 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dubbing: End-to-End Auto-Audiobook System with Text-to-Timbre and Context-Aware Instruct-TTS
Sep 19, 2025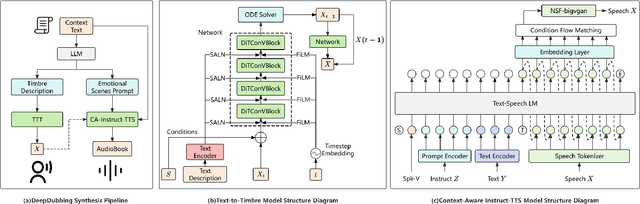


The pipeline for multi-participant audiobook production primarily consists of three stages: script analysis, character voice timbre selection, and speech synthesis. Among these, script analysis can be automated with high accuracy using NLP models, whereas character voice timbre selection still relies on manual effort. Speech synthesis uses either manual dubbing or text-to-speech (TTS). While TTS boosts efficiency, it struggles with emotional expression, intonation control, and contextual scene adaptation. To address these challenges, we propose DeepDubbing, an end-to-end automated system for multi-participant audiobook production. The system comprises two main components: a Text-to-Timbre (TTT) model and a Context-Aware Instruct-TTS (CA-Instruct-TTS) model. The TTT model generates role-specific timbre embeddings conditioned on text descriptions. The CA-Instruct-TTS model synthesizes expressive speech by analyzing contextual dialogue and incorporating fine-grained emotional instructions. This system enables the automated generation of multi-participant audiobooks with both timbre-matched character voices and emotionally expressive narration, offering a novel solution for audiobook production.
MuseTalk: Real-Time High Quality Lip Synchronization with Latent Space Inpainting
Oct 14, 2024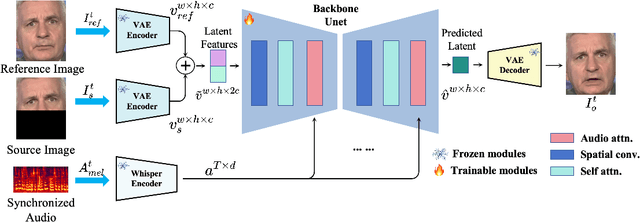
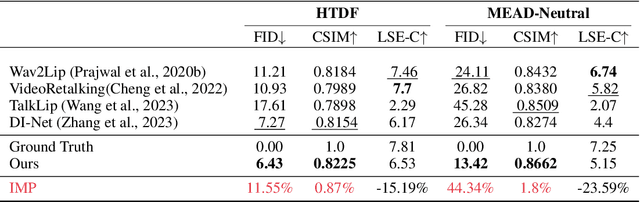
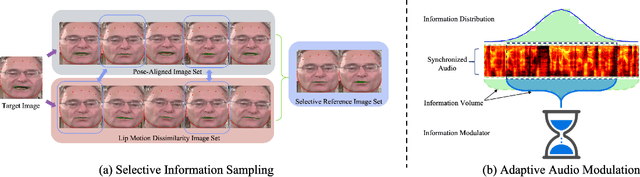

Achieving high-resolution, identity consistency, and accurate lip-speech synchronization in face visual dubbing presents significant challenges, particularly for real-time applications like live video streaming. We propose MuseTalk, which generates lip-sync targets in a latent space encoded by a Variational Autoencoder, enabling high-fidelity talking face video generation with efficient inference. Specifically, we project the occluded lower half of the face image and itself as an reference into a low-dimensional latent space and use a multi-scale U-Net to fuse audio and visual features at various levels. We further propose a novel sampling strategy during training, which selects reference images with head poses closely matching the target, allowing the model to focus on precise lip movement by filtering out redundant information. Additionally, we analyze the mechanism of lip-sync loss and reveal its relationship with input information volume. Extensive experiments show that MuseTalk consistently outperforms recent state-of-the-art methods in visual fidelity and achieves comparable lip-sync accuracy. As MuseTalk supports the online generation of face at 256x256 at more than 30 FPS with negligible starting latency, it paves the way for real-time applications.
MBTFNet: Multi-Band Temporal-Frequency Neural Network For Singing Voice Enhancement
Oct 06, 2023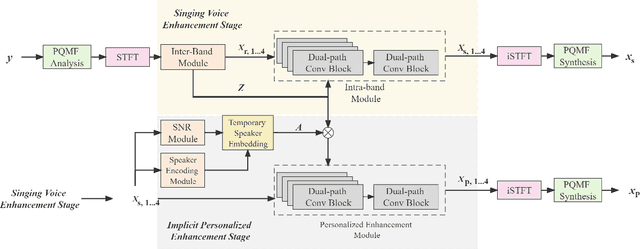
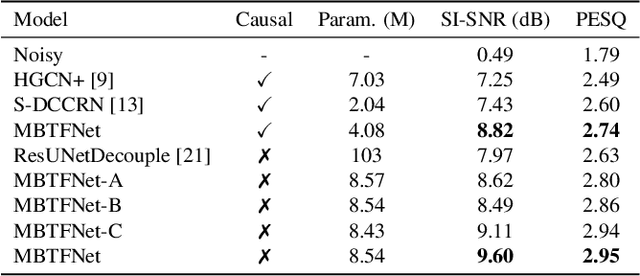
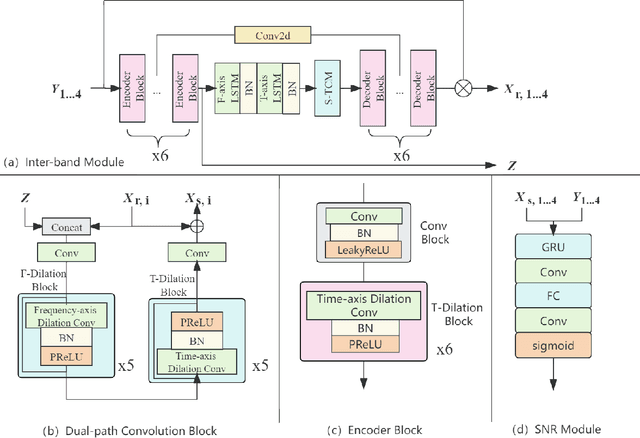
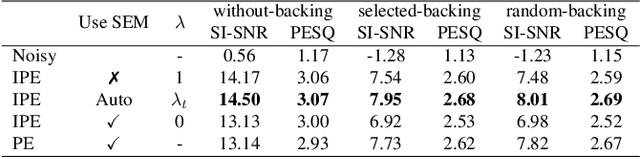
A typical neural speech enhancement (SE) approach mainly handles speech and noise mixtures, which is not optimal for singing voice enhancement scenarios. Music source separation (MSS) models treat vocals and various accompaniment components equally, which may reduce performance compared to the model that only considers vocal enhancement. In this paper, we propose a novel multi-band temporal-frequency neural network (MBTFNet) for singing voice enhancement, which particularly removes background music, noise and even backing vocals from singing recordings. MBTFNet combines inter and intra-band modeling for better processing of full-band signals. Dual-path modeling are introduced to expand the receptive field of the model. We propose an implicit personalized enhancement (IPE) stage based on signal-to-noise ratio (SNR) estimation, which further improves the performance of MBTFNet. Experiments show that our proposed model significantly outperforms several state-of-the-art SE and MSS models.
KaraTuner: Towards end to end natural pitch correction for singing voice in karaoke
Oct 18, 2021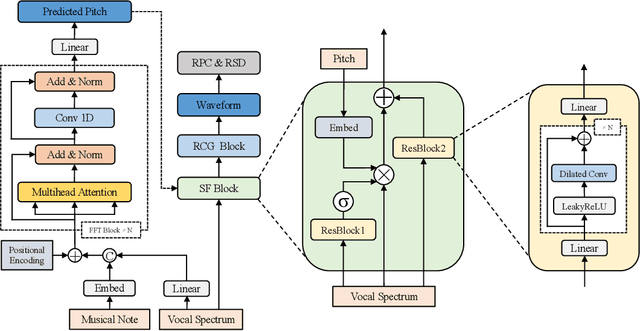

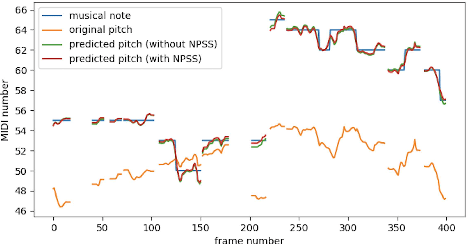
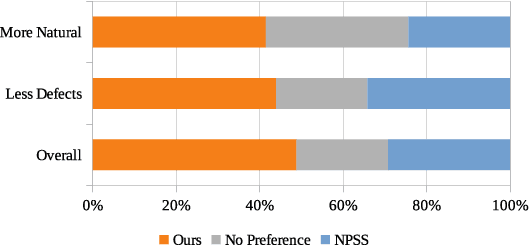
An automatic pitch correction system typically includes several stages, such as pitch extraction, deviation estimation, pitch shift processing, and cross-fade smoothing. However, designing these components with strategies often requires domain expertise and they are likely to fail on corner cases. In this paper, we present KaraTuner, an end-to-end neural architecture that predicts pitch curve and resynthesizes the singing voice directly from the tuned pitch and vocal spectrum extracted from the original recordings. Several vital technical points have been introduced in KaraTuner to ensure pitch accuracy, pitch naturalness, timbre consistency, and sound quality. A feed-forward Transformer is employed in the pitch predictor to capture long-term dependencies in the vocal spectrum and musical note. We also develop a pitch-controllable vocoder base on a novel source-filter block and the Fre-GAN architecture. KaraTuner obtains a higher preference than the rule-based pitch correction approach through A/B tests, and perceptual experiments show that the proposed vocoder achieves significant advantages in timbre consistency and sound quality compared with the parametric WORLD vocoder and phase vocoder.