 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Fact from Sentiment: A Dynamic Conflict-Consensus Framework for Multimodal Fake News Detection
Dec 19, 2025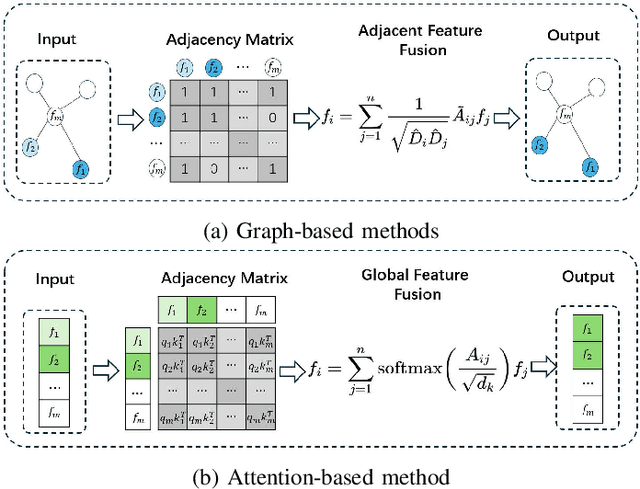
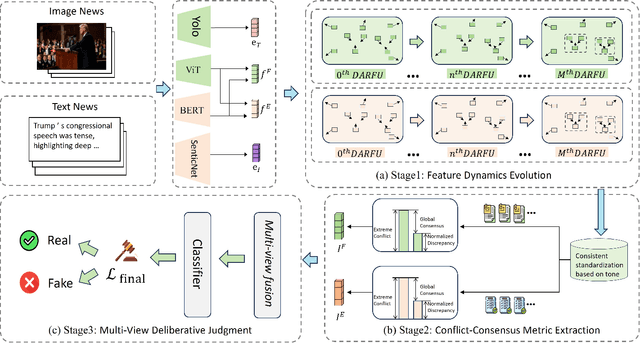
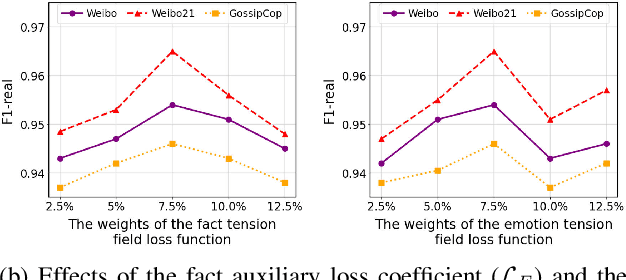
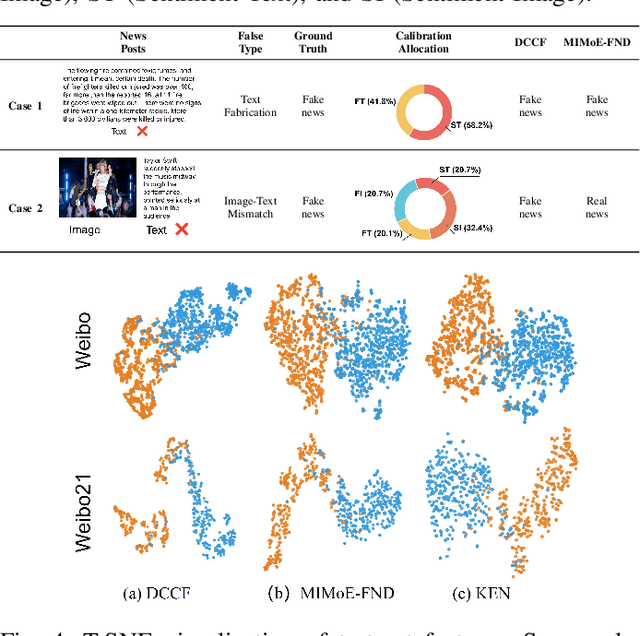
Prevalent multimodal fake news detection relies on consistency-based fusion, yet this paradigm fundamentally misinterprets critical cross-modal discrepancies as noise, leading to over-smoothing, which dilutes critical evidence of fabrication. Mainstream consistency-based fusion inherently minimizes feature discrepancies to align modalities, yet this approach fundamentally fails because it inadvertently smoothes out the subtle cross-modal contradictions that serve as the primary evidence of fabrication. To address this, we propose the Dynamic Conflict-Consensus Framework (DCCF), an inconsistency-seeking paradigm designed to amplify rather than suppress contradictions. First, DCCF decouples inputs into independent Fact and Sentiment spaces to distinguish objective mismatches from emotional dissonance. Second, we employ physics-inspired feature dynamics to iteratively polarize these representations, actively extracting maximally informative conflicts. Finally, a conflict-consensus mechanism standardizes these local discrepancies against the global context for robust deliberative judgment.Extensive experiments conducted on three real world datasets demonstrate that DCCF consistently outperforms state-of-the-art baselines, achieving an average accuracy improvement of 3.52\%.
Flexible-weighted Chamfer Distance: Enhanced Objective Function for Point Cloud Completion
May 20, 2025Chamfer Distance (CD) comprises two components that can evaluate the global distribution and local performance of generated point clouds, making it widely utilized as a similarity measure between generated and target point clouds in point cloud completion tasks. Additionally, CD's computational efficiency has led to its frequent application as an objective function for guiding point cloud generation. However, using CD directly as an objective function with fixed equal weights for its two components can often result in seemingly high overall performance (i.e., low CD score), while failing to achieve a good global distribution. This is typically reflected in high Earth Mover's Distance (EMD) and Decomposed Chamfer Distance (DCD) scores, alongside poor human assessments. To address this issue, we propose a Flexible-Weighted Chamfer Distance (FCD) to guide point cloud generation. FCD assigns a higher weight to the global distribution component of CD and incorporates a flexible weighting strategy to adjust the balance between the two components, aiming to improve global distribution while maintaining robust overall performance. Experimental results on two state-of-the-art networks demonstrate that our method achieves superior results across multiple evaluation metrics, including CD, EMD, DCD, and F-Score, as well as in human evaluations.
LLM-CARD: Towards a Description and Landscape of Large Language Models
Sep 25, 2024With the rapid growth of the Natural Language Processing (NLP) field, a vast variety of Large Language Models (LLMs) continue to emerge for diverse NLP tasks. As an increasing number of papers are presented, researchers and developers face the challenge of information overload. Thus, it is particularly important to develop a system that can automatically extract and organise key information about LLMs from academic papers (\textbf{LLM model card}). This work is to develop such a pioneer system by using Named Entity Recognition (\textbf{NER}) and Relation Extraction (\textbf{RE}) methods that automatically extract key information about large language models from the papers, helping researchers to efficiently access information about LLMs. These features include model \textit{licence}, model \textit{name}, and model \textit{application}. With these features, we can form a model card for each paper. \textbf{Data-contribution} wise, 106 academic papers were processed by defining three dictionaries - LLMs name, licence, and application. 11,051 sentences were extracted through dictionary lookup, and the dataset was constructed through manual review of the final selection of 129 sentences that have a link between the name and the licence, and 106 sentences that have a link between the model name and the application.
Deep Learning-based 3D Point Cloud Classification: A Systematic Survey and Outlook
Nov 05, 2023In recent years, point cloud representation has become one of the research hotspots in the field of computer vision, and has been widely used in many fields, such as autonomous driving, virtual reality, robotics, etc. Although deep learning techniques have achieved great success in processing regular structured 2D grid image data, there are still great challenges in processing irregular, unstructured point cloud data. Point cloud classification is the basis of point cloud analysis, and many deep learning-based methods have been widely used in this task. Therefore, the purpose of this paper is to provide researchers in this field with the latest research progress and future trends. First, we introduce point cloud acquisition, characteristics, and challenges. Second, we review 3D data representations, storage formats, and commonly used datasets for point cloud classification. We then summarize deep learning-based methods for point cloud classification and complement recent research work. Next, we compare and analyze the performance of the main methods. Finally, we discuss some challenges and future directions for point cloud classification.
Exploring vision transformer layer choosing for semantic segmentation
May 02, 2023Extensive work has demonstrated the effectiveness of Vision Transformers. The plain Vision Transformer tends to obtain multi-scale features by selecting fixed layers, or the last layer of features aiming to achieve higher performance in dense prediction tasks. However, this selection is often based on manual operation. And different samples often exhibit different features at different layers (e.g., edge, structure, texture, detail, etc.). This requires us to seek a dynamic adaptive fusion method to filter different layer features. In this paper, unlike previous encoder and decoder work, we design a neck network for adaptive fusion and feature selection, called ViTController. We validate the effectiveness of our method on different datasets and models and surpass previous state-of-the-art methods. Finally, our method can also be used as a plug-in module and inserted into different networks.
AxWin Transformer: A Context-Aware Vision Transformer Backbone with Axial Windows
May 02, 2023



Recently Transformer has shown good performance in several vision tasks due to its powerful modeling capabilities. To reduce the quadratic complexity caused by the attention, some outstanding work restricts attention to local regions or extends axial interactions. However, these methos often lack the interaction of local and global information, balancing coarse and fine-grained information. To address this problem, we propose AxWin Attention, which models context information in both local windows and axial views. Based on the AxWin Attention, we develop a context-aware vision transformer backbone, named AxWin Transformer, which outperforming the state-of-the-art methods in both classification and downstream segmentation and detection tasks.
PRSeg: A Lightweight Patch Rotate MLP Decoder for Semantic Segmentation
May 01, 2023The lightweight MLP-based decoder has become increasingly promising for semantic segmentation. However, the channel-wise MLP cannot expand the receptive fields, lacking the context modeling capacity, which is critical to semantic segmentation. In this paper, we propose a parametric-free patch rotate operation to reorganize the pixels spatially. It first divides the feature map into multiple groups and then rotates the patches within each group. Based on the proposed patch rotate operation, we design a novel segmentation network, named PRSeg, which includes an off-the-shelf backbone and a lightweight Patch Rotate MLP decoder containing multiple Dynamic Patch Rotate Blocks (DPR-Blocks). In each DPR-Block, the fully connected layer is performed following a Patch Rotate Module (PRM) to exchange spatial information between pixels. Specifically, in PRM, the feature map is first split into the reserved part and rotated part along the channel dimension according to the predicted probability of the Dynamic Channel Selection Module (DCSM), and our proposed patch rotate operation is only performed on the rotated part. Extensive experiments on ADE20K, Cityscapes and COCO-Stuff 10K datasets prove the effectiveness of our approach. We expect that our PRSeg can promote the development of MLP-based decoder in semantic segmentation.
HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Classification
Sep 21, 2022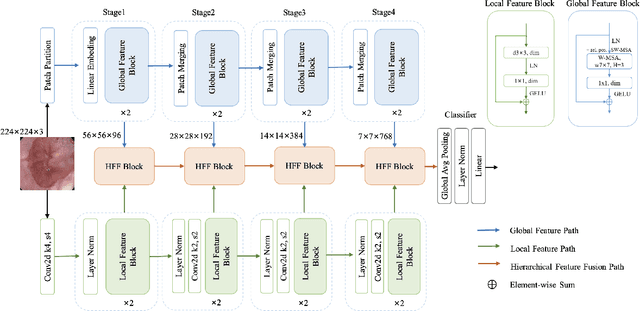
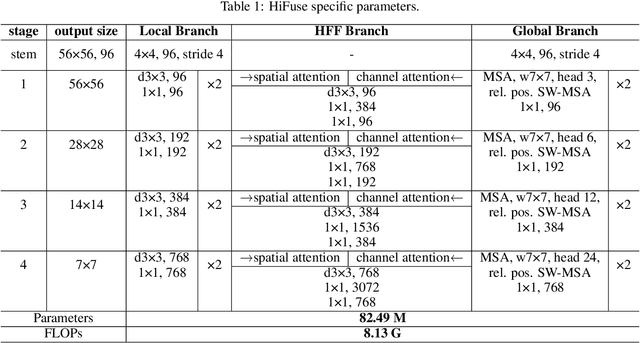
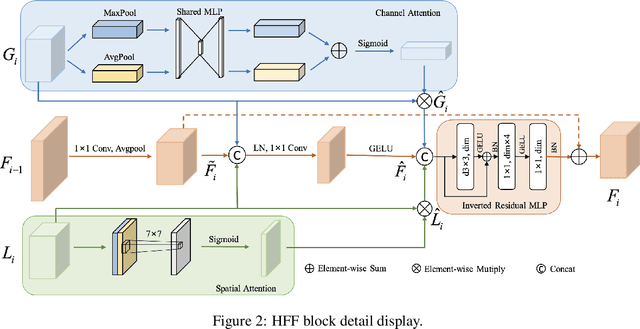
Medical image classification has developed rapidly under the impetus of the convolutional neural network (CNN). Due to the fixed size of the receptive field of the convolution kernel, it is difficult to capture the global features of medical images. Although the self-attention-based Transformer can model long-range dependencies, it has high computational complexity and lacks local inductive bias. Much research has demonstrated that global and local features are crucial for image classification. However, medical images have a lot of noisy, scattered features, intra-class variation, and inter-class similarities. This paper proposes a three-branch hierarchical multi-scale feature fusion network structure termed as HiFuse for medical image classification as a new method. It can fuse the advantages of Transformer and CNN from multi-scale hierarchies without destroying the respective modeling so as to improve the classification accuracy of various medical images. A parallel hierarchy of local and global feature blocks is designed to efficiently extract local features and global representations at various semantic scales, with the flexibility to model at different scales and linear computational complexity relevant to image size. Moreover, an adaptive hierarchical feature fusion block (HFF block) is designed to utilize the features obtained at different hierarchical levels comprehensively. The HFF block contains spatial attention, channel attention, residual inverted MLP, and shortcut to adaptively fuse semantic information between various scale features of each branch. The accuracy of our proposed model on the ISIC2018 dataset is 7.6% higher than baseline, 21.5% on the Covid-19 dataset, and 10.4% on the Kvasir dataset. Compared with other advanced models, the HiFuse model performs the best. Our code is open-source and available from https://github.com/huoxiangzuo/HiFuse.
StructToken : Rethinking Semantic Segmentation with Structural Prior
Apr 01, 2022


In this paper, we present structure token (StructToken), a new paradigm for semantic segmentation. From a perspective on semantic segmentation as per-pixel classification, the previous deep learning-based methods learn the per-pixel representation first through an encoder and a decoder head and then classify each pixel representation to a specific category to obtain the semantic masks. Differently, we propose a structure-aware algorithm that takes structural information as prior to predict semantic masks directly without per-pixel classification. Specifically, given an input image, the learnable structure token interacts with the image representations to reason the final semantic masks. Three interaction approaches are explored and the results not only outperform the state-of-the-art methods but also contain more structural information. Experiments are conducted on three widely used datasets including ADE20k, Cityscapes, and COCO-Stuff 10K. We hope that structure token could serve as an alternative for semantic segmentation and inspire future research.
Feature Selective Transformer for Semantic Image Segmentation
Apr 01, 2022
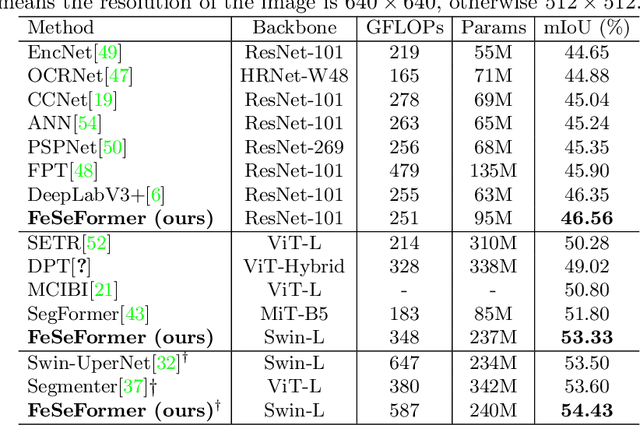
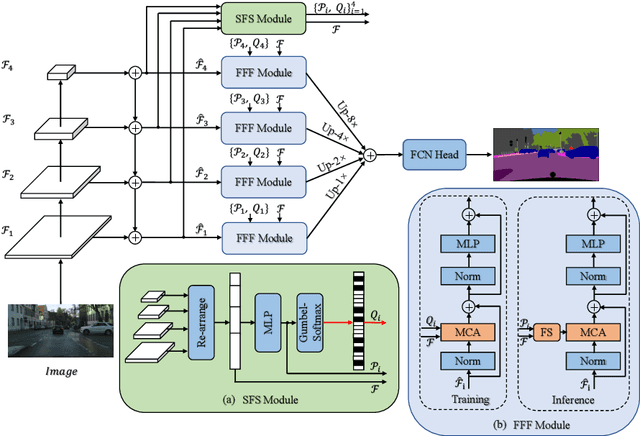
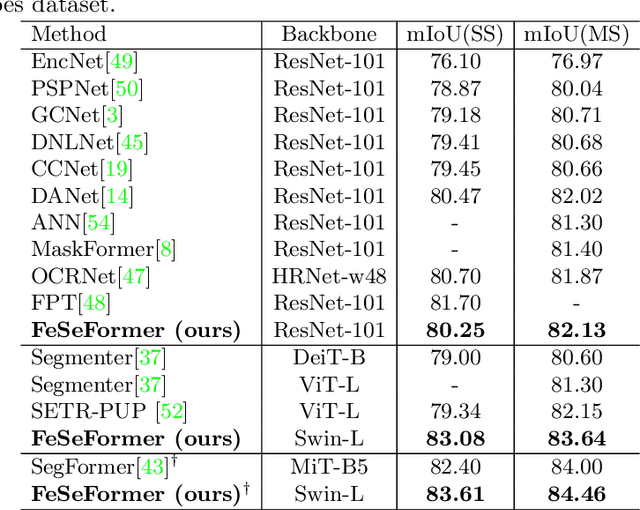
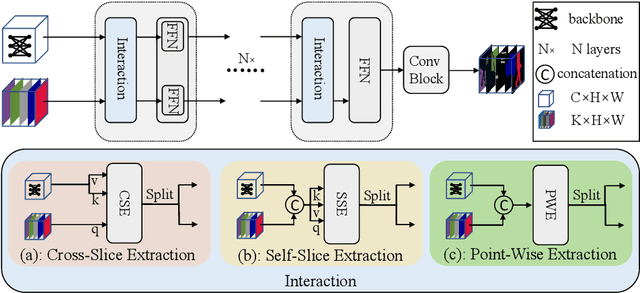
Recently, it has attracted more and more attentions to fuse multi-scale features for semantic image segmentation. Various works were proposed to employ progressive local or global fusion, but the feature fusions are not rich enough for modeling multi-scale context features. In this work, we focus on fusing multi-scale features from Transformer-based backbones for semantic segmentation, and propose a Feature Selective Transformer (FeSeFormer), which aggregates features from all scales (or levels) for each query feature. Specifically, we first propose a Scale-level Feature Selection (SFS) module, which can choose an informative subset from the whole multi-scale feature set for each scale, where those features that are important for the current scale (or level) are selected and the redundant are discarded. Furthermore, we propose a Full-scale Feature Fusion (FFF) module, which can adaptively fuse features of all scales for queries. Based on the proposed SFS and FFF modules, we develop a Feature Selective Transformer (FeSeFormer), and evaluate our FeSeFormer on four challenging semantic segmentation benchmarks, including PASCAL Context, ADE20K, COCO-Stuff 10K, and Cityscapes, outperforming the state-of-the-art.