 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical SVG Tokenization: Learning Compact Visual Programs for Scalable Vector Graphics Modeling
Apr 06, 2026Recent large language models have shifted SVG generation from differentiable rendering optimization to autoregressive program synthesis. However, existing approaches still rely on generic byte-level tokenization inherited from natural language processing, which poorly reflects the geometric structure of vector graphics. Numerical coordinates are fragmented into discrete symbols, destroying spatial relationships and introducing severe token redundancy, often leading to coordinate hallucination and inefficient long-sequence generation. To address these challenges, we propose HiVG, a hierarchical SVG tokenization framework tailored for autoregressive vector graphics generation. HiVG decomposes raw SVG strings into structured \textit{atomic tokens} and further compresses executable command--parameter groups into geometry-constrained \textit{segment tokens}, substantially improving sequence efficiency while preserving syntactic validity. To further mitigate spatial mismatch, we introduce a Hierarchical Mean--Noise (HMN) initialization strategy that injects numerical ordering signals and semantic priors into new token embeddings. Combined with a curriculum training paradigm that progressively increases program complexity, HiVG enables more stable learning of executable SVG programs. Extensive experiments on both text-to-SVG and image-to-SVG tasks demonstrate improved generation fidelity, spatial consistency, and sequence efficiency compared with conventional tokenization schemes.
Glyph-ByT5-v2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering
Jun 14, 2024



Recently, Glyph-ByT5 has achieved highly accurate visual text rendering performance in graphic design images. However, it still focuses solely on English and performs relatively poorly in terms of visual appeal. In this work, we address these two fundamental limitations by presenting Glyph-ByT5-v2 and Glyph-SDXL-v2, which not only support accurate visual text rendering for 10 different languages but also achieve much better aesthetic quality. To achieve this, we make the following contributions: (i) creating a high-quality multilingual glyph-text and graphic design dataset consisting of more than 1 million glyph-text pairs and 10 million graphic design image-text pairs covering nine other languages, (ii) building a multilingual visual paragraph benchmark consisting of 1,000 prompts, with 100 for each language, to assess multilingual visual spelling accuracy, and (iii) leveraging the latest step-aware preference learning approach to enhance the visual aesthetic quality. With the combination of these techniques, we deliver a powerful customized multilingual text encoder, Glyph-ByT5-v2, and a strong aesthetic graphic generation model, Glyph-SDXL-v2, that can support accurate spelling in 10 different languages. We perceive our work as a significant advancement, considering that the latest DALL-E3 and Ideogram 1.0 still struggle with the multilingual visual text rendering task.
Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
Mar 14, 2024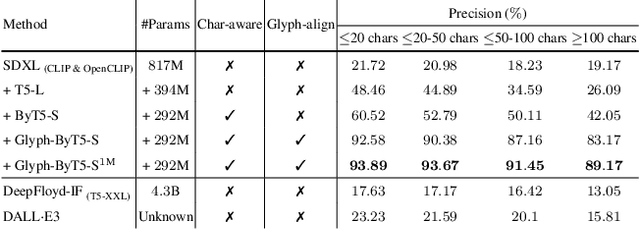

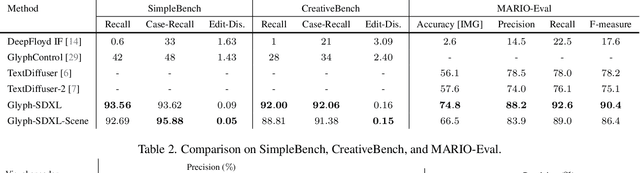

Visual text rendering poses a fundamental challenge for contemporary text-to-image generation models, with the core problem lying in text encoder deficiencies. To achieve accurate text rendering, we identify two crucial requirements for text encoders: character awareness and alignment with glyphs. Our solution involves crafting a series of customized text encoder, Glyph-ByT5, by fine-tuning the character-aware ByT5 encoder using a meticulously curated paired glyph-text dataset. We present an effective method for integrating Glyph-ByT5 with SDXL, resulting in the creation of the Glyph-SDXL model for design image generation. This significantly enhances text rendering accuracy, improving it from less than $20\%$ to nearly $90\%$ on our design image benchmark. Noteworthy is Glyph-SDXL's newfound ability for text paragraph rendering, achieving high spelling accuracy for tens to hundreds of characters with automated multi-line layouts. Finally, through fine-tuning Glyph-SDXL with a small set of high-quality, photorealistic images featuring visual text, we showcase a substantial improvement in scene text rendering capabilities in open-domain real images. These compelling outcomes aim to encourage further exploration in designing customized text encoders for diverse and challenging tasks.
Rank-DETR for High Quality Object Detection
Oct 19, 2023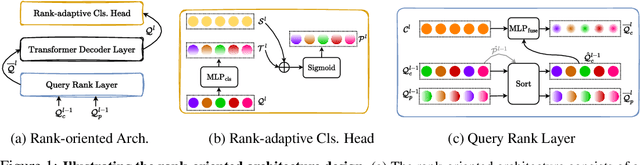


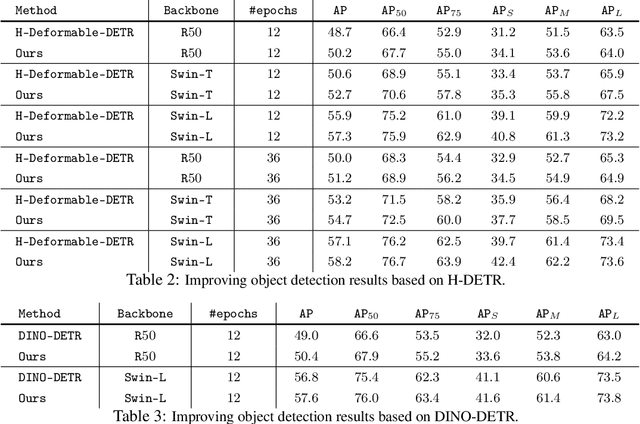
Modern detection transformers (DETRs) use a set of object queries to predict a list of bounding boxes, sort them by their classification confidence scores, and select the top-ranked predictions as the final detection results for the given input image. A highly performant object detector requires accurate ranking for the bounding box predictions. For DETR-based detectors, the top-ranked bounding boxes suffer from less accurate localization quality due to the misalignment between classification scores and localization accuracy, thus impeding the construction of high-quality detectors. In this work, we introduce a simple and highly performant DETR-based object detector by proposing a series of rank-oriented designs, combinedly called Rank-DETR. Our key contributions include: (i) a rank-oriented architecture design that can prompt positive predictions and suppress the negative ones to ensure lower false positive rates, as well as (ii) a rank-oriented loss function and matching cost design that prioritizes predictions of more accurate localization accuracy during ranking to boost the AP under high IoU thresholds. We apply our method to improve the recent SOTA methods (e.g., H-DETR and DINO-DETR) and report strong COCO object detection results when using different backbones such as ResNet-$50$, Swin-T, and Swin-L, demonstrating the effectiveness of our approach. Code is available at \url{https://github.com/LeapLabTHU/Rank-DETR}.
Revisiting DETR Pre-training for Object Detection
Aug 02, 2023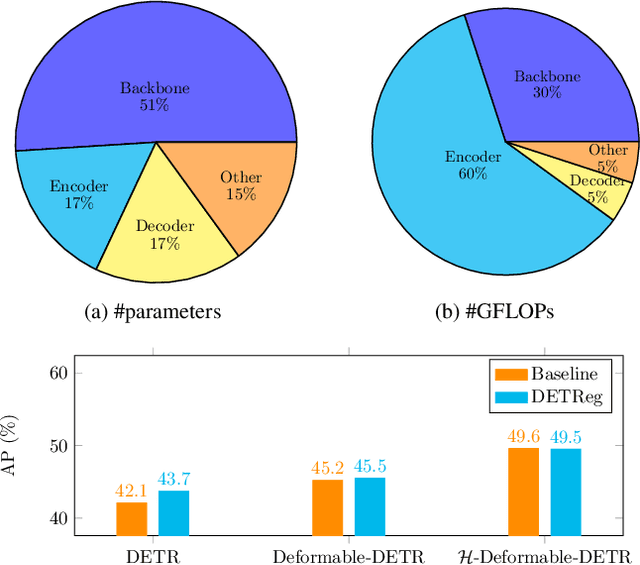
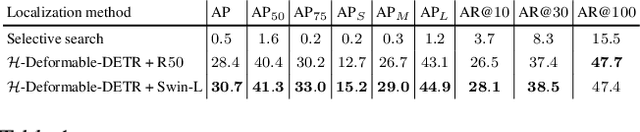

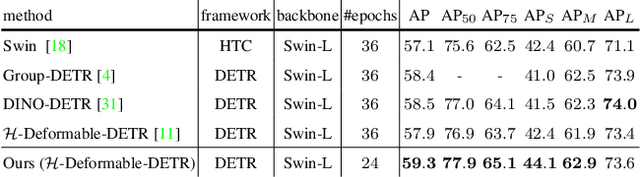
Motivated by that DETR-based approaches have established new records on COCO detection and segmentation benchmarks, many recent endeavors show increasing interest in how to further improve DETR-based approaches by pre-training the Transformer in a self-supervised manner while keeping the backbone frozen. Some studies already claimed significant improvements in accuracy. In this paper, we take a closer look at their experimental methodology and check if their approaches are still effective on the very recent state-of-the-art such as $\mathcal{H}$-Deformable-DETR. We conduct thorough experiments on COCO object detection tasks to study the influence of the choice of pre-training datasets, localization, and classification target generation schemes. Unfortunately, we find the previous representative self-supervised approach such as DETReg, fails to boost the performance of the strong DETR-based approaches on full data regimes. We further analyze the reasons and find that simply combining a more accurate box predictor and Objects$365$ benchmark can significantly improve the results in follow-up experiments. We demonstrate the effectiveness of our approach by achieving strong object detection results of AP=$59.3\%$ on COCO val set, which surpasses $\mathcal{H}$-Deformable-DETR + Swin-L by +$1.4\%$. Last, we generate a series of synthetic pre-training datasets by combining the very recent image-to-text captioning models (LLaVA) and text-to-image generative models (SDXL). Notably, pre-training on these synthetic datasets leads to notable improvements in object detection performance. Looking ahead, we anticipate substantial advantages through the future expansion of the synthetic pre-training dataset.
Expediting Large-Scale Vision Transformer for Dense Prediction without Fine-tuning
Oct 03, 2022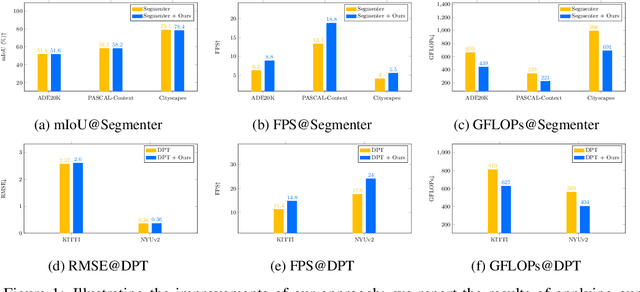

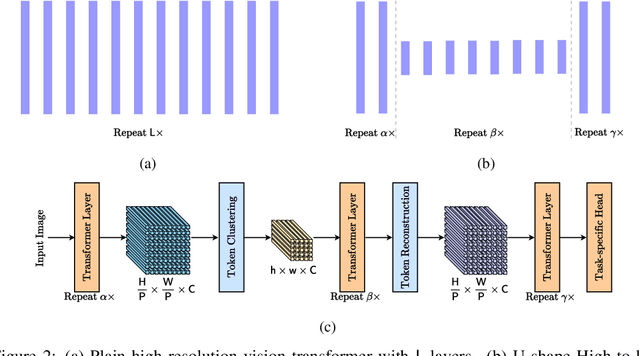
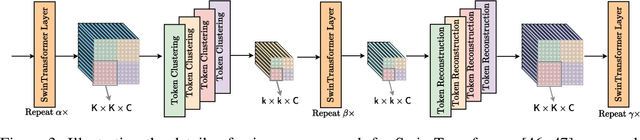
Vision transformers have recently achieved competitive results across various vision tasks but still suffer from heavy computation costs when processing a large number of tokens. Many advanced approaches have been developed to reduce the total number of tokens in large-scale vision transformers, especially for image classification tasks. Typically, they select a small group of essential tokens according to their relevance with the class token, then fine-tune the weights of the vision transformer. Such fine-tuning is less practical for dense prediction due to the much heavier computation and GPU memory cost than image classification. In this paper, we focus on a more challenging problem, i.e., accelerating large-scale vision transformers for dense prediction without any additional re-training or fine-tuning. In response to the fact that high-resolution representations are necessary for dense prediction, we present two non-parametric operators, a token clustering layer to decrease the number of tokens and a token reconstruction layer to increase the number of tokens. The following steps are performed to achieve this: (i) we use the token clustering layer to cluster the neighboring tokens together, resulting in low-resolution representations that maintain the spatial structures; (ii) we apply the following transformer layers only to these low-resolution representations or clustered tokens; and (iii) we use the token reconstruction layer to re-create the high-resolution representations from the refined low-resolution representations. The results obtained by our method are promising on five dense prediction tasks, including object detection, semantic segmentation, panoptic segmentation, instance segmentation, and depth estimation.