 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long-Context Modeling in Diffusion Language Models via Block Approximate Sparse Attention
May 19, 2026Diffusion Language Models (DLMs) enable globally coherent, bidirectional, and controllable text generation, offering advantages over traditional autoregressive LLMs, while scaling to ultra-long sequences remains costly. Many existing block-sparse attention methods select blocks by fixed sampling patterns over the high-resolution attention space, such as tail regions or anti-diagonal stripes. Such prior-driven sampling can miss salient tokens and introduce instability under distribution shifts. In this paper, we propose the Block Approximate Sparse Attention framework (BA-Att) with block-wise pre-downsampled operation, which identifies informative regions within a compact downsampled space, avoiding reliance on brittle positional priors. To analyze its theoretical behavior, we define an oracle post-downsample attention map and formalize the approximation error between pre- and post-downsample schemes. Based on this insight, we introduce a lightweight norm-sorting module and a covariance-compensated correction that approximates full covariance using diagonal QK variances, reducing computational complexity. Extensive experiments show that our operator achieves up to 6.95x acceleration over FlashAttention in attention computation, and maintains near full-attention performance at 50% sparsity across language models, multimodal language models, and video generation models, demonstrating strong efficiency and generalization.
SearchGym: Bootstrapping Real-World Search Agents via Cost-Effective and High-Fidelity Environment Simulation
Jan 21, 2026Search agents have emerged as a pivotal paradigm for solving open-ended, knowledge-intensive reasoning tasks. However, training these agents via Reinforcement Learning (RL) faces a critical dilemma: interacting with live commercial Web APIs is prohibitively expensive, while relying on static data snapshots often introduces noise due to data misalignment. This misalignment generates corrupted reward signals that destabilize training by penalizing correct reasoning or rewarding hallucination. To address this, we propose SearchGym, a simulation environment designed to bootstrap robust search agents. SearchGym employs a rigorous generative pipeline to construct a verifiable knowledge graph and an aligned document corpus, ensuring that every reasoning task is factually grounded and strictly solvable. Building on this controllable environment, we introduce SearchGym-RL, a curriculum learning methodology that progressively optimizes agent policies through purified feedback, evolving from basic interactions to complex, long-horizon planning. Extensive experiments across the Llama and Qwen families demonstrate strong Sim-to-Real generalization. Notably, our Qwen2.5-7B-Base model trained within SearchGym surpasses the web-enhanced ASearcher baseline across nine diverse benchmarks by an average relative margin of 10.6%. Our results validate that high-fidelity simulation serves as a scalable and highly cost-effective methodology for developing capable search agents.
DreamOmni3: Scribble-based Editing and Generation
Dec 27, 2025Recently unified generation and editing models have achieved remarkable success with their impressive performance. These models rely mainly on text prompts for instruction-based editing and generation, but language often fails to capture users intended edit locations and fine-grained visual details. To this end, we propose two tasks: scribble-based editing and generation, that enables more flexible creation on graphical user interface (GUI) combining user textual, images, and freehand sketches. We introduce DreamOmni3, tackling two challenges: data creation and framework design. Our data synthesis pipeline includes two parts: scribble-based editing and generation. For scribble-based editing, we define four tasks: scribble and instruction-based editing, scribble and multimodal instruction-based editing, image fusion, and doodle editing. Based on DreamOmni2 dataset, we extract editable regions and overlay hand-drawn boxes, circles, doodles or cropped image to construct training data. For scribble-based generation, we define three tasks: scribble and instruction-based generation, scribble and multimodal instruction-based generation, and doodle generation, following similar data creation pipelines. For the framework, instead of using binary masks, which struggle with complex edits involving multiple scribbles, images, and instructions, we propose a joint input scheme that feeds both the original and scribbled source images into the model, using different colors to distinguish regions and simplify processing. By applying the same index and position encodings to both images, the model can precisely localize scribbled regions while maintaining accurate editing. Finally, we establish comprehensive benchmarks for these tasks to promote further research. Experimental results demonstrate that DreamOmni3 achieves outstanding performance, and models and code will be publicly released.
Repulsor: Accelerating Generative Modeling with a Contrastive Memory Bank
Dec 13, 2025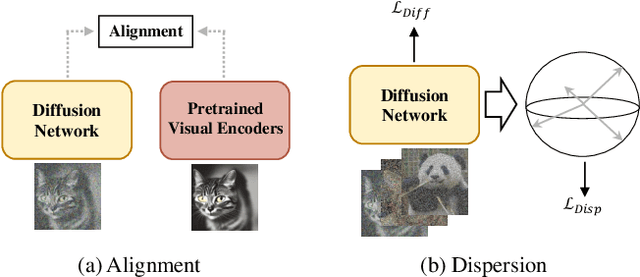
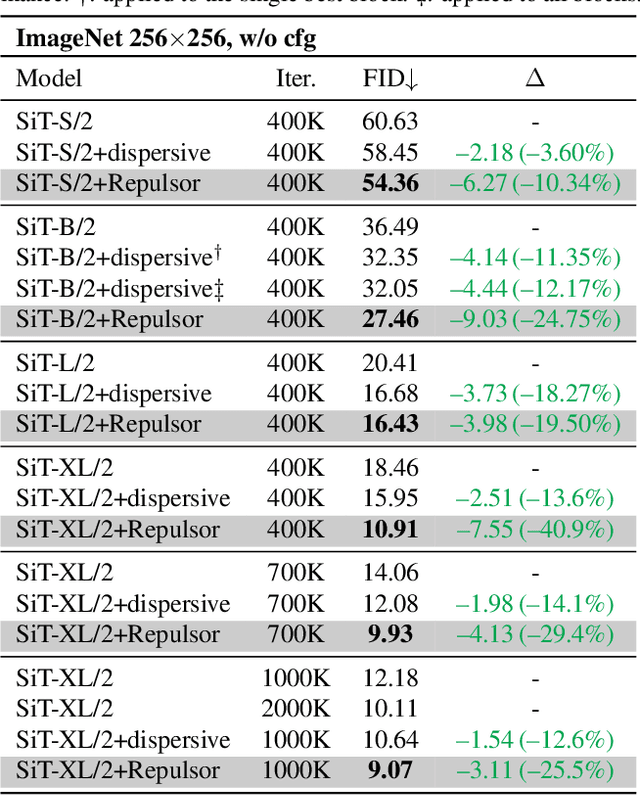
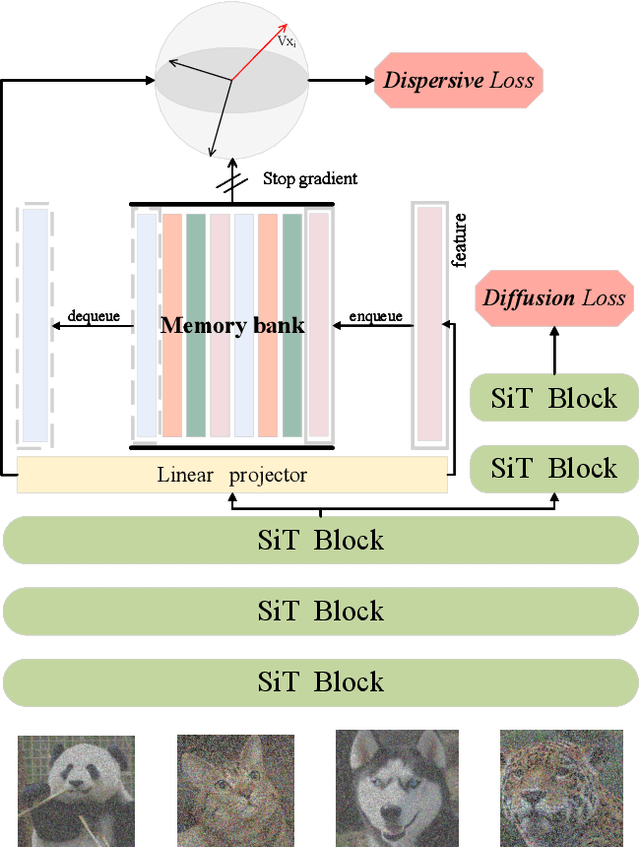

The dominance of denoising generative models (e.g., diffusion, flow-matching) in visual synthesis is tempered by their substantial training costs and inefficiencies in representation learning. While injecting discriminative representations via auxiliary alignment has proven effective, this approach still faces key limitations: the reliance on external, pre-trained encoders introduces overhead and domain shift. A dispersed-based strategy that encourages strong separation among in-batch latent representations alleviates this specific dependency. To assess the effect of the number of negative samples in generative modeling, we propose {\mname}, a plug-and-play training framework that requires no external encoders. Our method integrates a memory bank mechanism that maintains a large, dynamically updated queue of negative samples across training iterations. This decouples the number of negatives from the mini-batch size, providing abundant and high-quality negatives for a contrastive objective without a multiplicative increase in computational cost. A low-dimensional projection head is used to further minimize memory and bandwidth overhead. {\mname} offers three principal advantages: (1) it is self-contained, eliminating dependency on pretrained vision foundation models and their associated forward-pass overhead; (2) it introduces no additional parameters or computational cost during inference; and (3) it enables substantially faster convergence, achieving superior generative quality more efficiently. On ImageNet-256, {\mname} achieves a state-of-the-art FID of \textbf{2.40} within 400k steps, significantly outperforming comparable methods.
Dual-Branch Center-Surrounding Contrast: Rethinking Contrastive Learning for 3D Point Clouds
Dec 09, 2025



Most existing self-supervised learning (SSL) approaches for 3D point clouds are dominated by generative methods based on Masked Autoencoders (MAE). However, these generative methods have been proven to struggle to capture high-level discriminative features effectively, leading to poor performance on linear probing and other downstream tasks. In contrast, contrastive methods excel in discriminative feature representation and generalization ability on image data. Despite this, contrastive learning (CL) in 3D data remains scarce. Besides, simply applying CL methods designed for 2D data to 3D fails to effectively learn 3D local details. To address these challenges, we propose a novel Dual-Branch \textbf{C}enter-\textbf{S}urrounding \textbf{Con}trast (CSCon) framework. Specifically, we apply masking to the center and surrounding parts separately, constructing dual-branch inputs with center-biased and surrounding-biased representations to better capture rich geometric information. Meanwhile, we introduce a patch-level contrastive loss to further enhance both high-level information and local sensitivity. Under the FULL and ALL protocols, CSCon achieves performance comparable to generative methods; under the MLP-LINEAR, MLP-3, and ONLY-NEW protocols, our method attains state-of-the-art results, even surpassing cross-modal approaches. In particular, under the MLP-LINEAR protocol, our method outperforms the baseline (Point-MAE) by \textbf{7.9\%}, \textbf{6.7\%}, and \textbf{10.3\%} on the three variants of ScanObjectNN, respectively. The code will be made publicly available.
Scaf-GRPO: Scaffolded Group Relative Policy Optimization for Enhancing LLM Reasoning
Oct 22, 2025Reinforcement learning from verifiable rewards has emerged as a powerful technique for enhancing the complex reasoning abilities of Large Language Models (LLMs). However, these methods are fundamentally constrained by the ''learning cliff'' phenomenon: when faced with problems far beyond their current capabilities, models consistently fail, yielding a persistent zero-reward signal. In policy optimization algorithms like GRPO, this collapses the advantage calculation to zero, rendering these difficult problems invisible to the learning gradient and stalling progress. To overcome this, we introduce Scaf-GRPO (Scaffolded Group Relative Policy Optimization), a progressive training framework that strategically provides minimal guidance only when a model's independent learning has plateaued. The framework first diagnoses learning stagnation and then intervenes by injecting tiered in-prompt hints, ranging from abstract concepts to concrete steps, enabling the model to construct a valid solution by itself. Extensive experiments on challenging mathematics benchmarks demonstrate Scaf-GRPO's effectiveness, boosting the pass@1 score of the Qwen2.5-Math-7B model on the AIME24 benchmark by a relative 44.3% over a vanilla GRPO baseline. This result demonstrates our framework provides a robust and effective methodology for unlocking a model's ability to solve problems previously beyond its reach, a critical step towards extending the frontier of autonomous reasoning in LLM.
Understanding Data Influence with Differential Approximation
Aug 20, 2025Data plays a pivotal role in the groundbreaking advancements in artificial intelligence. The quantitative analysis of data significantly contributes to model training, enhancing both the efficiency and quality of data utilization. However, existing data analysis tools often lag in accuracy. For instance, many of these tools even assume that the loss function of neural networks is convex. These limitations make it challenging to implement current methods effectively. In this paper, we introduce a new formulation to approximate a sample's influence by accumulating the differences in influence between consecutive learning steps, which we term Diff-In. Specifically, we formulate the sample-wise influence as the cumulative sum of its changes/differences across successive training iterations. By employing second-order approximations, we approximate these difference terms with high accuracy while eliminating the need for model convexity required by existing methods. Despite being a second-order method, Diff-In maintains computational complexity comparable to that of first-order methods and remains scalable. This efficiency is achieved by computing the product of the Hessian and gradient, which can be efficiently approximated using finite differences of first-order gradients. We assess the approximation accuracy of Diff-In both theoretically and empirically. Our theoretical analysis demonstrates that Diff-In achieves significantly lower approximation error compared to existing influence estimators. Extensive experiments further confirm its superior performance across multiple benchmark datasets in three data-centric tasks: data cleaning, data deletion, and coreset selection. Notably, our experiments on data pruning for large-scale vision-language pre-training show that Diff-In can scale to millions of data points and outperforms strong baselines.
Logits-Based Finetuning
May 30, 2025



The core of out-of-distribution (OOD) detection is to learn the in-distribution (ID) representation, which is distinguishable from OOD samples. Previous work applied recognition-based methods to learn the ID features, which tend to learn shortcuts instead of comprehensive representations. In this work, we find surprisingly that simply using reconstruction-based methods could boost the performance of OOD detection significantly. We deeply explore the main contributors of OOD detection and find that reconstruction-based pretext tasks have the potential to provide a generally applicable and efficacious prior, which benefits the model in learning intrinsic data distributions of the ID dataset. Specifically, we take Masked Image Modeling as a pretext task for our OOD detection framework (MOOD). Without bells and whistles, MOOD outperforms previous SOTA of one-class OOD detection by 5.7%, multi-class OOD detection by 3.0%, and near-distribution OOD detection by 2.1%. It even defeats the 10-shot-per-class outlier exposure OOD detection, although we do not include any OOD samples for our detection. Codes are available at https://github.com/JulietLJY/MOOD.
Lyra: An Efficient and Speech-Centric Framework for Omni-Cognition
Dec 12, 2024



As Multi-modal Large Language Models (MLLMs) evolve, expanding beyond single-domain capabilities is essential to meet the demands for more versatile and efficient AI. However, previous omni-models have insufficiently explored speech, neglecting its integration with multi-modality. We introduce Lyra, an efficient MLLM that enhances multimodal abilities, including advanced long-speech comprehension, sound understanding, cross-modality efficiency, and seamless speech interaction. To achieve efficiency and speech-centric capabilities, Lyra employs three strategies: (1) leveraging existing open-source large models and a proposed multi-modality LoRA to reduce training costs and data requirements; (2) using a latent multi-modality regularizer and extractor to strengthen the relationship between speech and other modalities, thereby enhancing model performance; and (3) constructing a high-quality, extensive dataset that includes 1.5M multi-modal (language, vision, audio) data samples and 12K long speech samples, enabling Lyra to handle complex long speech inputs and achieve more robust omni-cognition. Compared to other omni-methods, Lyra achieves state-of-the-art performance on various vision-language, vision-speech, and speech-language benchmarks, while also using fewer computational resources and less training data.
RoboCoder: Robotic Learning from Basic Skills to General Tasks with Large Language Models
Jun 06, 2024



The emergence of Large Language Models (LLMs) has improved the prospects for robotic tasks. However, existing benchmarks are still limited to single tasks with limited generalization capabilities. In this work, we introduce a comprehensive benchmark and an autonomous learning framework, RoboCoder aimed at enhancing the generalization capabilities of robots in complex environments. Unlike traditional methods that focus on single-task learning, our research emphasizes the development of a general-purpose robotic coding algorithm that enables robots to leverage basic skills to tackle increasingly complex tasks. The newly proposed benchmark consists of 80 manually designed tasks across 7 distinct entities, testing the models' ability to learn from minimal initial mastery. Initial testing revealed that even advanced models like GPT-4 could only achieve a 47% pass rate in three-shot scenarios with humanoid entities. To address these limitations, the RoboCoder framework integrates Large Language Models (LLMs) with a dynamic learning system that uses real-time environmental feedback to continuously update and refine action codes. This adaptive method showed a remarkable improvement, achieving a 36% relative improvement. Our codes will be released.