 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Facial Expression Detection in Long Videos
Apr 10, 2025Facial expression detection involves two interrelated tasks: spotting, which identifies the onset and offset of expressions, and recognition, which classifies them into emotional categories. Most existing methods treat these tasks separately using a two-step training pipelines. A spotting model first detects expression intervals. A recognition model then classifies the detected segments. However, this sequential approach leads to error propagation, inefficient feature learning, and suboptimal performance due to the lack of joint optimization of the two tasks. We propose FEDN, an end-to-end Facial Expression Detection Network that jointly optimizes spotting and recognition. Our model introduces a novel attention-based feature extraction module, incorporating segment attention and sliding window attention to improve facial feature learning. By unifying two tasks within a single network, we greatly reduce error propagation and enhance overall performance. Experiments on CASME}^2 and CASME^3 demonstrate state-of-the-art accuracy for both spotting and detection, underscoring the benefits of joint optimization for robust facial expression detection in long videos.
OAT: Object-Level Attention Transformer for Gaze Scanpath Prediction
Jul 18, 2024Visual search is important in our daily life. The efficient allocation of visual attention is critical to effectively complete visual search tasks. Prior research has predominantly modelled the spatial allocation of visual attention in images at the pixel level, e.g. using a saliency map. However, emerging evidence shows that visual attention is guided by objects rather than pixel intensities. This paper introduces the Object-level Attention Transformer (OAT), which predicts human scanpaths as they search for a target object within a cluttered scene of distractors. OAT uses an encoder-decoder architecture. The encoder captures information about the position and appearance of the objects within an image and about the target. The decoder predicts the gaze scanpath as a sequence of object fixations, by integrating output features from both the encoder and decoder. We also propose a new positional encoding that better reflects spatial relationships between objects. We evaluated OAT on the Amazon book cover dataset and a new dataset for visual search that we collected. OAT's predicted gaze scanpaths align more closely with human gaze patterns, compared to predictions by algorithms based on spatial attention on both established metrics and a novel behavioural-based metric. Our results demonstrate the generalization ability of OAT, as it accurately predicts human scanpaths for unseen layouts and target objects.
RMES: Real-Time Micro-Expression Spotting Using Phase From Riesz Pyramid
May 09, 2023Micro-expressions (MEs) are involuntary and subtle facial expressions that are thought to reveal feelings people are trying to hide. ME spotting detects the temporal intervals containing MEs in videos. Detecting such quick and subtle motions from long videos is difficult. Recent works leverage detailed facial motion representations, such as the optical flow, and deep learning models, leading to high computational complexity. To reduce computational complexity and achieve real-time operation, we propose RMES, a real-time ME spotting framework. We represent motion using phase computed by Riesz Pyramid, and feed this motion representation into a three-stream shallow CNN, which predicts the likelihood of each frame belonging to an ME. In comparison to optical flow, phase provides more localized motion estimates, which are essential for ME spotting, resulting in higher performance. Using phase also reduces the required computation of the ME spotting pipeline by 77.8%. Despite its relative simplicity and low computational complexity, our framework achieves state-of-the-art performance on two public datasets: CAS(ME)2 and SAMM Long Videos.
Integrating Holistic and Local Information to Estimate Emotional Reaction Intensity
May 09, 2023



Video-based Emotional Reaction Intensity (ERI) estimation measures the intensity of subjects' reactions to stimuli along several emotional dimensions from videos of the subject as they view the stimuli. We propose a multi-modal architecture for video-based ERI combining video and audio information. Video input is encoded spatially first, frame-by-frame, combining features encoding holistic aspects of the subjects' facial expressions and features encoding spatially localized aspects of their expressions. Input is then combined across time: from frame-to-frame using gated recurrent units (GRUs), then globally by a transformer. We handle variable video length with a regression token that accumulates information from all frames into a fixed-dimensional vector independent of video length. Audio information is handled similarly: spectral information extracted within each frame is integrated across time by a cascade of GRUs and a transformer with regression token. The video and audio regression tokens' outputs are merged by concatenation, then input to a final fully connected layer producing intensity estimates. Our architecture achieved excellent performance on the Hume-Reaction dataset in the ERI Esimation Challenge of the Fifth Competition on Affective Behavior Analysis in-the-Wild (ABAW5). The Pearson Correlation Coefficients between estimated and subject self-reported scores, averaged across all emotions, were 0.455 on the validation dataset and 0.4547 on the test dataset, well above the baselines. The transformer's self-attention mechanism enables our architecture to focus on the most critical video frames regardless of length. Ablation experiments establish the advantages of combining holistic/local features and of multi-modal integration. Code available at https://github.com/HKUST-NISL/ABAW5.
CoMoGCN: Coherent Motion Aware Trajectory Prediction with Graph Representation
May 05, 2020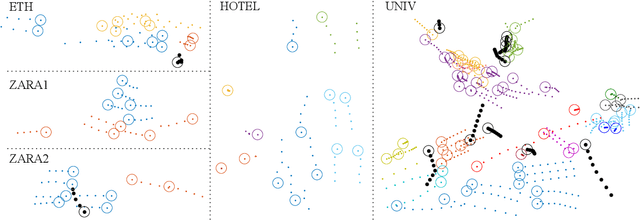
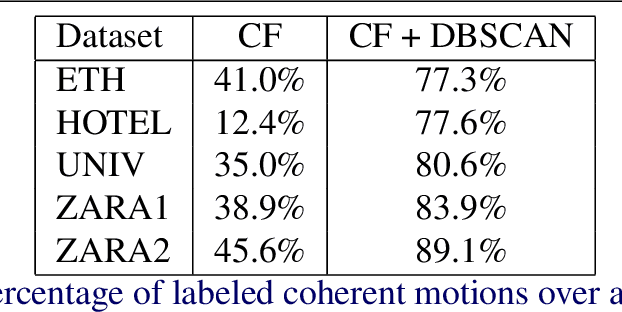
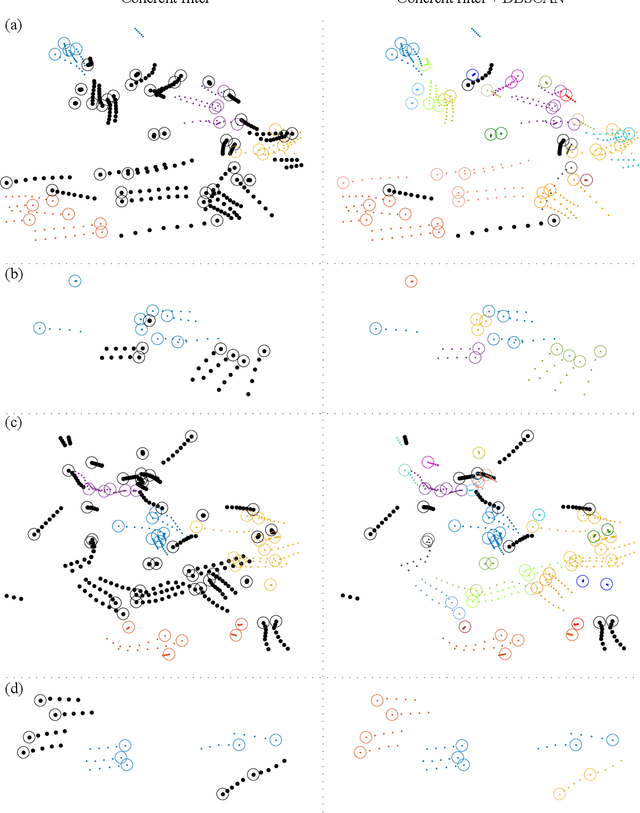
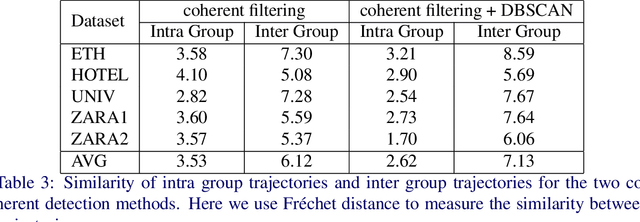
Forecasting human trajectories is critical for tasks such as robot crowd navigation and autonomous driving. Modeling social interactions is of great importance for accurate group-wise motion prediction. However, most existing methods do not consider information about coherence within the crowd, but rather only pairwise interactions. In this work, we propose a novel framework, coherent motion aware graph convolutional network (CoMoGCN), for trajectory prediction in crowded scenes with group constraints. First, we cluster pedestrian trajectories into groups according to motion coherence. Then, we use graph convolutional networks to aggregate crowd information efficiently. The CoMoGCN also takes advantage of variational autoencoders to capture the multimodal nature of the human trajectories by modeling the distribution. Our method achieves state-of-the-art performance on several different trajectory prediction benchmarks, and the best average performance among all benchmarks considered.
MIMAMO Net: Integrating Micro- and Macro-motion for Video Emotion Recognition
Nov 21, 2019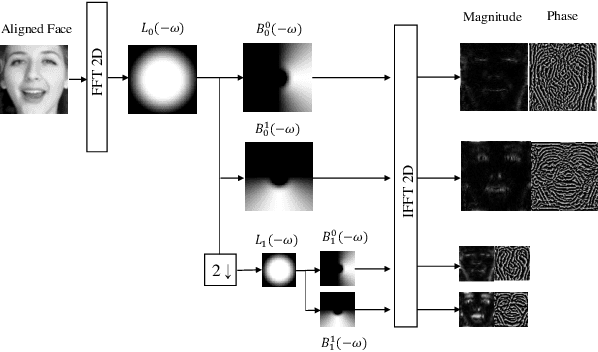
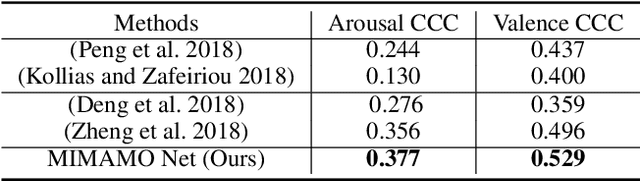
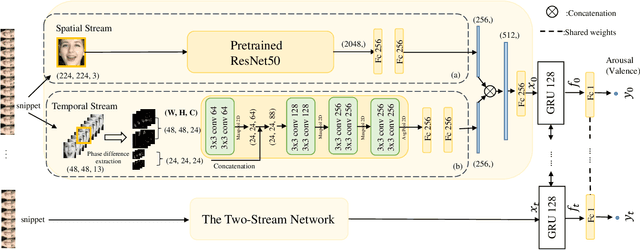
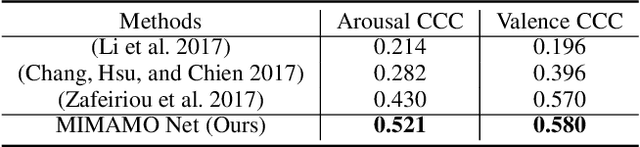
Spatial-temporal feature learning is of vital importance for video emotion recognition. Previous deep network structures often focused on macro-motion which extends over long time scales, e.g., on the order of seconds. We believe integrating structures capturing information about both micro- and macro-motion will benefit emotion prediction, because human perceive both micro- and macro-expressions. In this paper, we propose to combine micro- and macro-motion features to improve video emotion recognition with a two-stream recurrent network, named MIMAMO (Micro-Macro-Motion) Net. Specifically, smaller and shorter micro-motions are analyzed by a two-stream network, while larger and more sustained macro-motions can be well captured by a subsequent recurrent network. Assigning specific interpretations to the roles of different parts of the network enables us to make choice of parameters based on prior knowledge: choices that turn out to be optimal. One of the important innovations in our model is the use of interframe phase differences rather than optical flow as input to the temporal stream. Compared with the optical flow, phase differences require less computation and are more robust to illumination changes. Our proposed network achieves state of the art performance on two video emotion datasets, the OMG emotion dataset and the Aff-Wild dataset. The most significant gains are for arousal prediction, for which motion information is intuitively more informative. Source code is available at https://github.com/wtomin/MIMAMO-Net.
Utilizing Eye Gaze to Enhance the Generalization of Imitation Networks to Unseen Environments
Aug 27, 2019
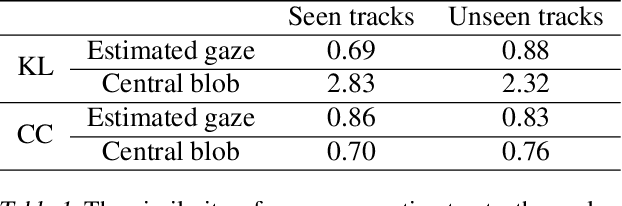
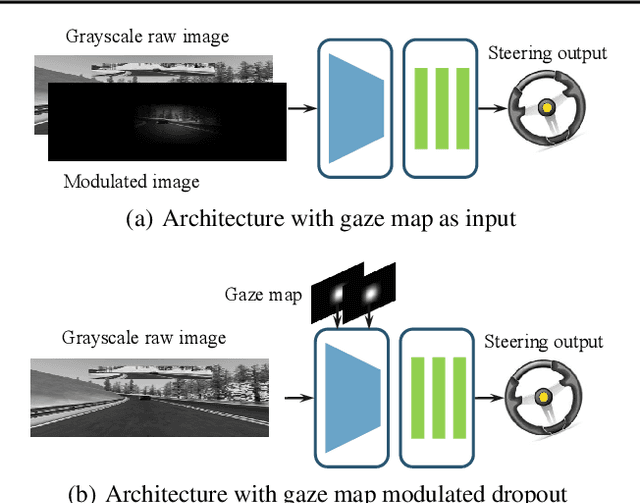
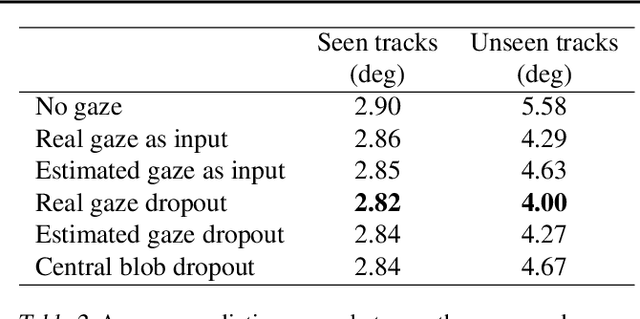
Vision-based autonomous driving through imitation learning mimics the behaviors of human drivers by training on pairs of data of raw driver-view images and actions. However, there are other cues, e.g. gaze behavior, available from human drivers that have yet to be exploited. Previous research has shown that novice human learners can benefit from observing experts' gaze patterns. We show here that deep neural networks can also benefit from this. We demonstrate different approaches to integrating gaze information into imitation networks. Our results show that the integration of gaze information improves the generalization performance of networks to unseen environments.