 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond VLM-Based Rewards: Diffusion-Native Latent Reward Modeling
Feb 11, 2026Preference optimization for diffusion and flow-matching models relies on reward functions that are both discriminatively robust and computationally efficient. Vision-Language Models (VLMs) have emerged as the primary reward provider, leveraging their rich multimodal priors to guide alignment. However, their computation and memory cost can be substantial, and optimizing a latent diffusion generator through a pixel-space reward introduces a domain mismatch that complicates alignment. In this paper, we propose DiNa-LRM, a diffusion-native latent reward model that formulates preference learning directly on noisy diffusion states. Our method introduces a noise-calibrated Thurstone likelihood with diffusion-noise-dependent uncertainty. DiNa-LRM leverages a pretrained latent diffusion backbone with a timestep-conditioned reward head, and supports inference-time noise ensembling, providing a diffusion-native mechanism for test-time scaling and robust rewarding. Across image alignment benchmarks, DiNa-LRM substantially outperforms existing diffusion-based reward baselines and achieves performance competitive with state-of-the-art VLMs at a fraction of the computational cost. In preference optimization, we demonstrate that DiNa-LRM improves preference optimization dynamics, enabling faster and more resource-efficient model alignment.
CannyEdit: Selective Canny Control and Dual-Prompt Guidance for Training-Free Image Editing
Aug 09, 2025Recent advances in text-to-image (T2I) models have enabled training-free regional image editing by leveraging the generative priors of foundation models. However, existing methods struggle to balance text adherence in edited regions, context fidelity in unedited areas, and seamless integration of edits. We introduce CannyEdit, a novel training-free framework that addresses these challenges through two key innovations: (1) Selective Canny Control, which masks the structural guidance of Canny ControlNet in user-specified editable regions while strictly preserving details of the source images in unedited areas via inversion-phase ControlNet information retention. This enables precise, text-driven edits without compromising contextual integrity. (2) Dual-Prompt Guidance, which combines local prompts for object-specific edits with a global target prompt to maintain coherent scene interactions. On real-world image editing tasks (addition, replacement, removal), CannyEdit outperforms prior methods like KV-Edit, achieving a 2.93 to 10.49 percent improvement in the balance of text adherence and context fidelity. In terms of editing seamlessness, user studies reveal only 49.2 percent of general users and 42.0 percent of AIGC experts identified CannyEdit's results as AI-edited when paired with real images without edits, versus 76.08 to 89.09 percent for competitor methods.
Dual Risk Minimization: Towards Next-Level Robustness in Fine-tuning Zero-Shot Models
Nov 29, 2024



Fine-tuning foundation models often compromises their robustness to distribution shifts. To remedy this, most robust fine-tuning methods aim to preserve the pre-trained features. However, not all pre-trained features are robust and those methods are largely indifferent to which ones to preserve. We propose dual risk minimization (DRM), which combines empirical risk minimization with worst-case risk minimization, to better preserve the core features of downstream tasks. In particular, we utilize core-feature descriptions generated by LLMs to induce core-based zero-shot predictions which then serve as proxies to estimate the worst-case risk. DRM balances two crucial aspects of model robustness: expected performance and worst-case performance, establishing a new state of the art on various real-world benchmarks. DRM significantly improves the out-of-distribution performance of CLIP ViT-L/14@336 on ImageNet (75.9 to 77.1), WILDS-iWildCam (47.1 to 51.8), and WILDS-FMoW (50.7 to 53.1); opening up new avenues for robust fine-tuning. Our code is available at https://github.com/vaynexie/DRM .
RMES: Real-Time Micro-Expression Spotting Using Phase From Riesz Pyramid
May 09, 2023Micro-expressions (MEs) are involuntary and subtle facial expressions that are thought to reveal feelings people are trying to hide. ME spotting detects the temporal intervals containing MEs in videos. Detecting such quick and subtle motions from long videos is difficult. Recent works leverage detailed facial motion representations, such as the optical flow, and deep learning models, leading to high computational complexity. To reduce computational complexity and achieve real-time operation, we propose RMES, a real-time ME spotting framework. We represent motion using phase computed by Riesz Pyramid, and feed this motion representation into a three-stream shallow CNN, which predicts the likelihood of each frame belonging to an ME. In comparison to optical flow, phase provides more localized motion estimates, which are essential for ME spotting, resulting in higher performance. Using phase also reduces the required computation of the ME spotting pipeline by 77.8%. Despite its relative simplicity and low computational complexity, our framework achieves state-of-the-art performance on two public datasets: CAS(ME)2 and SAMM Long Videos.
Multiple Emotion Descriptors Estimation at the ABAW3 Challenge
Mar 29, 2022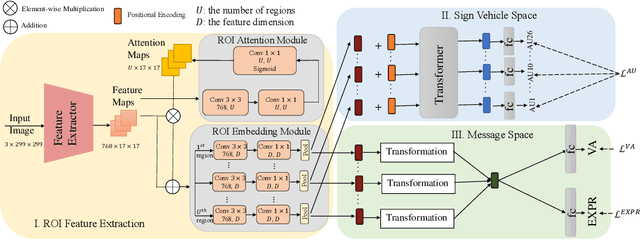
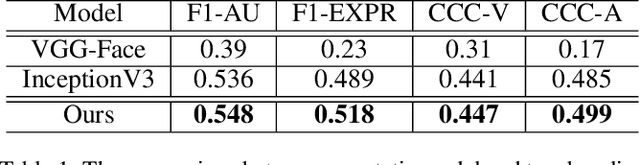
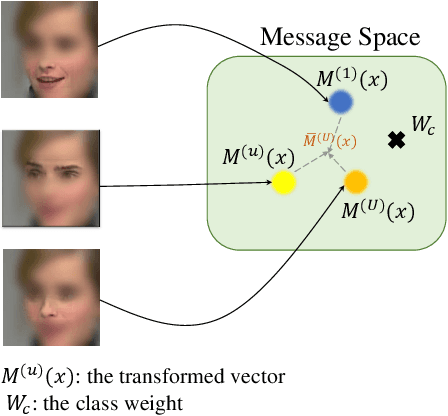
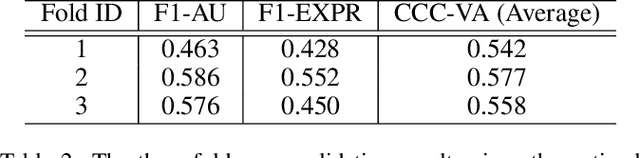
To describe complex emotional states, psychologists have proposed multiple emotion descriptors: sparse descriptors like facial action units; continuous descriptors like valence and arousal; and discrete class descriptors like happiness and anger. According to Ekman and Friesen, 1969, facial action units are sign vehicles that convey the emotion message, while discrete or continuous emotion descriptors are the messages perceived and expressed by human. In this paper, we designed an architecture for multiple emotion descriptors estimation in participating the ABAW3 Challenge. Based on the theory of Ekman and Friesen, 1969, we designed distinct architectures to measure the sign vehicles (i.e., facial action units) and the message (i.e., discrete emotions, valence and arousal) given their different properties. The quantitative experiments on the ABAW3 challenge dataset has shown the superior performance of our approach over two baseline models.
Towards Better Uncertainty: Iterative Training of Efficient Networks for Multitask Emotion Recognition
Jul 21, 2021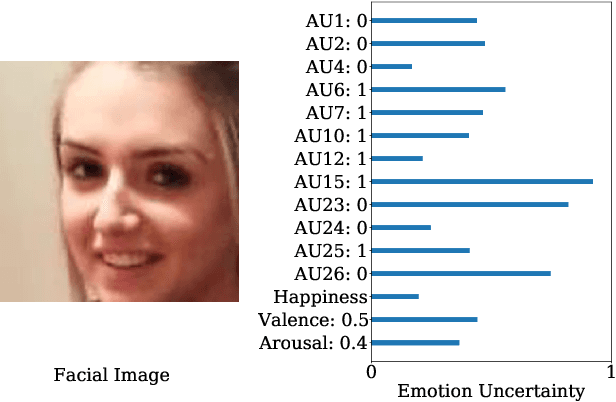
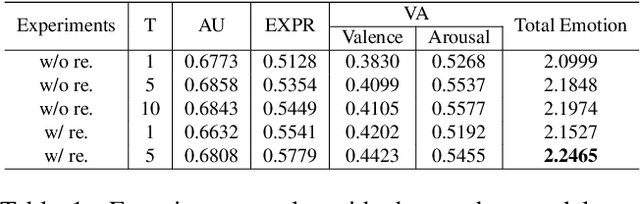
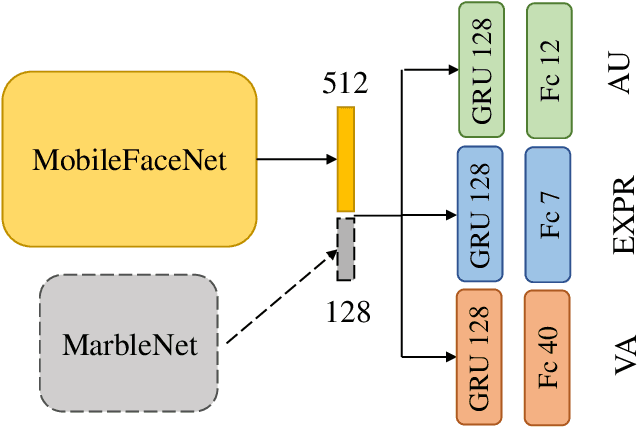
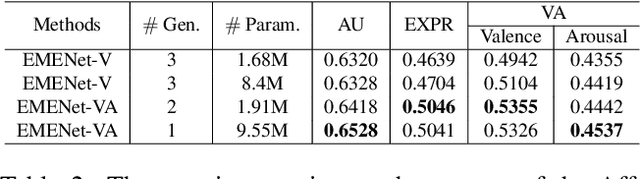
When recognizing emotions, subtle nuances of emotion displays often cause ambiguity or uncertainty in emotion perception. Unfortunately, the ambiguity or uncertainty cannot be reflected in hard emotion labels. Emotion predictions with uncertainty can be useful for risk controlling, but they are relatively scarce in current deep models for emotion recognition. To address this issue, we propose to apply the multi-generational self-distillation algorithm to emotion recognition task towards better uncertainty estimation performance. We firstly use deep ensembles to capture uncertainty, as an approximation to Bayesian methods. Secondly, the deep ensemble provides soft labels to its student models, while the student models can learn from the uncertainty embedded in those soft labels. Thirdly, we iteratively train deep ensembles to further improve the performance of emotion recognition and uncertainty estimation. In the end, our algorithm results in a single student model that can estimate in-domain uncertainty and a student ensemble that can detect out-of-domain samples. We trained our Efficient Multitask Emotion Networks (EMENet) on the Aff-wild2 dataset, and conducted extensive experiments on emotion recognition and uncertainty estimation. Our algorithm gives more reliable uncertainty estimates than Temperature Scaling and Monte Carol Dropout.
Individual risk profiling for portable devices using a neural network to process the cognitive reactions and the emotional responses to a multivariate situational risk assessment
Mar 07, 2021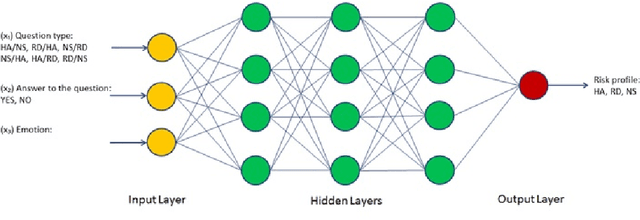
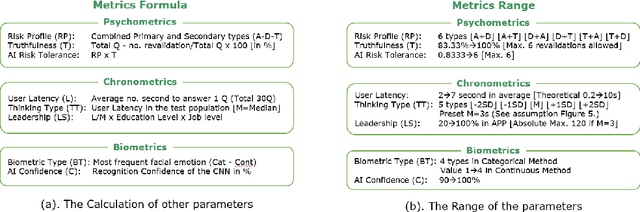
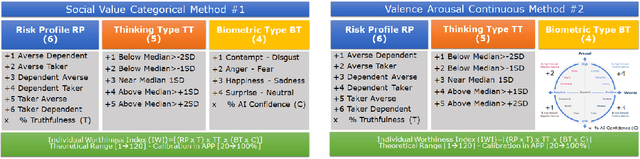
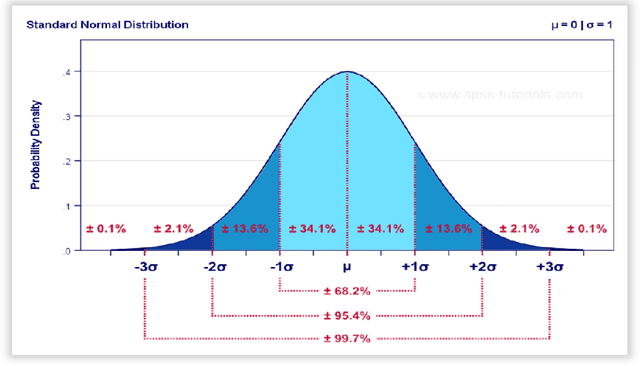
In this paper, we are presenting a novel method and system for neuropsychological performance testing that can establish a link between cognition and emotion. It comprises a portable device used to interact with a cloud service which stores user information under username and is logged into by the user through the portable device; the user information is directly captured through the device and is processed by artificial neural network; and this tridimensional information comprises user cognitive reactions, user emotional responses and user chronometrics. The multivariate situational risk assessment is used to evaluate the performance of the subject by capturing the 3 dimensions of each reaction to a series of 30 dichotomous questions describing various situations of daily life and challenging the user's knowledge, values, ethics, and principles. In industrial application, the timing of this assessment will depend on the user's need to obtain a service from a provider such as opening a bank account, getting a mortgage or an insurance policy, authenticating clearance at work or securing online payments.
Functional neural network for decision processing, a racing network of programmable neurons with fuzzy logic where the target operating model relies on the network itself
Feb 24, 2021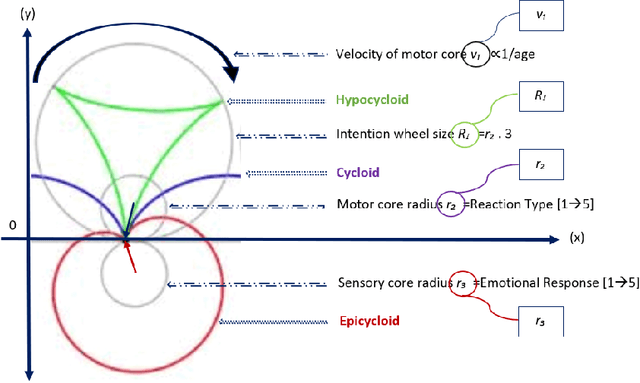
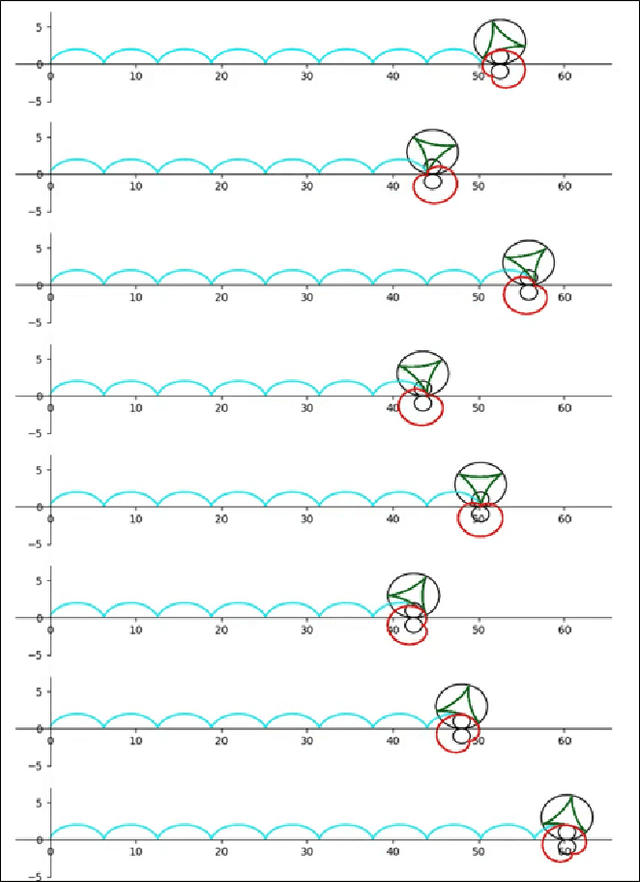
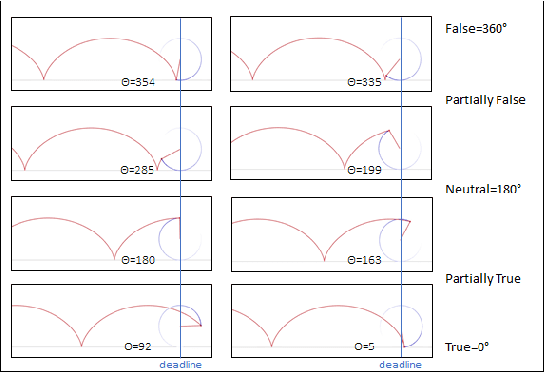
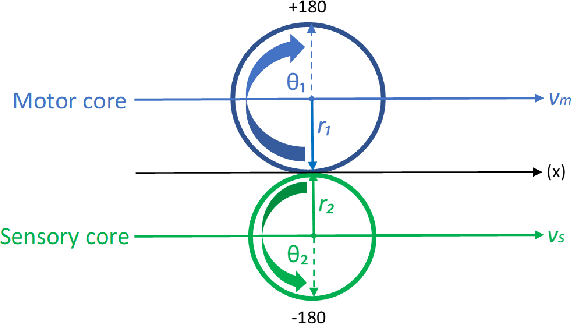
In this paper, we are introducing a novel model of artificial intelligence, the functional neural network for modeling of human decision-making processes. This neural network is composed of multiple artificial neurons racing in the network. Each of these neurons has a similar structure programmed independently by the users and composed of an intention wheel, a motor core and a sensory core representing the user itself and racing at a specific velocity. The mathematics of the neuron's formulation and the racing mechanism of multiple nodes in the network will be discussed, and the group decision process with fuzzy logic and the transformation of these conceptual methods into practical methods of simulation and in operations will be developed. Eventually, we will describe some possible future research directions in the fields of finance, education and medicine including the opportunity to design an intelligent learning agent with application in business operations supervision. We believe that this functional neural network has a promising potential to transform the way we can compute decision-making and lead to a new generation of neuromorphic chips for seamless human-machine interactions.
Multitask Emotion Recognition with Incomplete Labels
Mar 10, 2020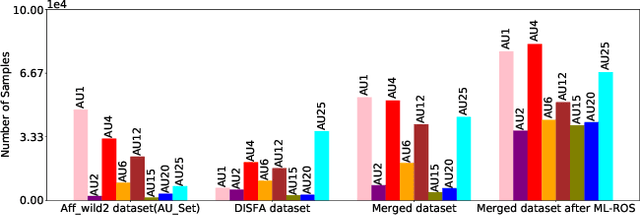
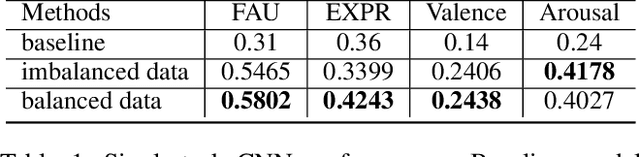
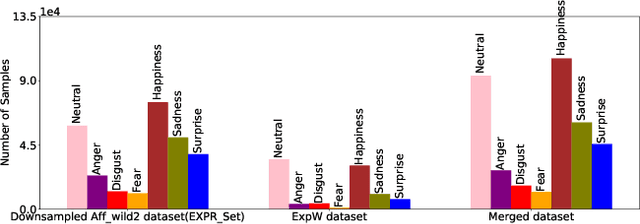
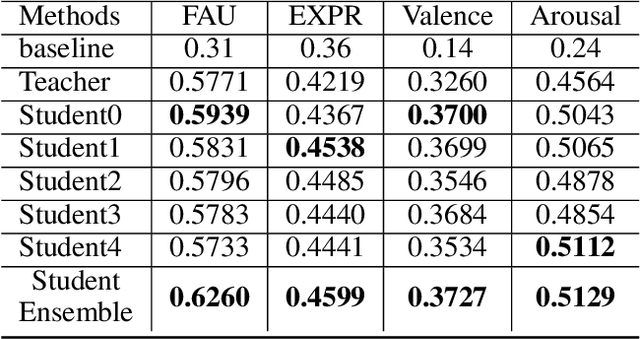
We train a unified model to perform three tasks: facial action unit detection, expression classification, and valence-arousal estimation. We address two main challenges of learning the three tasks. First, most existing datasets are highly imbalanced. Second, most existing datasets do not contain labels for all three tasks. To tackle the first challenge, we apply data balancing techniques to experimental datasets. To tackle the second challenge, we propose an algorithm for the multitask model to learn from missing (incomplete) labels. This algorithm has two steps. We first train a teacher model to perform all three tasks, where each instance is trained by the ground truth label of its corresponding task. Secondly, we refer to the outputs of the teacher model as the soft labels. We use the soft labels and the ground truth to train the student model. We find that most of the student models outperform their teacher model on all the three tasks. Finally, we use model ensembling to boost performance further on the three tasks.
MIMAMO Net: Integrating Micro- and Macro-motion for Video Emotion Recognition
Nov 21, 2019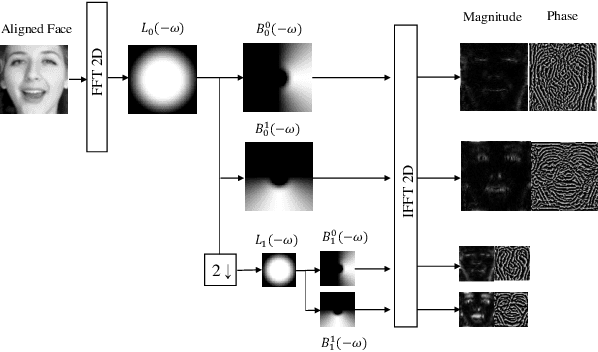
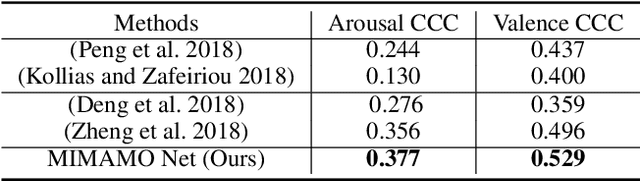
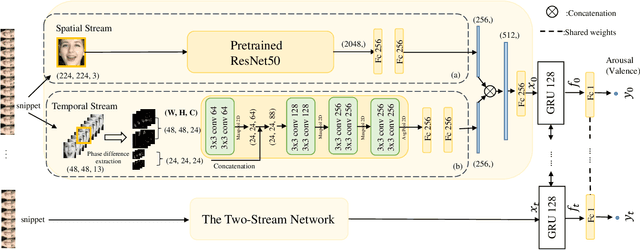
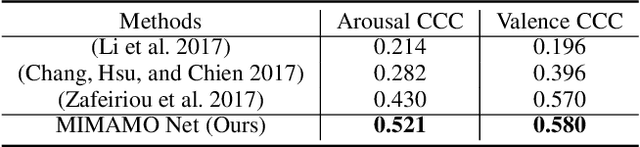
Spatial-temporal feature learning is of vital importance for video emotion recognition. Previous deep network structures often focused on macro-motion which extends over long time scales, e.g., on the order of seconds. We believe integrating structures capturing information about both micro- and macro-motion will benefit emotion prediction, because human perceive both micro- and macro-expressions. In this paper, we propose to combine micro- and macro-motion features to improve video emotion recognition with a two-stream recurrent network, named MIMAMO (Micro-Macro-Motion) Net. Specifically, smaller and shorter micro-motions are analyzed by a two-stream network, while larger and more sustained macro-motions can be well captured by a subsequent recurrent network. Assigning specific interpretations to the roles of different parts of the network enables us to make choice of parameters based on prior knowledge: choices that turn out to be optimal. One of the important innovations in our model is the use of interframe phase differences rather than optical flow as input to the temporal stream. Compared with the optical flow, phase differences require less computation and are more robust to illumination changes. Our proposed network achieves state of the art performance on two video emotion datasets, the OMG emotion dataset and the Aff-Wild dataset. The most significant gains are for arousal prediction, for which motion information is intuitively more informative. Source code is available at https://github.com/wtomin/MIMAMO-Net.