 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting DETR Pre-training for Object Detection
Paper and Code
Aug 02, 2023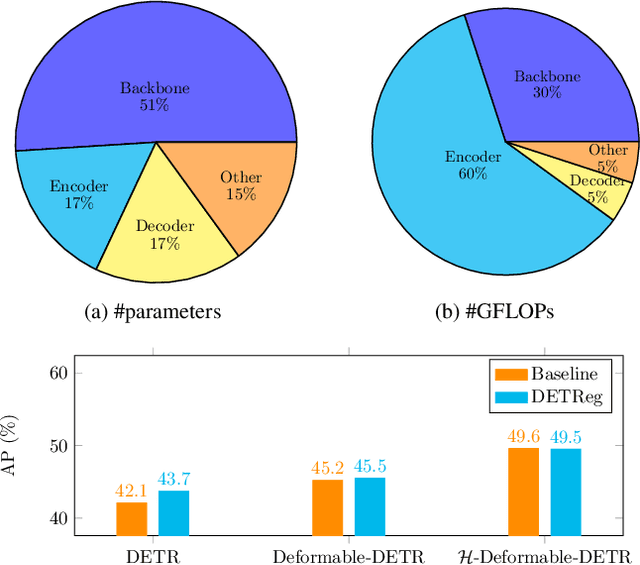
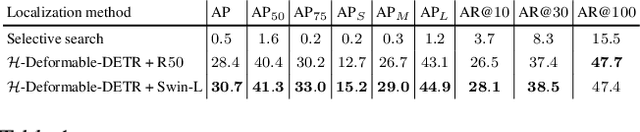

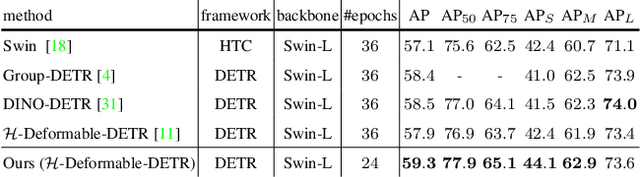
Motivated by that DETR-based approaches have established new records on COCO detection and segmentation benchmarks, many recent endeavors show increasing interest in how to further improve DETR-based approaches by pre-training the Transformer in a self-supervised manner while keeping the backbone frozen. Some studies already claimed significant improvements in accuracy. In this paper, we take a closer look at their experimental methodology and check if their approaches are still effective on the very recent state-of-the-art such as $\mathcal{H}$-Deformable-DETR. We conduct thorough experiments on COCO object detection tasks to study the influence of the choice of pre-training datasets, localization, and classification target generation schemes. Unfortunately, we find the previous representative self-supervised approach such as DETReg, fails to boost the performance of the strong DETR-based approaches on full data regimes. We further analyze the reasons and find that simply combining a more accurate box predictor and Objects$365$ benchmark can significantly improve the results in follow-up experiments. We demonstrate the effectiveness of our approach by achieving strong object detection results of AP=$59.3\%$ on COCO val set, which surpasses $\mathcal{H}$-Deformable-DETR + Swin-L by +$1.4\%$. Last, we generate a series of synthetic pre-training datasets by combining the very recent image-to-text captioning models (LLaVA) and text-to-image generative models (SDXL). Notably, pre-training on these synthetic datasets leads to notable improvements in object detection performance. Looking ahead, we anticipate substantial advantages through the future expansion of the synthetic pre-training dataset.