting of Non-Stationary Time Series
Jan 28, 2026Recent lightweight MLP-based models have achieved strong performance in time series forecasting by capturing stable trends and seasonal patterns. However, their effectiveness hinges on an implicit assumption of local stationarity assumption, making them prone to errors in long-term forecasting of highly non-stationary series, especially when abrupt fluctuations occur, a common challenge in domains like web traffic monitoring. To overcome this limitation, we propose TimeCatcher, a novel Volatility-Aware Variational Forecasting framework. TimeCatcher extends linear architectures with a variational encoder to capture latent dynamic patterns hidden in historical data and a volatility-aware enhancement mechanism to detect and amplify significant local variations. Experiments on nine real-world datasets from traffic, financial, energy, and weather domains show that TimeCatcher consistently outperforms state-of-the-art baselines, with particularly large improvements in long-term forecasting scenarios characterized by high volatility and sudden fluctuations. Our code is available at https://github.com/ColaPrinceCHEN/TimeCatcher.
MuseTalk: Real-Time High Quality Lip Synchronization with Latent Space Inpainting
Oct 14, 2024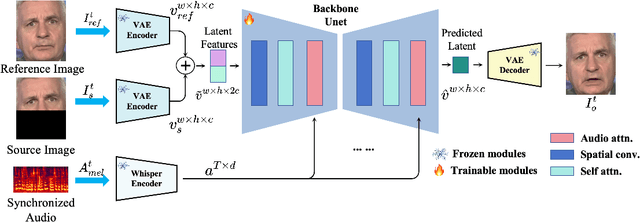
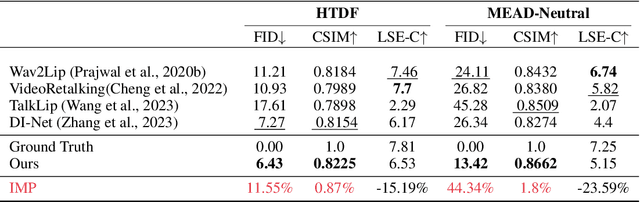
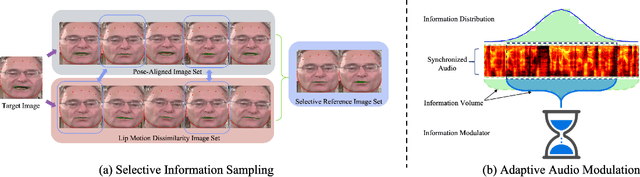

Achieving high-resolution, identity consistency, and accurate lip-speech synchronization in face visual dubbing presents significant challenges, particularly for real-time applications like live video streaming. We propose MuseTalk, which generates lip-sync targets in a latent space encoded by a Variational Autoencoder, enabling high-fidelity talking face video generation with efficient inference. Specifically, we project the occluded lower half of the face image and itself as an reference into a low-dimensional latent space and use a multi-scale U-Net to fuse audio and visual features at various levels. We further propose a novel sampling strategy during training, which selects reference images with head poses closely matching the target, allowing the model to focus on precise lip movement by filtering out redundant information. Additionally, we analyze the mechanism of lip-sync loss and reveal its relationship with input information volume. Extensive experiments show that MuseTalk consistently outperforms recent state-of-the-art methods in visual fidelity and achieves comparable lip-sync accuracy. As MuseTalk supports the online generation of face at 256x256 at more than 30 FPS with negligible starting latency, it paves the way for real-time applications.
DeepFIB: Self-Imputation for Time Series Anomaly Detection
Dec 12, 2021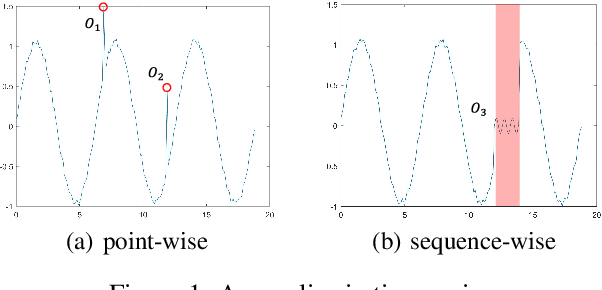
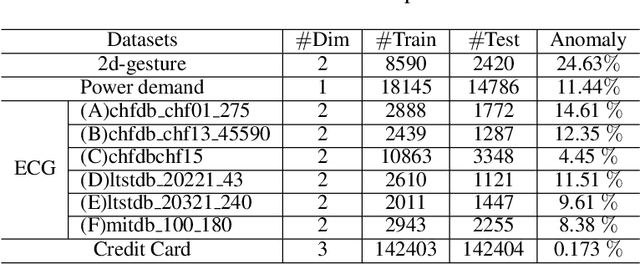
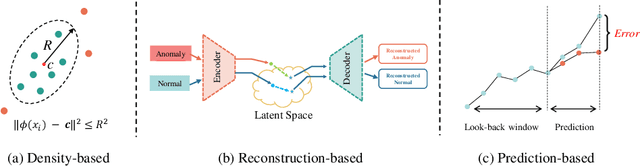
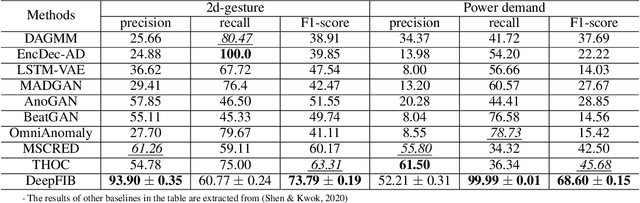
Time series (TS) anomaly detection (AD) plays an essential role in various applications, e.g., fraud detection in finance and healthcare monitoring. Due to the inherently unpredictable and highly varied nature of anomalies and the lack of anomaly labels in historical data, the AD problem is typically formulated as an unsupervised learning problem. The performance of existing solutions is often not satisfactory, especially in data-scarce scenarios. To tackle this problem, we propose a novel self-supervised learning technique for AD in time series, namely \emph{DeepFIB}. We model the problem as a \emph{Fill In the Blank} game by masking some elements in the TS and imputing them with the rest. Considering the two common anomaly shapes (point- or sequence-outliers) in TS data, we implement two masking strategies with many self-generated training samples. The corresponding self-imputation networks can extract more robust temporal relations than existing AD solutions and effectively facilitate identifying the two types of anomalies. For continuous outliers, we also propose an anomaly localization algorithm that dramatically reduces AD errors. Experiments on various real-world TS datasets demonstrate that DeepFIB outperforms state-of-the-art methods by a large margin, achieving up to $65.2\%$ relative improvement in F1-score.
Learning Skeletal Graph Neural Networks for Hard 3D Pose Estimation
Aug 17, 2021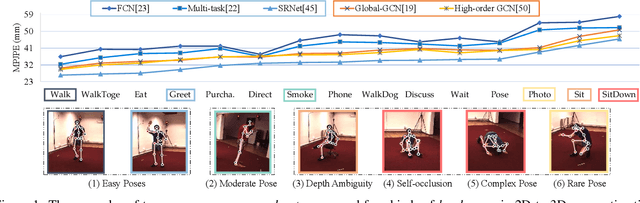
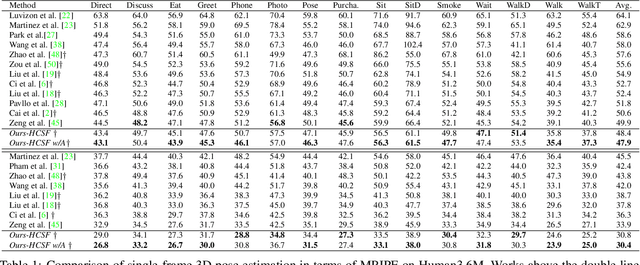
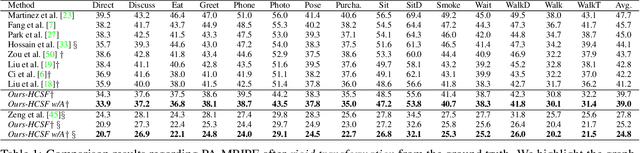
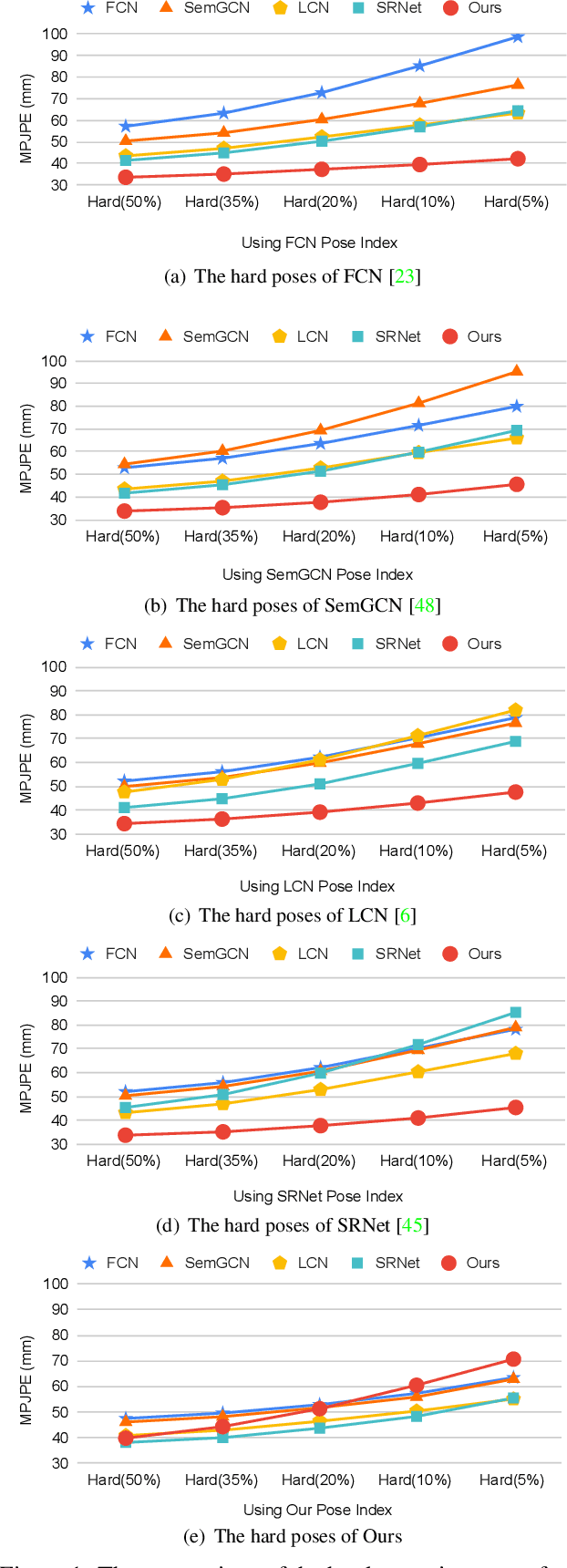
Various deep learning techniques have been proposed to solve the single-view 2D-to-3D pose estimation problem. While the average prediction accuracy has been improved significantly over the years, the performance on hard poses with depth ambiguity, self-occlusion, and complex or rare poses is still far from satisfactory. In this work, we target these hard poses and present a novel skeletal GNN learning solution. To be specific, we propose a hop-aware hierarchical channel-squeezing fusion layer to effectively extract relevant information from neighboring nodes while suppressing undesired noises in GNN learning. In addition, we propose a temporal-aware dynamic graph construction procedure that is robust and effective for 3D pose estimation. Experimental results on the Human3.6M dataset show that our solution achieves 10.3\% average prediction accuracy improvement and greatly improves on hard poses over state-of-the-art techniques. We further apply the proposed technique on the skeleton-based action recognition task and also achieve state-of-the-art performance. Our code is available at https://github.com/ailingzengzzz/Skeletal-GNN.
Information Bottleneck Approach to Spatial Attention Learning
Aug 07, 2021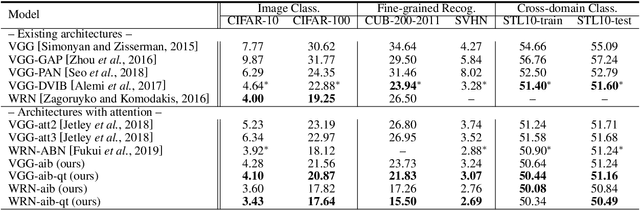

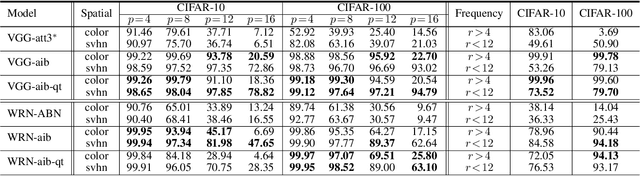
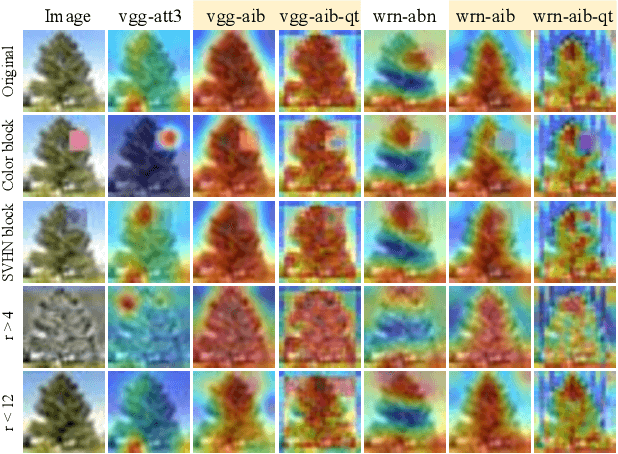
The selective visual attention mechanism in the human visual system (HVS) restricts the amount of information to reach visual awareness for perceiving natural scenes, allowing near real-time information processing with limited computational capacity [Koch and Ullman, 1987]. This kind of selectivity acts as an 'Information Bottleneck (IB)', which seeks a trade-off between information compression and predictive accuracy. However, such information constraints are rarely explored in the attention mechanism for deep neural networks (DNNs). In this paper, we propose an IB-inspired spatial attention module for DNN structures built for visual recognition. The module takes as input an intermediate representation of the input image, and outputs a variational 2D attention map that minimizes the mutual information (MI) between the attention-modulated representation and the input, while maximizing the MI between the attention-modulated representation and the task label. To further restrict the information bypassed by the attention map, we quantize the continuous attention scores to a set of learnable anchor values during training. Extensive experiments show that the proposed IB-inspired spatial attention mechanism can yield attention maps that neatly highlight the regions of interest while suppressing backgrounds, and bootstrap standard DNN structures for visual recognition tasks (e.g., image classification, fine-grained recognition, cross-domain classification). The attention maps are interpretable for the decision making of the DNNs as verified in the experiments. Our code is available at https://github.com/ashleylqx/AIB.git.
Time Series is a Special Sequence: Forecasting with Sample Convolution and Interaction
Jun 17, 2021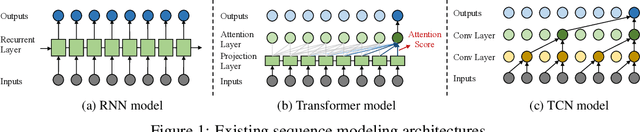

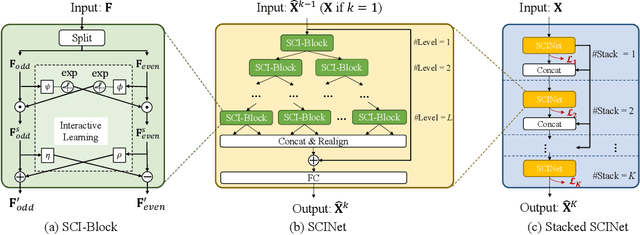
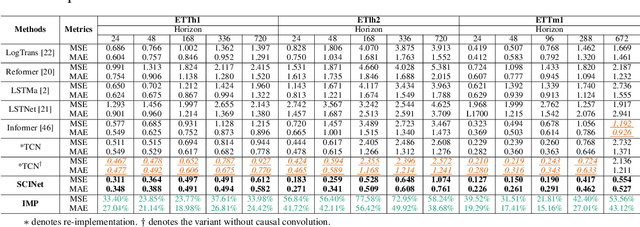
Time series is a special type of sequence data, a set of observations collected at even intervals of time and ordered chronologically. Existing deep learning techniques use generic sequence models (e.g., recurrent neural network, Transformer model, or temporal convolutional network) for time series analysis, which ignore some of its unique properties. For example, the downsampling of time series data often preserves most of the information in the data, while this is not true for general sequence data such as text sequence and DNA sequence. Motivated by the above, in this paper, we propose a novel neural network architecture and apply it for the time series forecasting problem, wherein we conduct sample convolution and interaction at multiple resolutions for temporal modeling. The proposed architecture, namelySCINet, facilitates extracting features with enhanced predictability. Experimental results show that SCINet achieves significant prediction accuracy improvement over existing solutions across various real-world time series forecasting datasets. In particular, it can achieve high fore-casting accuracy for those temporal-spatial datasets without using sophisticated spatial modeling techniques. Our codes and data are presented in the supplemental material.
Hop-Aware Dimension Optimization for Graph Neural Networks
May 30, 2021
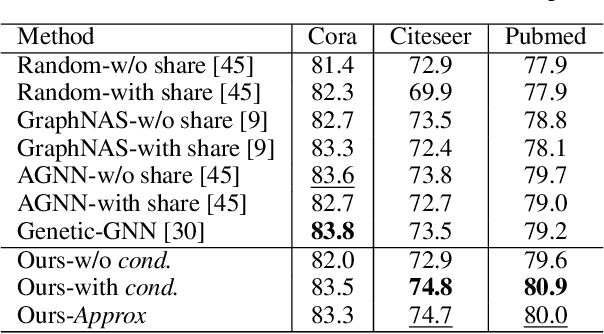
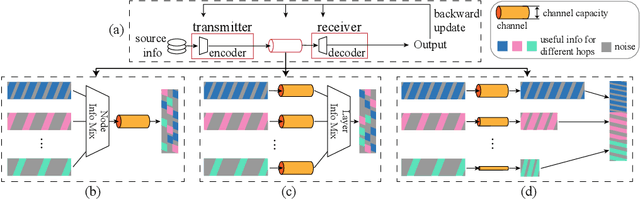
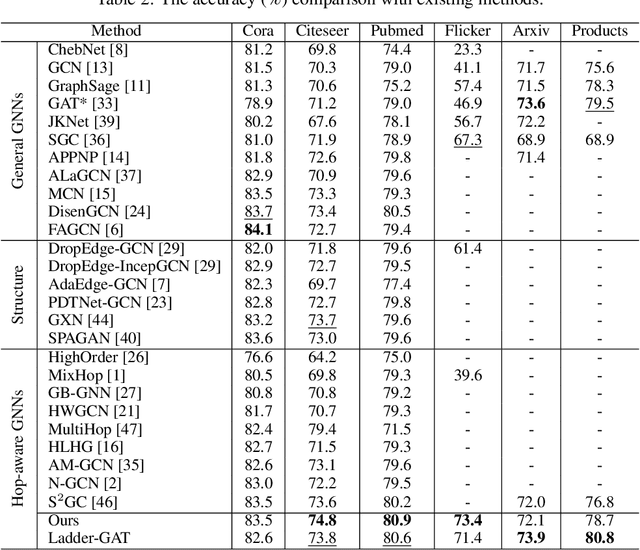
In Graph Neural Networks (GNNs), the embedding of each node is obtained by aggregating information with its direct and indirect neighbors. As the messages passed among nodes contain both information and noise, the critical issue in GNN representation learning is how to retrieve information effectively while suppressing noise. Generally speaking, interactions with distant nodes usually introduce more noise for a particular node than those with close nodes. However, in most existing works, the messages being passed among nodes are mingled together, which is inefficient from a communication perspective. Mixing the information from clean sources (low-order neighbors) and noisy sources (high-order neighbors) makes discriminative feature extraction challenging. Motivated by the above, we propose a simple yet effective ladder-style GNN architecture, namely LADDER-GNN. Specifically, we separate messages from different hops and assign different dimensions for them before concatenating them to obtain the node representation. Such disentangled representations facilitate extracting information from messages passed from different hops, and their corresponding dimensions are determined with a reinforcement learning-based neural architecture search strategy. The resulted hop-aware representations generally contain more dimensions for low-order neighbors and fewer dimensions for high-order neighbors, leading to a ladder-style aggregation scheme. We verify the proposed LADDER-GNN on several semi-supervised node classification datasets. Experimental results show that the proposed simple hop-aware representation learning solution can achieve state-of-the-art performance on most datasets.
T-WaveNet: Tree-Structured Wavelet Neural Network for Sensor-Based Time Series Analysis
Dec 10, 2020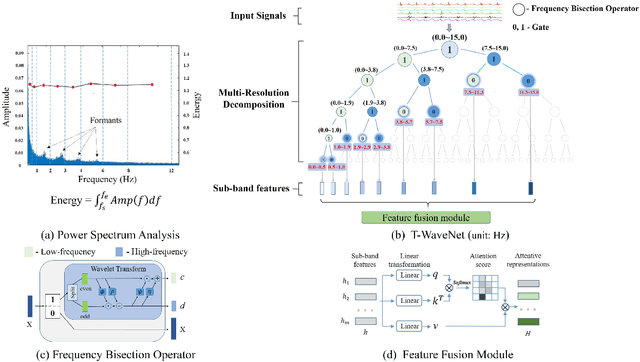

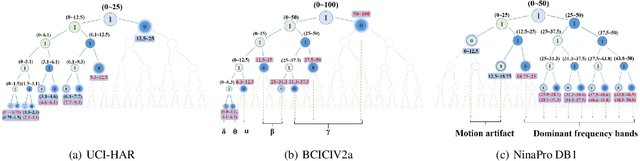
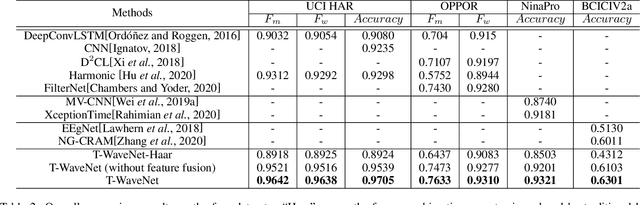
Sensor-based time series analysis is an essential task for applications such as activity recognition and brain-computer interface. Recently, features extracted with deep neural networks (DNNs) are shown to be more effective than conventional hand-crafted ones. However, most of these solutions rely solely on the network to extract application-specific information carried in the sensor data. Motivated by the fact that usually a small subset of the frequency components carries the primary information for sensor data, we propose a novel tree-structured wavelet neural network for sensor data analysis, namely \emph{T-WaveNet}. To be specific, with T-WaveNet, we first conduct a power spectrum analysis for the sensor data and decompose the input signal into various frequency subbands accordingly. Then, we construct a tree-structured network, and each node on the tree (corresponding to a frequency subband) is built with an invertible neural network (INN) based wavelet transform. By doing so, T-WaveNet provides more effective representation for sensor information than existing DNN-based techniques, and it achieves state-of-the-art performance on various sensor datasets, including UCI-HAR for activity recognition, OPPORTUNITY for gesture recognition, BCICIV2a for intention recognition, and NinaPro DB1 for muscular movement recognition.
SRNet: Improving Generalization in 3D Human Pose Estimation with a Split-and-Recombine Approach
Jul 18, 2020
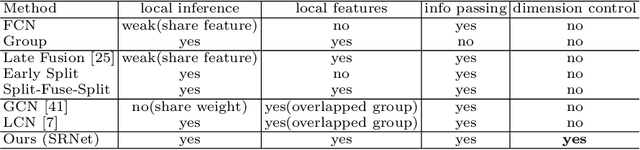

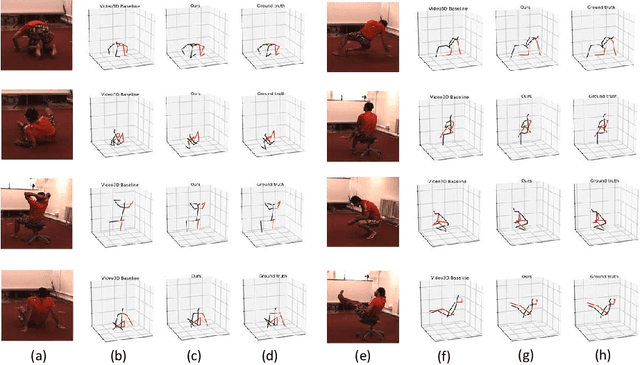
Human poses that are rare or unseen in a training set are challenging for a network to predict. Similar to the long-tailed distribution problem in visual recognition, the small number of examples for such poses limits the ability of networks to model them. Interestingly, local pose distributions suffer less from the long-tail problem, i.e., local joint configurations within a rare pose may appear within other poses in the training set, making them less rare. We propose to take advantage of this fact for better generalization to rare and unseen poses. To be specific, our method splits the body into local regions and processes them in separate network branches, utilizing the property that a joint position depends mainly on the joints within its local body region. Global coherence is maintained by recombining the global context from the rest of the body into each branch as a low-dimensional vector. With the reduced dimensionality of less relevant body areas, the training set distribution within network branches more closely reflects the statistics of local poses instead of global body poses, without sacrificing information important for joint inference. The proposed split-and-recombine approach, called SRNet, can be easily adapted to both single-image and temporal models, and it leads to appreciable improvements in the prediction of rare and unseen poses.