 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuseTalk: Real-Time High Quality Lip Synchronization with Latent Space Inpainting
Oct 14, 2024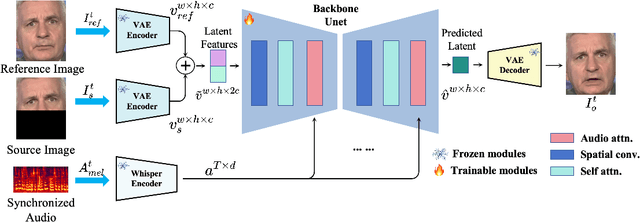
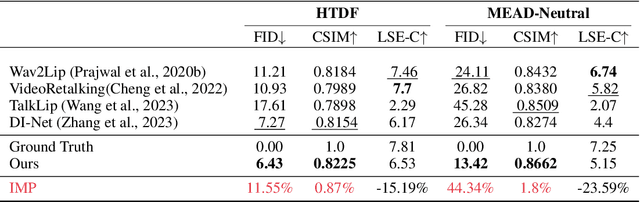
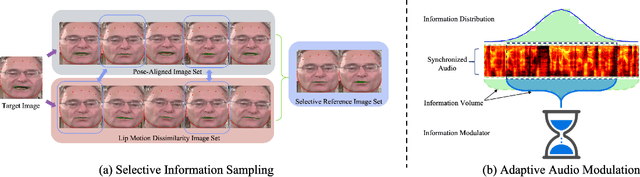

Achieving high-resolution, identity consistency, and accurate lip-speech synchronization in face visual dubbing presents significant challenges, particularly for real-time applications like live video streaming. We propose MuseTalk, which generates lip-sync targets in a latent space encoded by a Variational Autoencoder, enabling high-fidelity talking face video generation with efficient inference. Specifically, we project the occluded lower half of the face image and itself as an reference into a low-dimensional latent space and use a multi-scale U-Net to fuse audio and visual features at various levels. We further propose a novel sampling strategy during training, which selects reference images with head poses closely matching the target, allowing the model to focus on precise lip movement by filtering out redundant information. Additionally, we analyze the mechanism of lip-sync loss and reveal its relationship with input information volume. Extensive experiments show that MuseTalk consistently outperforms recent state-of-the-art methods in visual fidelity and achieves comparable lip-sync accuracy. As MuseTalk supports the online generation of face at 256x256 at more than 30 FPS with negligible starting latency, it paves the way for real-time applications.
Multitask Emotion Recognition with Incomplete Labels
Mar 10, 2020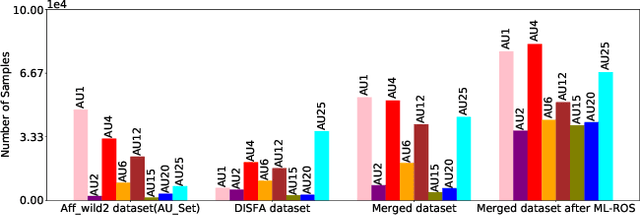
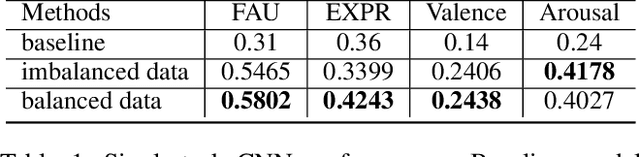
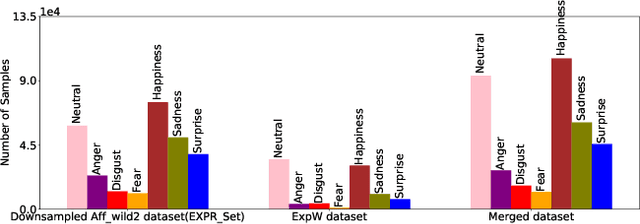
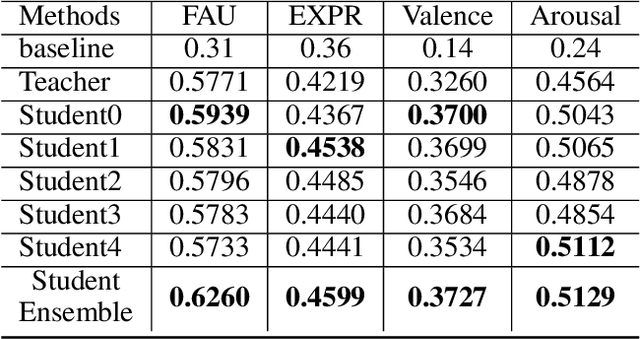
We train a unified model to perform three tasks: facial action unit detection, expression classification, and valence-arousal estimation. We address two main challenges of learning the three tasks. First, most existing datasets are highly imbalanced. Second, most existing datasets do not contain labels for all three tasks. To tackle the first challenge, we apply data balancing techniques to experimental datasets. To tackle the second challenge, we propose an algorithm for the multitask model to learn from missing (incomplete) labels. This algorithm has two steps. We first train a teacher model to perform all three tasks, where each instance is trained by the ground truth label of its corresponding task. Secondly, we refer to the outputs of the teacher model as the soft labels. We use the soft labels and the ground truth to train the student model. We find that most of the student models outperform their teacher model on all the three tasks. Finally, we use model ensembling to boost performance further on the three tasks.
GEDDnet: A Network for Gaze Estimation with Dilation and Decomposition
Jan 25, 2020
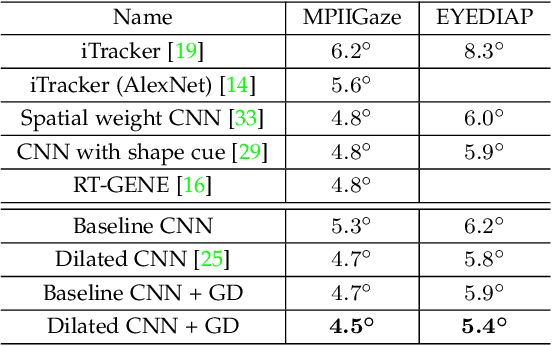
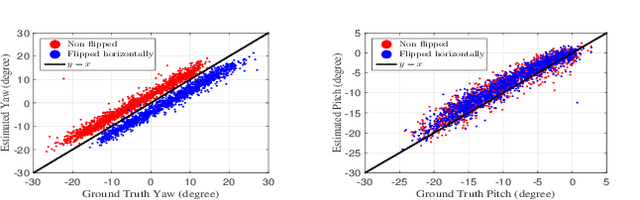
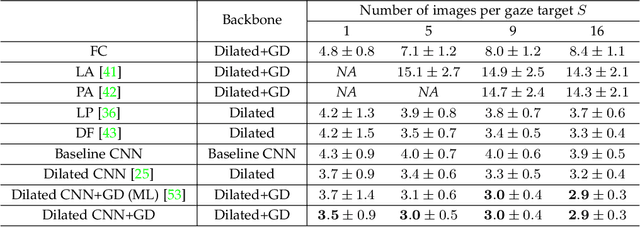
Appearance-based gaze estimation from RGB images provides relatively unconstrained gaze tracking from commonly available hardware. The accuracy of subject-independent models is limited partly by small intra-subject and large inter-subject variations in appearance, and partly by a latent subject-dependent bias. To improve estimation accuracy, we propose to use dilated-convolutions in a deep convolutional neural network to capture subtle changes in the eye images, and a novel gaze decomposition method that decomposes the gaze angle into the sum of a subject-independent gaze estimate from the image and a subject-dependent bias. To further reduce estimation error, we propose a calibration method that estimates the bias from a few images taken as the subject gazes at only a few or even just a single gaze target. This significantly redues calibration time and complexity. Experiments on four datasets, including a new dataset we collected containing large variations in head pose and face location, indicate that even without calibration the estimator already outperforms state-of-the-art methods by more than 6.3%. The proposed calibration method is robust to the location of calibration target and reduces estimation error significantly (up to 35.6%), achieving state-of-the-art performance with much less calibration data than required by previously proposed methods.
MIMAMO Net: Integrating Micro- and Macro-motion for Video Emotion Recognition
Nov 21, 2019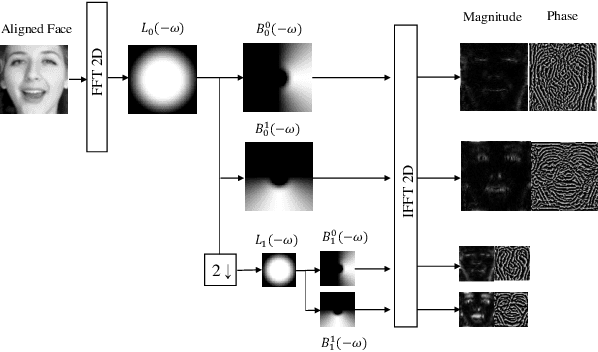
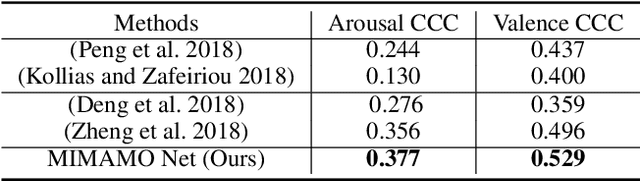
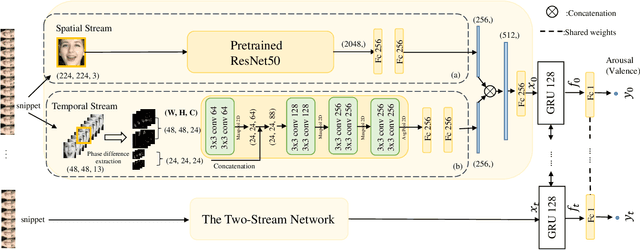
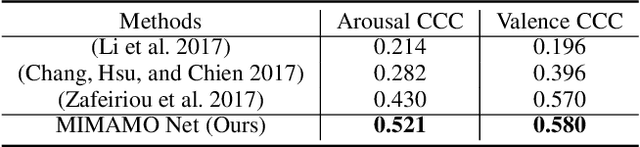
Spatial-temporal feature learning is of vital importance for video emotion recognition. Previous deep network structures often focused on macro-motion which extends over long time scales, e.g., on the order of seconds. We believe integrating structures capturing information about both micro- and macro-motion will benefit emotion prediction, because human perceive both micro- and macro-expressions. In this paper, we propose to combine micro- and macro-motion features to improve video emotion recognition with a two-stream recurrent network, named MIMAMO (Micro-Macro-Motion) Net. Specifically, smaller and shorter micro-motions are analyzed by a two-stream network, while larger and more sustained macro-motions can be well captured by a subsequent recurrent network. Assigning specific interpretations to the roles of different parts of the network enables us to make choice of parameters based on prior knowledge: choices that turn out to be optimal. One of the important innovations in our model is the use of interframe phase differences rather than optical flow as input to the temporal stream. Compared with the optical flow, phase differences require less computation and are more robust to illumination changes. Our proposed network achieves state of the art performance on two video emotion datasets, the OMG emotion dataset and the Aff-Wild dataset. The most significant gains are for arousal prediction, for which motion information is intuitively more informative. Source code is available at https://github.com/wtomin/MIMAMO-Net.
Appearance-Based Gaze Estimation via Gaze Decomposition and Single Gaze Point Calibration
May 11, 2019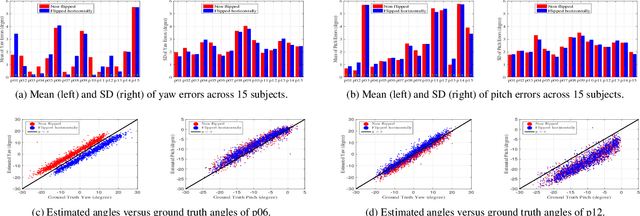
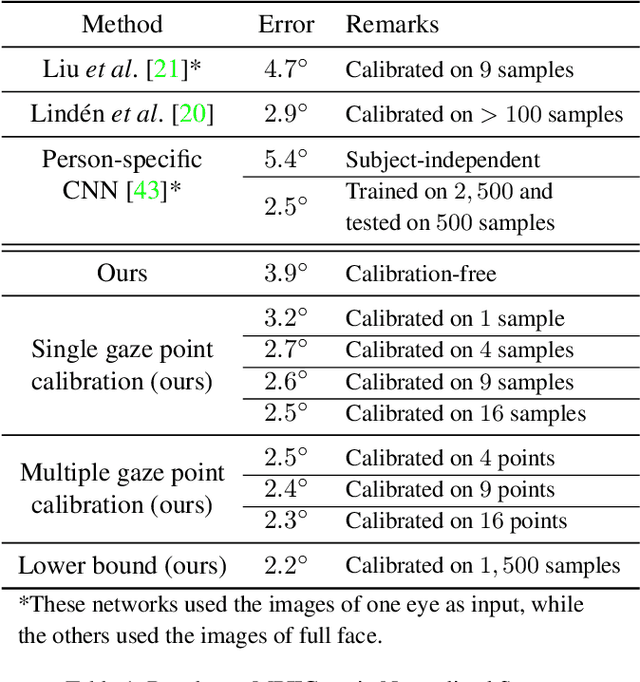
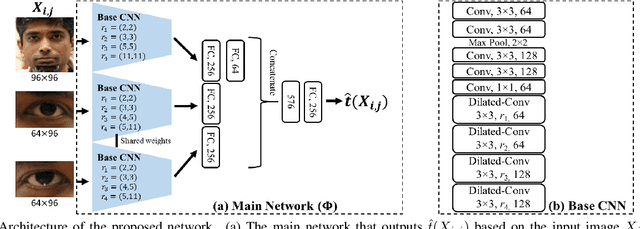
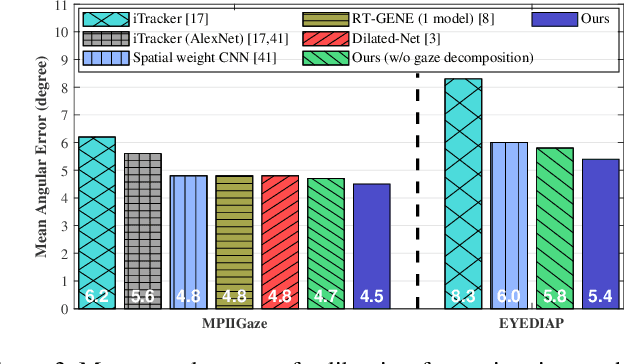
Appearance-based gaze estimation provides relatively unconstrained gaze tracking. However, subject-indepen\-dent models achieve limited accuracy partly due to individual variations. To improve estimation, we propose a novel gaze decomposition method and a single gaze point calibration method, motivated by our finding that the inter-subject squared bias exceeds the intra-subject variance for a subject-independent estimator. We decompose the gaze angle into a subject-dependent bias term and a subject-independent difference term between the gaze angle and the bias. The difference term is estimated by a deep convolutional network. For calibration-free tracking, we set the subject-dependent bias term to zero. For single gaze point calibration, we estimate the bias from a few images taken as the subject gazes at a point. Experiments on three datasets indicate that as a calibration-free estimator, the proposed method outperforms the state-of-the-art methods that use single model by up to $10.0\%$. The proposed calibration method is robust and reduces estimation error significantly (up to $35.6\%$), achieving state-of-the-art performance for appearance-based eye trackers with calibration.
Appearance-Based Gaze Estimation Using Dilated-Convolutions
Mar 18, 2019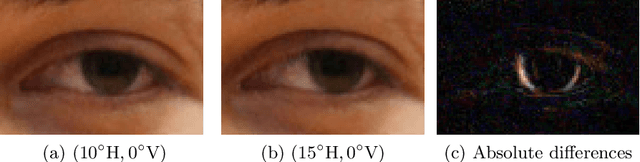
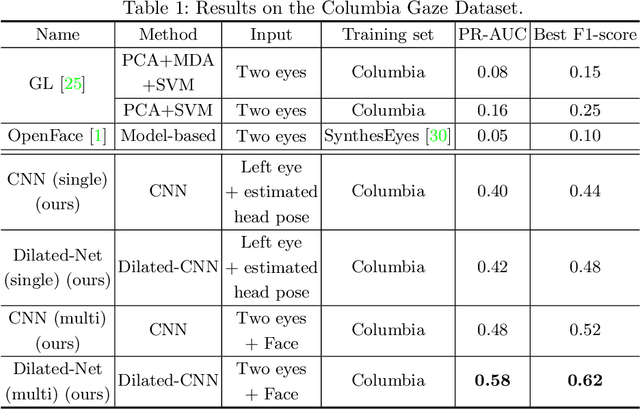
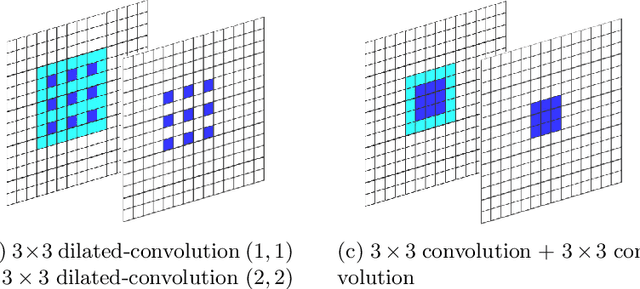

Appearance-based gaze estimation has attracted more and more attention because of its wide range of applications. The use of deep convolutional neural networks has improved the accuracy significantly. In order to improve the estimation accuracy further, we focus on extracting better features from eye images. Relatively large changes in gaze angles may result in relatively small changes in eye appearance. We argue that current architectures for gaze estimation may not be able to capture such small changes, as they apply multiple pooling layers or other downsampling layers so that the spatial resolution of the high-level layers is reduced significantly. To evaluate whether the use of features extracted at high resolution can benefit gaze estimation, we adopt dilated-convolutions to extract high-level features without reducing spatial resolution. In cross-subject experiments on the Columbia Gaze dataset for eye contact detection and the MPIIGaze dataset for 3D gaze vector regression, the resulting Dilated-Nets achieve significant (up to 20.8%) gains when compared to similar networks without dilated-convolutions. Our proposed Dilated-Net achieves state-of-the-art results on both the Columbia Gaze and the MPIIGaze datasets.