 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructToken : Rethinking Semantic Segmentation with Structural Prior
Paper and Code
Apr 01, 2022

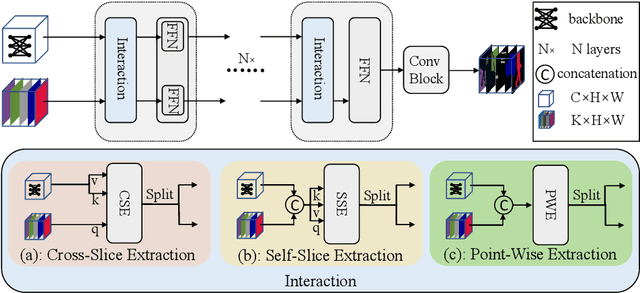

In this paper, we present structure token (StructToken), a new paradigm for semantic segmentation. From a perspective on semantic segmentation as per-pixel classification, the previous deep learning-based methods learn the per-pixel representation first through an encoder and a decoder head and then classify each pixel representation to a specific category to obtain the semantic masks. Differently, we propose a structure-aware algorithm that takes structural information as prior to predict semantic masks directly without per-pixel classification. Specifically, given an input image, the learnable structure token interacts with the image representations to reason the final semantic masks. Three interaction approaches are explored and the results not only outperform the state-of-the-art methods but also contain more structural information. Experiments are conducted on three widely used datasets including ADE20k, Cityscapes, and COCO-Stuff 10K. We hope that structure token could serve as an alternative for semantic segmentation and inspire future research.