 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantEval: A Benchmark for Financial Quantitative Tasks in Large Language Models
Jan 13, 2026Large Language Models (LLMs) have shown strong capabilities across many domains, yet their evaluation in financial quantitative tasks remains fragmented and mostly limited to knowledge-centric question answering. We introduce QuantEval, a benchmark that evaluates LLMs across three essential dimensions of quantitative finance: knowledge-based QA, quantitative mathematical reasoning, and quantitative strategy coding. Unlike prior financial benchmarks, QuantEval integrates a CTA-style backtesting framework that executes model-generated strategies and evaluates them using financial performance metrics, enabling a more realistic assessment of quantitative coding ability. We evaluate some state-of-the-art open-source and proprietary LLMs and observe substantial gaps to human experts, particularly in reasoning and strategy coding. Finally, we conduct large-scale supervised fine-tuning and reinforcement learning experiments on domain-aligned data, demonstrating consistent improvements. We hope QuantEval will facilitate research on LLMs' quantitative finance capabilities and accelerate their practical adoption in real-world trading workflows. We additionally release the full deterministic backtesting configuration (asset universe, cost model, and metric definitions) to ensure strict reproducibility.
How Order-Sensitive Are LLMs? OrderProbe for Deterministic Structural Reconstruction
Jan 13, 2026Large language models (LLMs) excel at semantic understanding, yet their ability to reconstruct internal structure from scrambled inputs remains underexplored. Sentence-level restoration is ill-posed for automated evaluation because multiple valid word orders often exist. We introduce OrderProbe, a deterministic benchmark for structural reconstruction using fixed four-character expressions in Chinese, Japanese, and Korean, which have a unique canonical order and thus support exact-match scoring. We further propose a diagnostic framework that evaluates models beyond recovery accuracy, including semantic fidelity, logical validity, consistency, robustness sensitivity, and information density. Experiments on twelve widely used LLMs show that structural reconstruction remains difficult even for frontier systems: zero-shot recovery frequently falls below 35%. We also observe a consistent dissociation between semantic recall and structural planning, suggesting that structural robustness is not an automatic byproduct of semantic competence.
MuseTalk: Real-Time High Quality Lip Synchronization with Latent Space Inpainting
Oct 14, 2024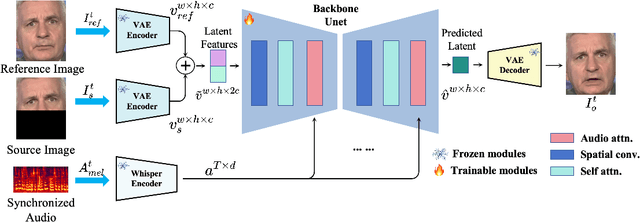
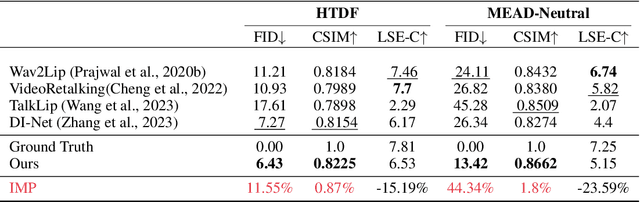
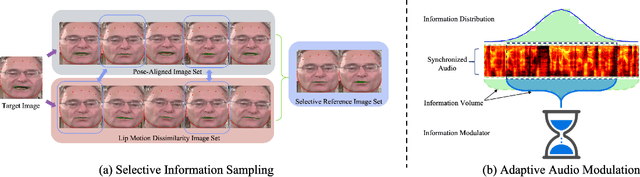

Achieving high-resolution, identity consistency, and accurate lip-speech synchronization in face visual dubbing presents significant challenges, particularly for real-time applications like live video streaming. We propose MuseTalk, which generates lip-sync targets in a latent space encoded by a Variational Autoencoder, enabling high-fidelity talking face video generation with efficient inference. Specifically, we project the occluded lower half of the face image and itself as an reference into a low-dimensional latent space and use a multi-scale U-Net to fuse audio and visual features at various levels. We further propose a novel sampling strategy during training, which selects reference images with head poses closely matching the target, allowing the model to focus on precise lip movement by filtering out redundant information. Additionally, we analyze the mechanism of lip-sync loss and reveal its relationship with input information volume. Extensive experiments show that MuseTalk consistently outperforms recent state-of-the-art methods in visual fidelity and achieves comparable lip-sync accuracy. As MuseTalk supports the online generation of face at 256x256 at more than 30 FPS with negligible starting latency, it paves the way for real-time applications.
Image Copy-Move Forgery Detection via Deep Cross-Scale PatchMatch
Aug 08, 2023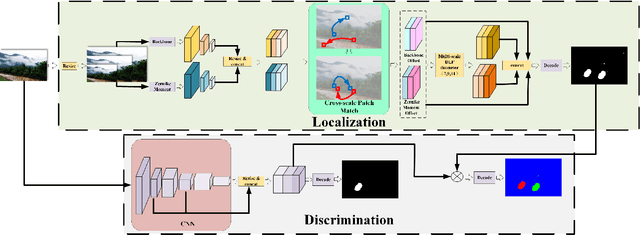
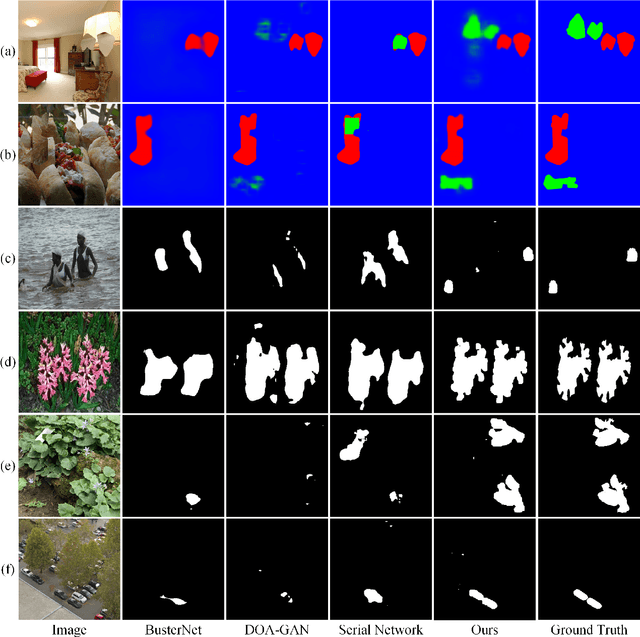
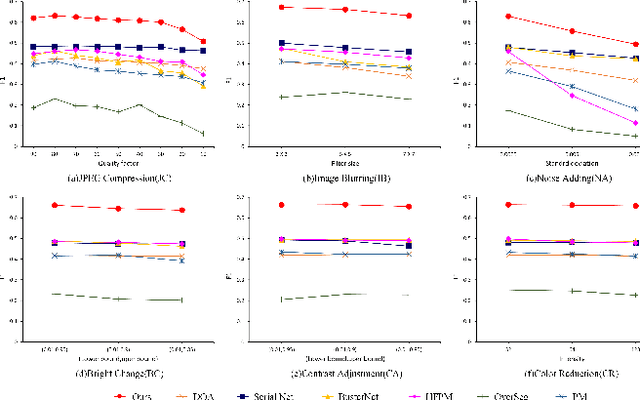
The recently developed deep algorithms achieve promising progress in the field of image copy-move forgery detection (CMFD). However, they have limited generalizability in some practical scenarios, where the copy-move objects may not appear in the training images or cloned regions are from the background. To address the above issues, in this work, we propose a novel end-to-end CMFD framework by integrating merits from both conventional and deep methods. Specifically, we design a deep cross-scale patchmatch method tailored for CMFD to localize copy-move regions. In contrast to existing deep models, our scheme aims to seek explicit and reliable point-to-point matching between source and target regions using features extracted from high-resolution scales. Further, we develop a manipulation region location branch for source/target separation. The proposed CMFD framework is completely differentiable and can be trained in an end-to-end manner. Extensive experimental results demonstrate the high generalizability of our method to different copy-move contents, and the proposed scheme achieves significantly better performance than existing approaches.