 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeapAlign: Post-Training Flow Matching Models at Any Generation Step by Building Two-Step Trajectories
Apr 16, 2026This paper focuses on the alignment of flow matching models with human preferences. A promising way is fine-tuning by directly backpropagating reward gradients through the differentiable generation process of flow matching. However, backpropagating through long trajectories results in prohibitive memory costs and gradient explosion. Therefore, direct-gradient methods struggle to update early generation steps, which are crucial for determining the global structure of the final image. To address this issue, we introduce LeapAlign, a fine-tuning method that reduces computational cost and enables direct gradient propagation from reward to early generation steps. Specifically, we shorten the long trajectory into only two steps by designing two consecutive leaps, each skipping multiple ODE sampling steps and predicting future latents in a single step. By randomizing the start and end timesteps of the leaps, LeapAlign leads to efficient and stable model updates at any generation step. To better use such shortened trajectories, we assign higher training weights to those that are more consistent with the long generation path. To further enhance gradient stability, we reduce the weights of gradient terms with large magnitude, instead of completely removing them as done in previous works. When fine-tuning the Flux model, LeapAlign consistently outperforms state-of-the-art GRPO-based and direct-gradient methods across various metrics, achieving superior image quality and image-text alignment.
Step-aware Preference Optimization: Aligning Preference with Denoising Performance at Each Step
Jun 06, 2024



Recently, Direct Preference Optimization (DPO) has extended its success from aligning large language models (LLMs) to aligning text-to-image diffusion models with human preferences. Unlike most existing DPO methods that assume all diffusion steps share a consistent preference order with the final generated images, we argue that this assumption neglects step-specific denoising performance and that preference labels should be tailored to each step's contribution. To address this limitation, we propose Step-aware Preference Optimization (SPO), a novel post-training approach that independently evaluates and adjusts the denoising performance at each step, using a step-aware preference model and a step-wise resampler to ensure accurate step-aware supervision. Specifically, at each denoising step, we sample a pool of images, find a suitable win-lose pair, and, most importantly, randomly select a single image from the pool to initialize the next denoising step. This step-wise resampler process ensures the next win-lose image pair comes from the same image, making the win-lose comparison independent of the previous step. To assess the preferences at each step, we train a separate step-aware preference model that can be applied to both noisy and clean images. Our experiments with Stable Diffusion v1.5 and SDXL demonstrate that SPO significantly outperforms the latest Diffusion-DPO in aligning generated images with complex, detailed prompts and enhancing aesthetics, while also achieving more than 20x times faster in training efficiency. Code and model: https://rockeycoss.github.io/spo.github.io/
Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
Mar 14, 2024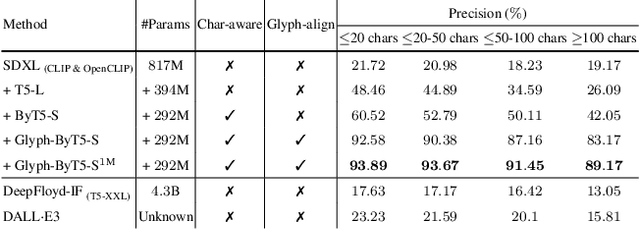

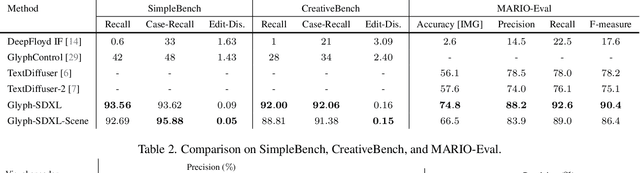

Visual text rendering poses a fundamental challenge for contemporary text-to-image generation models, with the core problem lying in text encoder deficiencies. To achieve accurate text rendering, we identify two crucial requirements for text encoders: character awareness and alignment with glyphs. Our solution involves crafting a series of customized text encoder, Glyph-ByT5, by fine-tuning the character-aware ByT5 encoder using a meticulously curated paired glyph-text dataset. We present an effective method for integrating Glyph-ByT5 with SDXL, resulting in the creation of the Glyph-SDXL model for design image generation. This significantly enhances text rendering accuracy, improving it from less than $20\%$ to nearly $90\%$ on our design image benchmark. Noteworthy is Glyph-SDXL's newfound ability for text paragraph rendering, achieving high spelling accuracy for tens to hundreds of characters with automated multi-line layouts. Finally, through fine-tuning Glyph-SDXL with a small set of high-quality, photorealistic images featuring visual text, we showcase a substantial improvement in scene text rendering capabilities in open-domain real images. These compelling outcomes aim to encourage further exploration in designing customized text encoders for diverse and challenging tasks.
Mask Frozen-DETR: High Quality Instance Segmentation with One GPU
Aug 07, 2023



In this paper, we aim to study how to build a strong instance segmenter with minimal training time and GPUs, as opposed to the majority of current approaches that pursue more accurate instance segmenter by building more advanced frameworks at the cost of longer training time and higher GPU requirements. To achieve this, we introduce a simple and general framework, termed Mask Frozen-DETR, which can convert any existing DETR-based object detection model into a powerful instance segmentation model. Our method only requires training an additional lightweight mask network that predicts instance masks within the bounding boxes given by a frozen DETR-based object detector. Remarkably, our method outperforms the state-of-the-art instance segmentation method Mask DINO in terms of performance on the COCO test-dev split (55.3% vs. 54.7%) while being over 10X times faster to train. Furthermore, all of our experiments can be trained using only one Tesla V100 GPU with 16 GB of memory, demonstrating the significant efficiency of our proposed framework.
StructToken : Rethinking Semantic Segmentation with Structural Prior
Apr 01, 2022

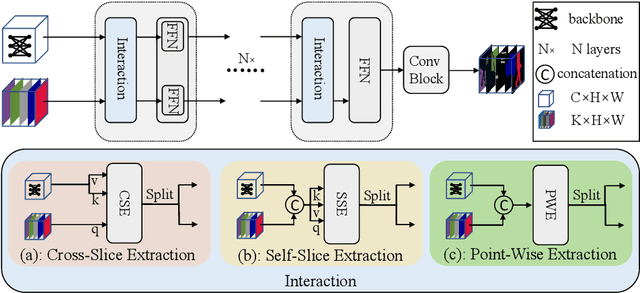

In this paper, we present structure token (StructToken), a new paradigm for semantic segmentation. From a perspective on semantic segmentation as per-pixel classification, the previous deep learning-based methods learn the per-pixel representation first through an encoder and a decoder head and then classify each pixel representation to a specific category to obtain the semantic masks. Differently, we propose a structure-aware algorithm that takes structural information as prior to predict semantic masks directly without per-pixel classification. Specifically, given an input image, the learnable structure token interacts with the image representations to reason the final semantic masks. Three interaction approaches are explored and the results not only outperform the state-of-the-art methods but also contain more structural information. Experiments are conducted on three widely used datasets including ADE20k, Cityscapes, and COCO-Stuff 10K. We hope that structure token could serve as an alternative for semantic segmentation and inspire future research.