 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Audio-Visual Digital Twins with Smartphones
Dec 11, 2025Digital twins today are almost entirely visual, overlooking acoustics-a core component of spatial realism and interaction. We introduce AV-Twin, the first practical system that constructs editable audio-visual digital twins using only commodity smartphones. AV-Twin combines mobile RIR capture and a visual-assisted acoustic field model to efficiently reconstruct room acoustics. It further recovers per-surface material properties through differentiable acoustic rendering, enabling users to modify materials, geometry, and layout while automatically updating both audio and visuals. Together, these capabilities establish a practical path toward fully modifiable audio-visual digital twins for real-world environments.
Resounding Acoustic Fields with Reciprocity
Oct 23, 2025Achieving immersive auditory experiences in virtual environments requires flexible sound modeling that supports dynamic source positions. In this paper, we introduce a task called resounding, which aims to estimate room impulse responses at arbitrary emitter location from a sparse set of measured emitter positions, analogous to the relighting problem in vision. We leverage the reciprocity property and introduce Versa, a physics-inspired approach to facilitating acoustic field learning. Our method creates physically valid samples with dense virtual emitter positions by exchanging emitter and listener poses. We also identify challenges in deploying reciprocity due to emitter/listener gain patterns and propose a self-supervised learning approach to address them. Results show that Versa substantially improve the performance of acoustic field learning on both simulated and real-world datasets across different metrics. Perceptual user studies show that Versa can greatly improve the immersive spatial sound experience. Code, dataset and demo videos are available on the project website: https://waves.seas.upenn.edu/projects/versa.
Bootstrapping Autonomous Radars with Self-Supervised Learning
Dec 09, 2023



The perception of autonomous vehicles using radars has attracted increased research interest due its ability to operate in fog and bad weather. However, training radar models is hindered by the cost and difficulty of annotating large-scale radar data. To overcome this bottleneck, we propose a self-supervised learning framework to leverage the large amount of unlabeled radar data to pre-train radar-only embeddings for self-driving perception tasks. The proposed method combines radar-to-radar and radar-to-vision contrastive losses to learn a general representation from unlabeled radar heatmaps paired with their corresponding camera images. When used for downstream object detection, we demonstrate that the proposed self-supervision framework can improve the accuracy of state-of-the-art supervised baselines by 5.8% in mAP.
Rank-DETR for High Quality Object Detection
Oct 19, 2023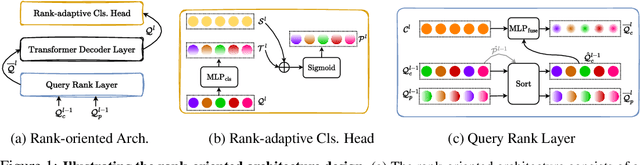


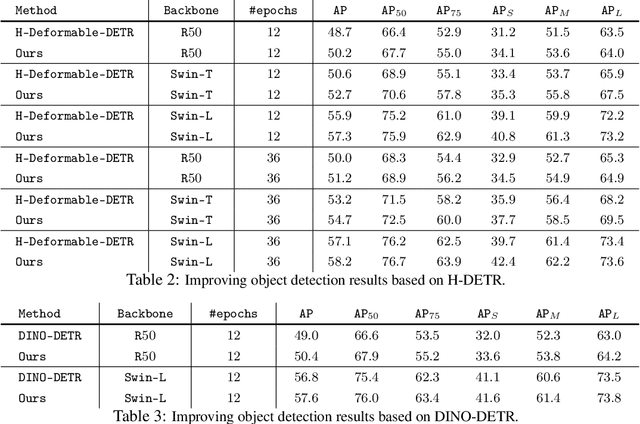
Modern detection transformers (DETRs) use a set of object queries to predict a list of bounding boxes, sort them by their classification confidence scores, and select the top-ranked predictions as the final detection results for the given input image. A highly performant object detector requires accurate ranking for the bounding box predictions. For DETR-based detectors, the top-ranked bounding boxes suffer from less accurate localization quality due to the misalignment between classification scores and localization accuracy, thus impeding the construction of high-quality detectors. In this work, we introduce a simple and highly performant DETR-based object detector by proposing a series of rank-oriented designs, combinedly called Rank-DETR. Our key contributions include: (i) a rank-oriented architecture design that can prompt positive predictions and suppress the negative ones to ensure lower false positive rates, as well as (ii) a rank-oriented loss function and matching cost design that prioritizes predictions of more accurate localization accuracy during ranking to boost the AP under high IoU thresholds. We apply our method to improve the recent SOTA methods (e.g., H-DETR and DINO-DETR) and report strong COCO object detection results when using different backbones such as ResNet-$50$, Swin-T, and Swin-L, demonstrating the effectiveness of our approach. Code is available at \url{https://github.com/LeapLabTHU/Rank-DETR}.
Revisiting DETR Pre-training for Object Detection
Aug 02, 2023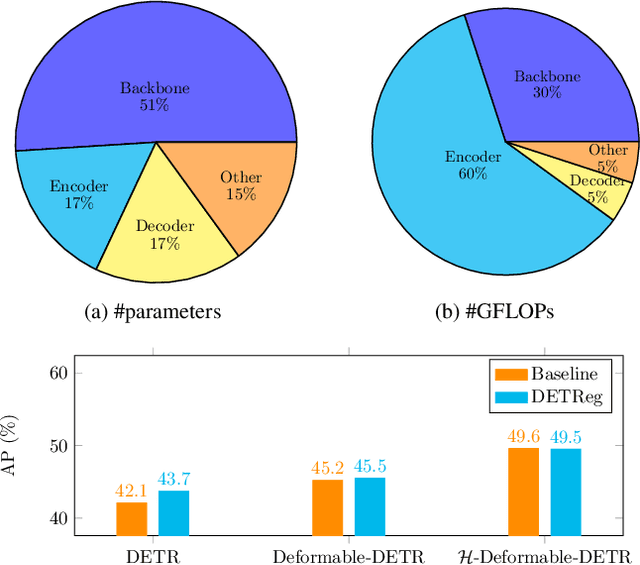
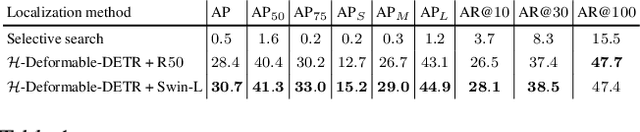

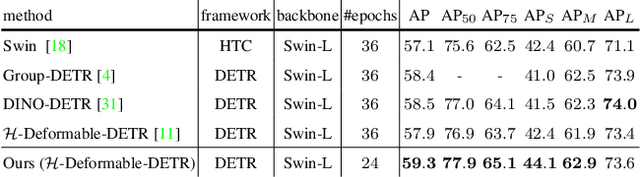
Motivated by that DETR-based approaches have established new records on COCO detection and segmentation benchmarks, many recent endeavors show increasing interest in how to further improve DETR-based approaches by pre-training the Transformer in a self-supervised manner while keeping the backbone frozen. Some studies already claimed significant improvements in accuracy. In this paper, we take a closer look at their experimental methodology and check if their approaches are still effective on the very recent state-of-the-art such as $\mathcal{H}$-Deformable-DETR. We conduct thorough experiments on COCO object detection tasks to study the influence of the choice of pre-training datasets, localization, and classification target generation schemes. Unfortunately, we find the previous representative self-supervised approach such as DETReg, fails to boost the performance of the strong DETR-based approaches on full data regimes. We further analyze the reasons and find that simply combining a more accurate box predictor and Objects$365$ benchmark can significantly improve the results in follow-up experiments. We demonstrate the effectiveness of our approach by achieving strong object detection results of AP=$59.3\%$ on COCO val set, which surpasses $\mathcal{H}$-Deformable-DETR + Swin-L by +$1.4\%$. Last, we generate a series of synthetic pre-training datasets by combining the very recent image-to-text captioning models (LLaVA) and text-to-image generative models (SDXL). Notably, pre-training on these synthetic datasets leads to notable improvements in object detection performance. Looking ahead, we anticipate substantial advantages through the future expansion of the synthetic pre-training dataset.