 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Diffusion Network for Semantic Segmentation
Feb 04, 2023Precise and accurate predictions over boundary areas are essential for semantic segmentation. However, the commonly-used convolutional operators tend to smooth and blur local detail cues, making it difficult for deep models to generate accurate boundary predictions. In this paper, we introduce an operator-level approach to enhance semantic boundary awareness, so as to improve the prediction of the deep semantic segmentation model. Specifically, we first formulate the boundary feature enhancement as an anisotropic diffusion process. We then propose a novel learnable approach called semantic diffusion network (SDN) to approximate the diffusion process, which contains a parameterized semantic difference convolution operator followed by a feature fusion module. Our SDN aims to construct a differentiable mapping from the original feature to the inter-class boundary-enhanced feature. The proposed SDN is an efficient and flexible module that can be easily plugged into existing encoder-decoder segmentation models. Extensive experiments show that our approach can achieve consistent improvements over several typical and state-of-the-art segmentation baseline models on challenging public benchmarks. The code will be released soon.
Augmentation Matters: A Simple-yet-Effective Approach to Semi-supervised Semantic Segmentation
Dec 09, 2022



Recent studies on semi-supervised semantic segmentation (SSS) have seen fast progress. Despite their promising performance, current state-of-the-art methods tend to increasingly complex designs at the cost of introducing more network components and additional training procedures. Differently, in this work, we follow a standard teacher-student framework and propose AugSeg, a simple and clean approach that focuses mainly on data perturbations to boost the SSS performance. We argue that various data augmentations should be adjusted to better adapt to the semi-supervised scenarios instead of directly applying these techniques from supervised learning. Specifically, we adopt a simplified intensity-based augmentation that selects a random number of data transformations with uniformly sampling distortion strengths from a continuous space. Based on the estimated confidence of the model on different unlabeled samples, we also randomly inject labelled information to augment the unlabeled samples in an adaptive manner. Without bells and whistles, our simple AugSeg can readily achieve new state-of-the-art performance on SSS benchmarks under different partition protocols.
Beyond Attentive Tokens: Incorporating Token Importance and Diversity for Efficient Vision Transformers
Nov 21, 2022



Vision transformers have achieved significant improvements on various vision tasks but their quadratic interactions between tokens significantly reduce computational efficiency. Many pruning methods have been proposed to remove redundant tokens for efficient vision transformers recently. However, existing studies mainly focus on the token importance to preserve local attentive tokens but completely ignore the global token diversity. In this paper, we emphasize the cruciality of diverse global semantics and propose an efficient token decoupling and merging method that can jointly consider the token importance and diversity for token pruning. According to the class token attention, we decouple the attentive and inattentive tokens. In addition to preserving the most discriminative local tokens, we merge similar inattentive tokens and match homogeneous attentive tokens to maximize the token diversity. Despite its simplicity, our method obtains a promising trade-off between model complexity and classification accuracy. On DeiT-S, our method reduces the FLOPs by 35% with only a 0.2% accuracy drop. Notably, benefiting from maintaining the token diversity, our method can even improve the accuracy of DeiT-T by 0.1% after reducing its FLOPs by 40%.
Instance-specific and Model-adaptive Supervision for Semi-supervised Semantic Segmentation
Nov 21, 2022



Recently, semi-supervised semantic segmentation has achieved promising performance with a small fraction of labeled data. However, most existing studies treat all unlabeled data equally and barely consider the differences and training difficulties among unlabeled instances. Differentiating unlabeled instances can promote instance-specific supervision to adapt to the model's evolution dynamically. In this paper, we emphasize the cruciality of instance differences and propose an instance-specific and model-adaptive supervision for semi-supervised semantic segmentation, named iMAS. Relying on the model's performance, iMAS employs a class-weighted symmetric intersection-over-union to evaluate quantitative hardness of each unlabeled instance and supervises the training on unlabeled data in a model-adaptive manner. Specifically, iMAS learns from unlabeled instances progressively by weighing their corresponding consistency losses based on the evaluated hardness. Besides, iMAS dynamically adjusts the augmentation for each instance such that the distortion degree of augmented instances is adapted to the model's generalization capability across the training course. Not integrating additional losses and training procedures, iMAS can obtain remarkable performance gains against current state-of-the-art approaches on segmentation benchmarks under different semi-supervised partition protocols.
CAE v2: Context Autoencoder with CLIP Target
Nov 17, 2022



Masked image modeling (MIM) learns visual representation by masking and reconstructing image patches. Applying the reconstruction supervision on the CLIP representation has been proven effective for MIM. However, it is still under-explored how CLIP supervision in MIM influences performance. To investigate strategies for refining the CLIP-targeted MIM, we study two critical elements in MIM, i.e., the supervision position and the mask ratio, and reveal two interesting perspectives, relying on our developed simple pipeline, context autodecoder with CLIP target (CAE v2). Firstly, we observe that the supervision on visible patches achieves remarkable performance, even better than that on masked patches, where the latter is the standard format in the existing MIM methods. Secondly, the optimal mask ratio positively correlates to the model size. That is to say, the smaller the model, the lower the mask ratio needs to be. Driven by these two discoveries, our simple and concise approach CAE v2 achieves superior performance on a series of downstream tasks. For example, a vanilla ViT-Large model achieves 81.7% and 86.7% top-1 accuracy on linear probing and fine-tuning on ImageNet-1K, and 55.9% mIoU on semantic segmentation on ADE20K with the pre-training for 300 epochs. We hope our findings can be helpful guidelines for the pre-training in the MIM area, especially for the small-scale models.
Multimodal Utterance-level Affect Analysis using Visual, Audio and Text Features
May 04, 2018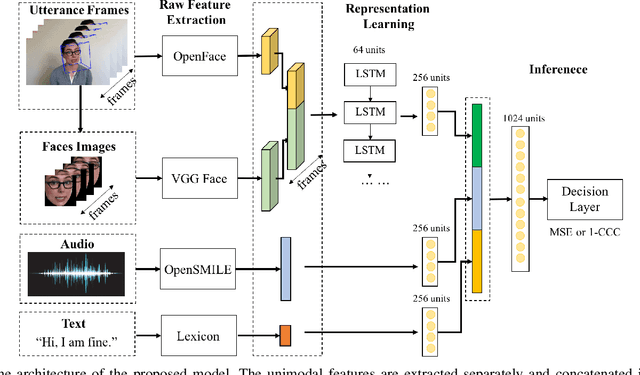
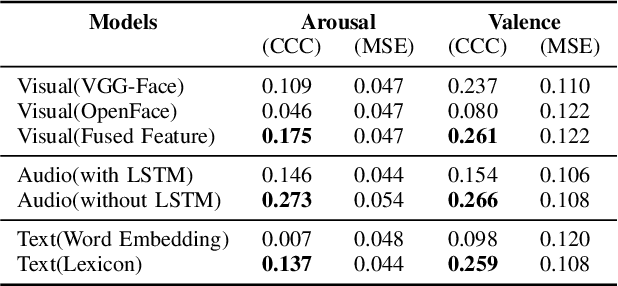
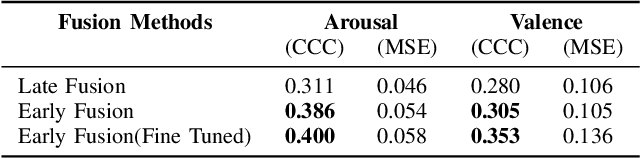
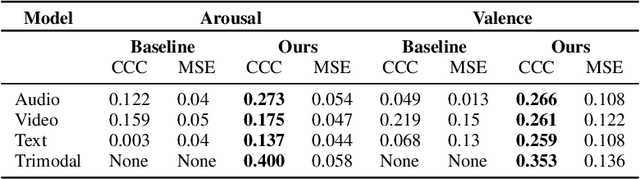
The integration of information across multiple modalities and across time is a promising way to enhance the emotion recognition performance of affective systems. Much previous work has focused on instantaneous emotion recognition. The 2018 One-Minute Gradual-Emotion Recognition (OMG-Emotion) challenge, which was held in conjunction with the IEEE World Congress on Computational Intelligence, encouraged participants to address long-term emotion recognition by integrating cues from multiple modalities, including facial expression, audio and language. Intuitively, a multi-modal inference network should be able to leverage information from each modality and their correlations to improve recognition over that achievable by a single modality network. We describe here a multi-modal neural architecture that integrates visual information over time using an LSTM, and combines it with utterance level audio and text cues to recognize human sentiment from multimodal clips. Our model outperforms the unimodal baseline, achieving the concordance correlation coefficients (CCC) of 0.400 on the arousal task, and 0.353 on the valence task.