 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Facial Expression Detection in Long Videos
Apr 10, 2025Facial expression detection involves two interrelated tasks: spotting, which identifies the onset and offset of expressions, and recognition, which classifies them into emotional categories. Most existing methods treat these tasks separately using a two-step training pipelines. A spotting model first detects expression intervals. A recognition model then classifies the detected segments. However, this sequential approach leads to error propagation, inefficient feature learning, and suboptimal performance due to the lack of joint optimization of the two tasks. We propose FEDN, an end-to-end Facial Expression Detection Network that jointly optimizes spotting and recognition. Our model introduces a novel attention-based feature extraction module, incorporating segment attention and sliding window attention to improve facial feature learning. By unifying two tasks within a single network, we greatly reduce error propagation and enhance overall performance. Experiments on CASME}^2 and CASME^3 demonstrate state-of-the-art accuracy for both spotting and detection, underscoring the benefits of joint optimization for robust facial expression detection in long videos.
RMES: Real-Time Micro-Expression Spotting Using Phase From Riesz Pyramid
May 09, 2023Micro-expressions (MEs) are involuntary and subtle facial expressions that are thought to reveal feelings people are trying to hide. ME spotting detects the temporal intervals containing MEs in videos. Detecting such quick and subtle motions from long videos is difficult. Recent works leverage detailed facial motion representations, such as the optical flow, and deep learning models, leading to high computational complexity. To reduce computational complexity and achieve real-time operation, we propose RMES, a real-time ME spotting framework. We represent motion using phase computed by Riesz Pyramid, and feed this motion representation into a three-stream shallow CNN, which predicts the likelihood of each frame belonging to an ME. In comparison to optical flow, phase provides more localized motion estimates, which are essential for ME spotting, resulting in higher performance. Using phase also reduces the required computation of the ME spotting pipeline by 77.8%. Despite its relative simplicity and low computational complexity, our framework achieves state-of-the-art performance on two public datasets: CAS(ME)2 and SAMM Long Videos.
Integrating Holistic and Local Information to Estimate Emotional Reaction Intensity
May 09, 2023



Video-based Emotional Reaction Intensity (ERI) estimation measures the intensity of subjects' reactions to stimuli along several emotional dimensions from videos of the subject as they view the stimuli. We propose a multi-modal architecture for video-based ERI combining video and audio information. Video input is encoded spatially first, frame-by-frame, combining features encoding holistic aspects of the subjects' facial expressions and features encoding spatially localized aspects of their expressions. Input is then combined across time: from frame-to-frame using gated recurrent units (GRUs), then globally by a transformer. We handle variable video length with a regression token that accumulates information from all frames into a fixed-dimensional vector independent of video length. Audio information is handled similarly: spectral information extracted within each frame is integrated across time by a cascade of GRUs and a transformer with regression token. The video and audio regression tokens' outputs are merged by concatenation, then input to a final fully connected layer producing intensity estimates. Our architecture achieved excellent performance on the Hume-Reaction dataset in the ERI Esimation Challenge of the Fifth Competition on Affective Behavior Analysis in-the-Wild (ABAW5). The Pearson Correlation Coefficients between estimated and subject self-reported scores, averaged across all emotions, were 0.455 on the validation dataset and 0.4547 on the test dataset, well above the baselines. The transformer's self-attention mechanism enables our architecture to focus on the most critical video frames regardless of length. Ablation experiments establish the advantages of combining holistic/local features and of multi-modal integration. Code available at https://github.com/HKUST-NISL/ABAW5.
Individual risk profiling for portable devices using a neural network to process the cognitive reactions and the emotional responses to a multivariate situational risk assessment
Mar 07, 2021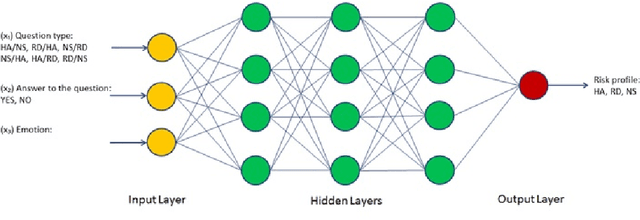
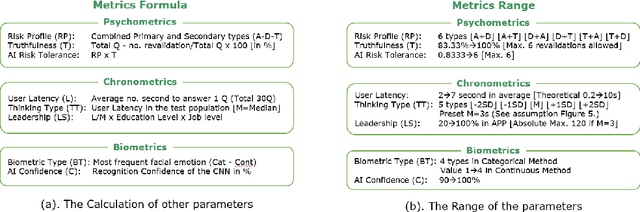
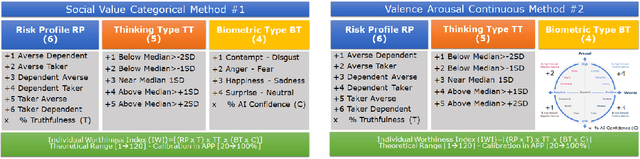
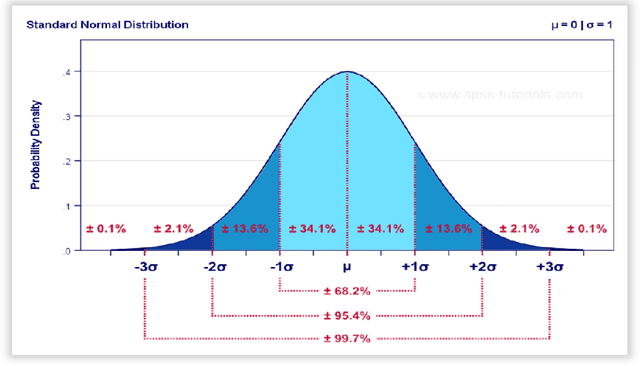
In this paper, we are presenting a novel method and system for neuropsychological performance testing that can establish a link between cognition and emotion. It comprises a portable device used to interact with a cloud service which stores user information under username and is logged into by the user through the portable device; the user information is directly captured through the device and is processed by artificial neural network; and this tridimensional information comprises user cognitive reactions, user emotional responses and user chronometrics. The multivariate situational risk assessment is used to evaluate the performance of the subject by capturing the 3 dimensions of each reaction to a series of 30 dichotomous questions describing various situations of daily life and challenging the user's knowledge, values, ethics, and principles. In industrial application, the timing of this assessment will depend on the user's need to obtain a service from a provider such as opening a bank account, getting a mortgage or an insurance policy, authenticating clearance at work or securing online payments.
Functional neural network for decision processing, a racing network of programmable neurons with fuzzy logic where the target operating model relies on the network itself
Feb 24, 2021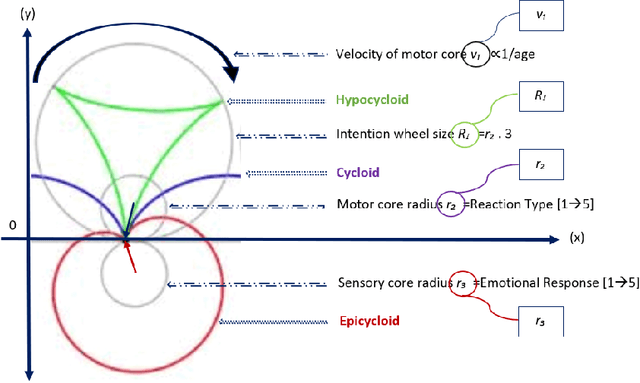
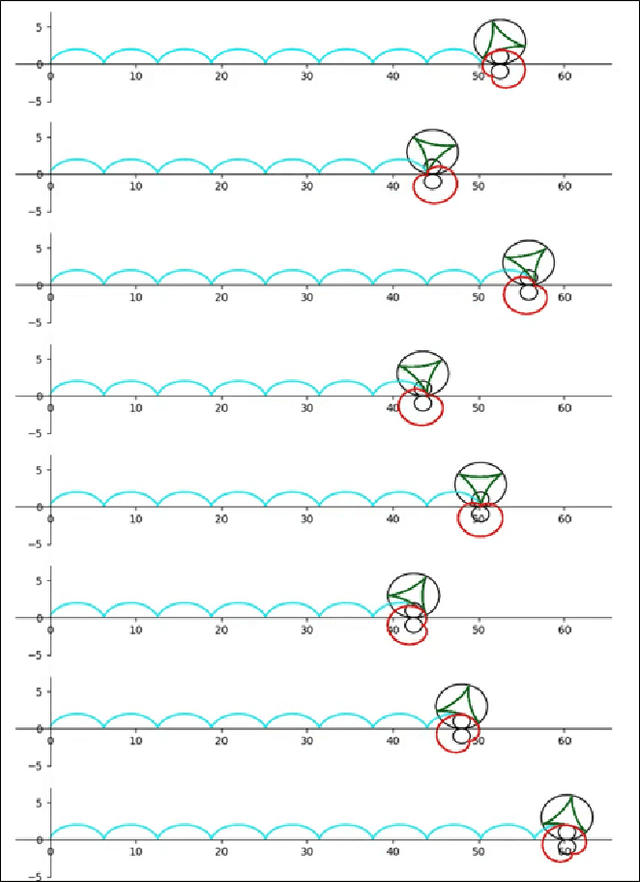
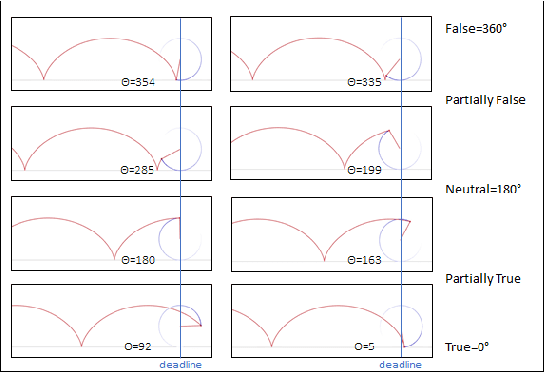
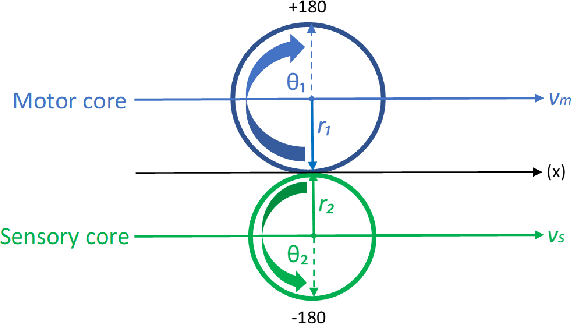
In this paper, we are introducing a novel model of artificial intelligence, the functional neural network for modeling of human decision-making processes. This neural network is composed of multiple artificial neurons racing in the network. Each of these neurons has a similar structure programmed independently by the users and composed of an intention wheel, a motor core and a sensory core representing the user itself and racing at a specific velocity. The mathematics of the neuron's formulation and the racing mechanism of multiple nodes in the network will be discussed, and the group decision process with fuzzy logic and the transformation of these conceptual methods into practical methods of simulation and in operations will be developed. Eventually, we will describe some possible future research directions in the fields of finance, education and medicine including the opportunity to design an intelligent learning agent with application in business operations supervision. We believe that this functional neural network has a promising potential to transform the way we can compute decision-making and lead to a new generation of neuromorphic chips for seamless human-machine interactions.