 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Utterance-level Affect Analysis using Visual, Audio and Text Features
Paper and Code
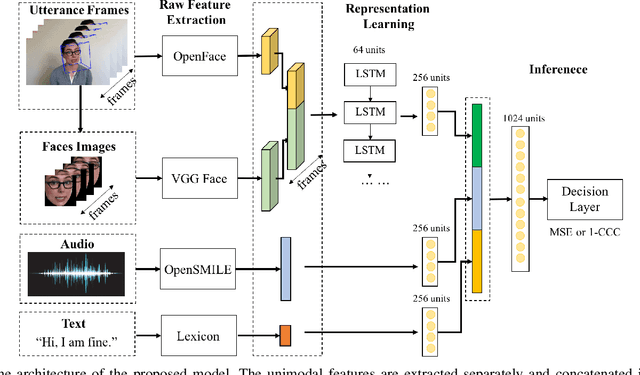
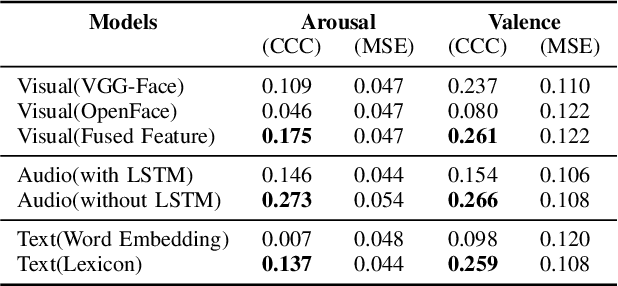
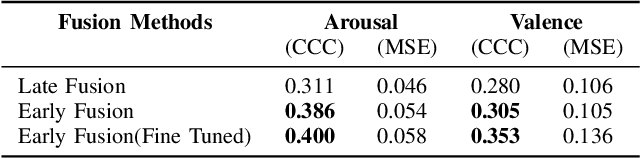
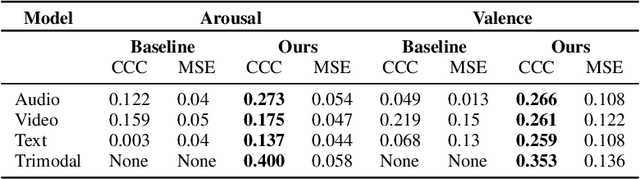
The integration of information across multiple modalities and across time is a promising way to enhance the emotion recognition performance of affective systems. Much previous work has focused on instantaneous emotion recognition. The 2018 One-Minute Gradual-Emotion Recognition (OMG-Emotion) challenge, which was held in conjunction with the IEEE World Congress on Computational Intelligence, encouraged participants to address long-term emotion recognition by integrating cues from multiple modalities, including facial expression, audio and language. Intuitively, a multi-modal inference network should be able to leverage information from each modality and their correlations to improve recognition over that achievable by a single modality network. We describe here a multi-modal neural architecture that integrates visual information over time using an LSTM, and combines it with utterance level audio and text cues to recognize human sentiment from multimodal clips. Our model outperforms the unimodal baseline, achieving the concordance correlation coefficients (CCC) of 0.400 on the arousal task, and 0.353 on the valence task.