 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuseTalk: Real-Time High Quality Lip Synchronization with Latent Space Inpainting
Paper and Code
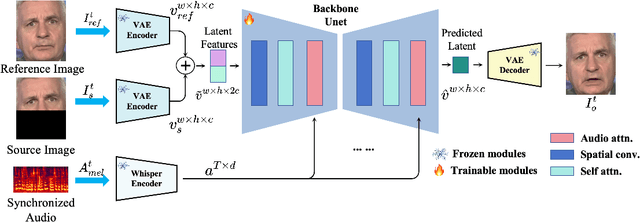
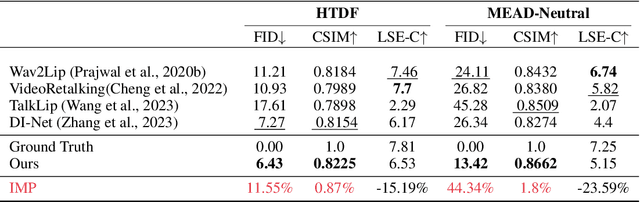
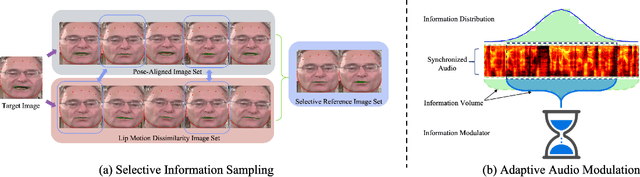

Achieving high-resolution, identity consistency, and accurate lip-speech synchronization in face visual dubbing presents significant challenges, particularly for real-time applications like live video streaming. We propose MuseTalk, which generates lip-sync targets in a latent space encoded by a Variational Autoencoder, enabling high-fidelity talking face video generation with efficient inference. Specifically, we project the occluded lower half of the face image and itself as an reference into a low-dimensional latent space and use a multi-scale U-Net to fuse audio and visual features at various levels. We further propose a novel sampling strategy during training, which selects reference images with head poses closely matching the target, allowing the model to focus on precise lip movement by filtering out redundant information. Additionally, we analyze the mechanism of lip-sync loss and reveal its relationship with input information volume. Extensive experiments show that MuseTalk consistently outperforms recent state-of-the-art methods in visual fidelity and achieves comparable lip-sync accuracy. As MuseTalk supports the online generation of face at 256x256 at more than 30 FPS with negligible starting latency, it paves the way for real-time applications.