 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring vision transformer layer choosing for semantic segmentation
May 02, 2023
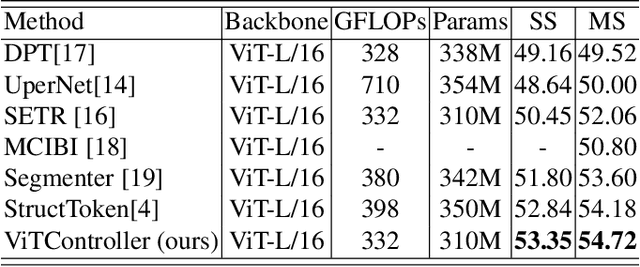


Extensive work has demonstrated the effectiveness of Vision Transformers. The plain Vision Transformer tends to obtain multi-scale features by selecting fixed layers, or the last layer of features aiming to achieve higher performance in dense prediction tasks. However, this selection is often based on manual operation. And different samples often exhibit different features at different layers (e.g., edge, structure, texture, detail, etc.). This requires us to seek a dynamic adaptive fusion method to filter different layer features. In this paper, unlike previous encoder and decoder work, we design a neck network for adaptive fusion and feature selection, called ViTController. We validate the effectiveness of our method on different datasets and models and surpass previous state-of-the-art methods. Finally, our method can also be used as a plug-in module and inserted into different networks.
AxWin Transformer: A Context-Aware Vision Transformer Backbone with Axial Windows
May 02, 2023



Recently Transformer has shown good performance in several vision tasks due to its powerful modeling capabilities. To reduce the quadratic complexity caused by the attention, some outstanding work restricts attention to local regions or extends axial interactions. However, these methos often lack the interaction of local and global information, balancing coarse and fine-grained information. To address this problem, we propose AxWin Attention, which models context information in both local windows and axial views. Based on the AxWin Attention, we develop a context-aware vision transformer backbone, named AxWin Transformer, which outperforming the state-of-the-art methods in both classification and downstream segmentation and detection tasks.
UniNeXt: Exploring A Unified Architecture for Vision Recognition
May 01, 2023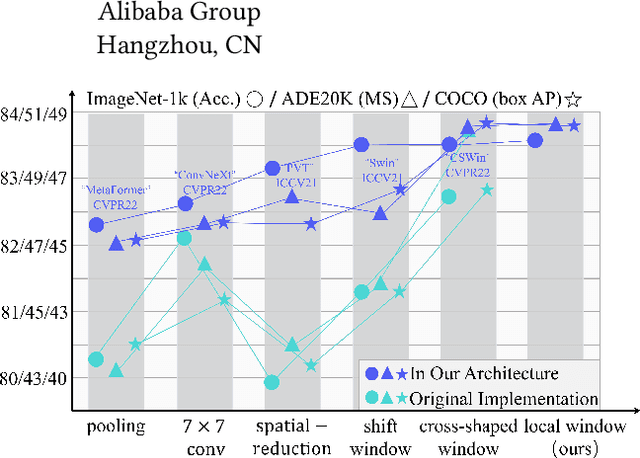

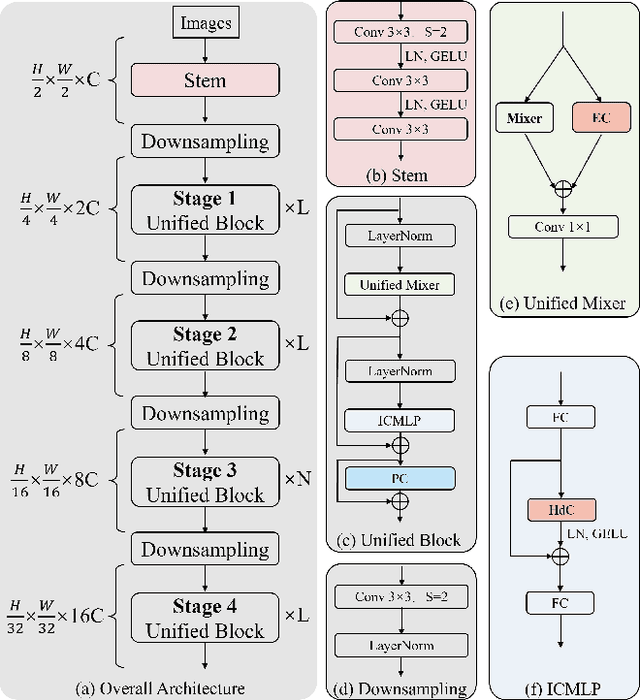

Vision Transformers have shown great potential in computer vision tasks. Most recent works have focused on elaborating the spatial token mixer for performance gains. However, we observe that a well-designed general architecture can significantly improve the performance of the entire backbone, regardless of which spatial token mixer is equipped. In this paper, we propose UniNeXt, an improved general architecture for the vision backbone. To verify its effectiveness, we instantiate the spatial token mixer with various typical and modern designs, including both convolution and attention modules. Compared with the architecture in which they are first proposed, our UniNeXt architecture can steadily boost the performance of all the spatial token mixers, and narrows the performance gap among them. Surprisingly, our UniNeXt equipped with naive local window attention even outperforms the previous state-of-the-art. Interestingly, the ranking of these spatial token mixers also changes under our UniNeXt, suggesting that an excellent spatial token mixer may be stifled due to a suboptimal general architecture, which further shows the importance of the study on the general architecture of vision backbone. All models and codes will be publicly available.
PRSeg: A Lightweight Patch Rotate MLP Decoder for Semantic Segmentation
May 01, 2023



The lightweight MLP-based decoder has become increasingly promising for semantic segmentation. However, the channel-wise MLP cannot expand the receptive fields, lacking the context modeling capacity, which is critical to semantic segmentation. In this paper, we propose a parametric-free patch rotate operation to reorganize the pixels spatially. It first divides the feature map into multiple groups and then rotates the patches within each group. Based on the proposed patch rotate operation, we design a novel segmentation network, named PRSeg, which includes an off-the-shelf backbone and a lightweight Patch Rotate MLP decoder containing multiple Dynamic Patch Rotate Blocks (DPR-Blocks). In each DPR-Block, the fully connected layer is performed following a Patch Rotate Module (PRM) to exchange spatial information between pixels. Specifically, in PRM, the feature map is first split into the reserved part and rotated part along the channel dimension according to the predicted probability of the Dynamic Channel Selection Module (DCSM), and our proposed patch rotate operation is only performed on the rotated part. Extensive experiments on ADE20K, Cityscapes and COCO-Stuff 10K datasets prove the effectiveness of our approach. We expect that our PRSeg can promote the development of MLP-based decoder in semantic segmentation.
StructToken : Rethinking Semantic Segmentation with Structural Prior
Apr 01, 2022


In this paper, we present structure token (StructToken), a new paradigm for semantic segmentation. From a perspective on semantic segmentation as per-pixel classification, the previous deep learning-based methods learn the per-pixel representation first through an encoder and a decoder head and then classify each pixel representation to a specific category to obtain the semantic masks. Differently, we propose a structure-aware algorithm that takes structural information as prior to predict semantic masks directly without per-pixel classification. Specifically, given an input image, the learnable structure token interacts with the image representations to reason the final semantic masks. Three interaction approaches are explored and the results not only outperform the state-of-the-art methods but also contain more structural information. Experiments are conducted on three widely used datasets including ADE20k, Cityscapes, and COCO-Stuff 10K. We hope that structure token could serve as an alternative for semantic segmentation and inspire future research.
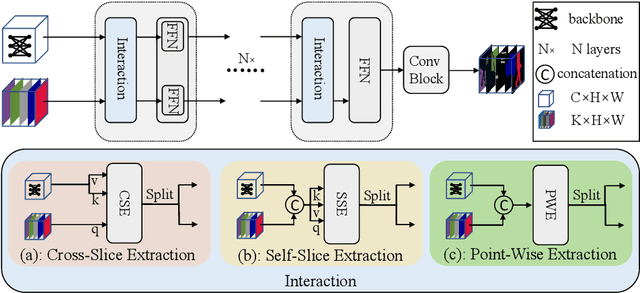
Feature Selective Transformer for Semantic Image Segmentation
Apr 01, 2022
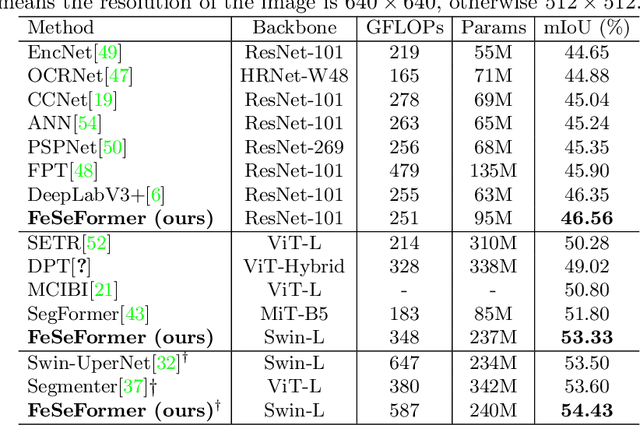
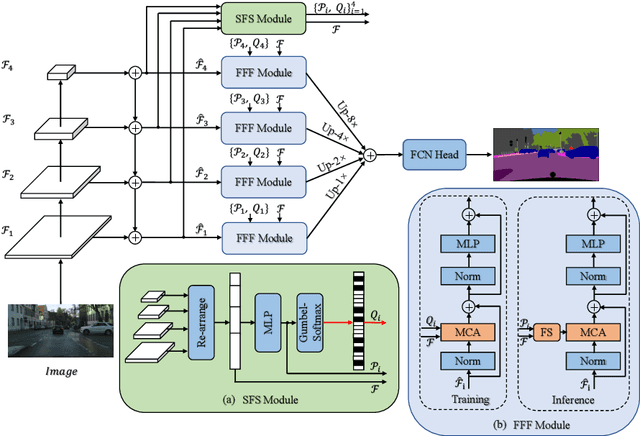
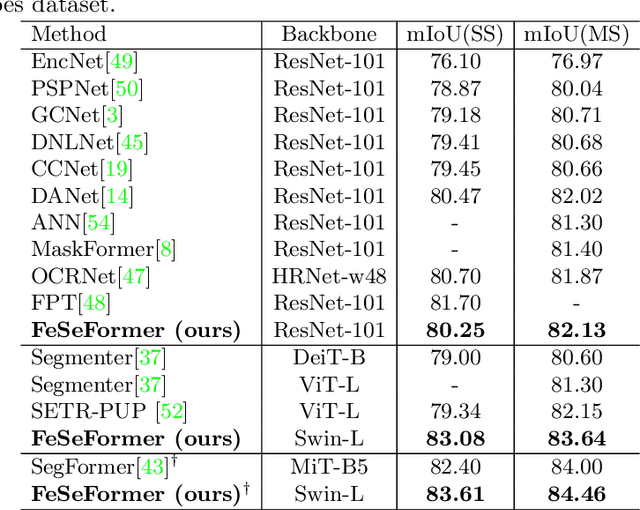
Recently, it has attracted more and more attentions to fuse multi-scale features for semantic image segmentation. Various works were proposed to employ progressive local or global fusion, but the feature fusions are not rich enough for modeling multi-scale context features. In this work, we focus on fusing multi-scale features from Transformer-based backbones for semantic segmentation, and propose a Feature Selective Transformer (FeSeFormer), which aggregates features from all scales (or levels) for each query feature. Specifically, we first propose a Scale-level Feature Selection (SFS) module, which can choose an informative subset from the whole multi-scale feature set for each scale, where those features that are important for the current scale (or level) are selected and the redundant are discarded. Furthermore, we propose a Full-scale Feature Fusion (FFF) module, which can adaptively fuse features of all scales for queries. Based on the proposed SFS and FFF modules, we develop a Feature Selective Transformer (FeSeFormer), and evaluate our FeSeFormer on four challenging semantic segmentation benchmarks, including PASCAL Context, ADE20K, COCO-Stuff 10K, and Cityscapes, outperforming the state-of-the-art.
Fully Transformer Networks for Semantic Image Segmentation
Jun 08, 2021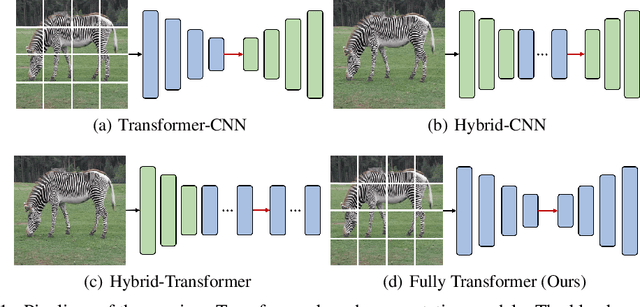



Transformers have shown impressive performance in various natural language processing and computer vision tasks, due to the capability of modeling long-range dependencies. Recent progress has demonstrated to combine such transformers with CNN-based semantic image segmentation models is very promising. However, it is not well studied yet on how well a pure transformer based approach can achieve for image segmentation. In this work, we explore a novel framework for semantic image segmentation, which is encoder-decoder based Fully Transformer Networks (FTN). Specifically, we first propose a Pyramid Group Transformer (PGT) as the encoder for progressively learning hierarchical features, while reducing the computation complexity of the standard visual transformer(ViT). Then, we propose a Feature Pyramid Transformer (FPT) to fuse semantic-level and spatial-level information from multiple levels of the PGT encoder for semantic image segmentation. Surprisingly, this simple baseline can achieve new state-of-the-art results on multiple challenging semantic segmentation benchmarks, including PASCAL Context, ADE20K and COCO-Stuff. The source code will be released upon the publication of this work.