 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Autonomous Radars with Self-Supervised Learning
Dec 09, 2023



The perception of autonomous vehicles using radars has attracted increased research interest due its ability to operate in fog and bad weather. However, training radar models is hindered by the cost and difficulty of annotating large-scale radar data. To overcome this bottleneck, we propose a self-supervised learning framework to leverage the large amount of unlabeled radar data to pre-train radar-only embeddings for self-driving perception tasks. The proposed method combines radar-to-radar and radar-to-vision contrastive losses to learn a general representation from unlabeled radar heatmaps paired with their corresponding camera images. When used for downstream object detection, we demonstrate that the proposed self-supervision framework can improve the accuracy of state-of-the-art supervised baselines by 5.8% in mAP.
Benchmarking Learnt Radio Localisation under Distribution Shift
Oct 04, 2022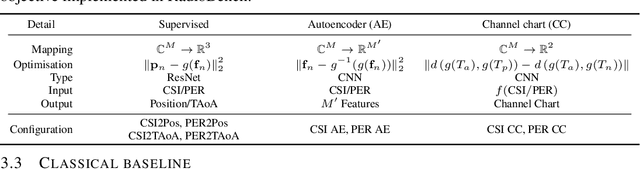
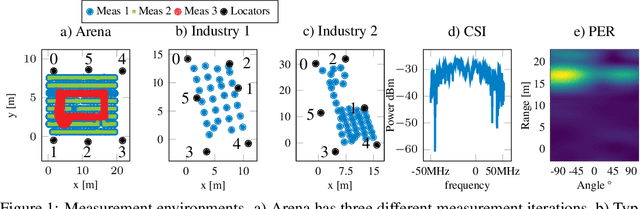
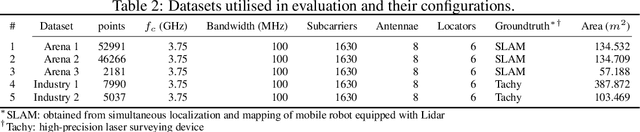

Deploying radio frequency (RF) localisation systems invariably entails non-trivial effort, particularly for the latest learning-based breeds. There has been little prior work on characterising and comparing how learnt localiser networks can be deployed in the field under real-world RF distribution shifts. In this paper, we present RadioBench: a suite of 8 learnt localiser nets from the state-of-the-art to study and benchmark their real-world deployability, utilising five novel industry-grade datasets. We train 10k models to analyse the inner workings of these learnt localiser nets and uncover their differing behaviours across three performance axes: (i) learning, (ii) proneness to distribution shift, and (iii) localisation. We use insights gained from this analysis to recommend best practices for the deployability of learning-based RF localisation under practical constraints.
Look, Radiate, and Learn: Self-supervised Localisation via Radio-Visual Correspondence
Jun 13, 2022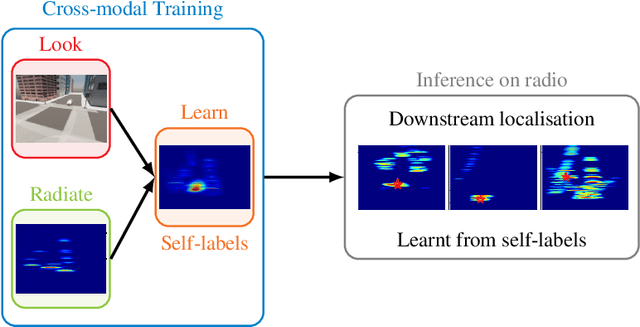

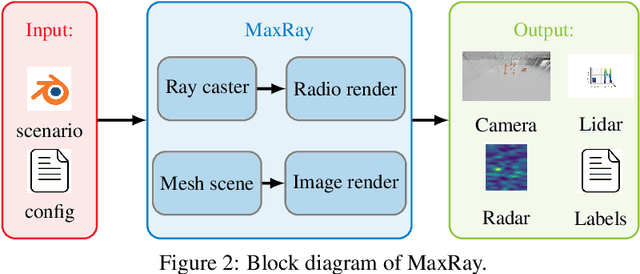

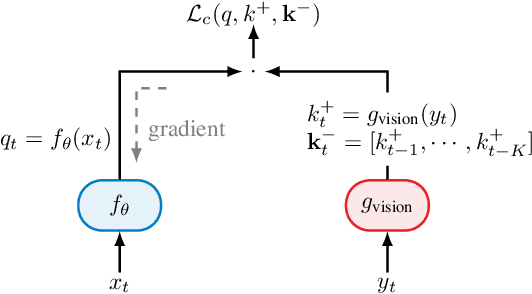
Next generation cellular networks will implement radio sensing functions alongside customary communications, thereby enabling unprecedented worldwide sensing coverage outdoors. Deep learning has revolutionised computer vision but has had limited application to radio perception tasks, in part due to lack of systematic datasets and benchmarks dedicated to the study of the performance and promise of radio sensing. To address this gap, we present MaxRay: a synthetic radio-visual dataset and benchmark that facilitate precise target localisation in radio. We further propose to learn to localise targets in radio without supervision by extracting self-coordinates from radio-visual correspondence. We use such self-supervised coordinates to train a radio localiser network. We characterise our performance against a number of state-of-the-art baselines. Our results indicate that accurate radio target localisation can be automatically learned from paired radio-visual data without labels, which is highly relevant to empirical data. This opens the door for vast data scalability and may prove key to realising the promise of robust radio sensing atop a unified perception-communication cellular infrastructure. Dataset will be hosted on IEEE DataPort.
Self-Supervised Radio-Visual Representation Learning for 6G Sensing
Nov 01, 2021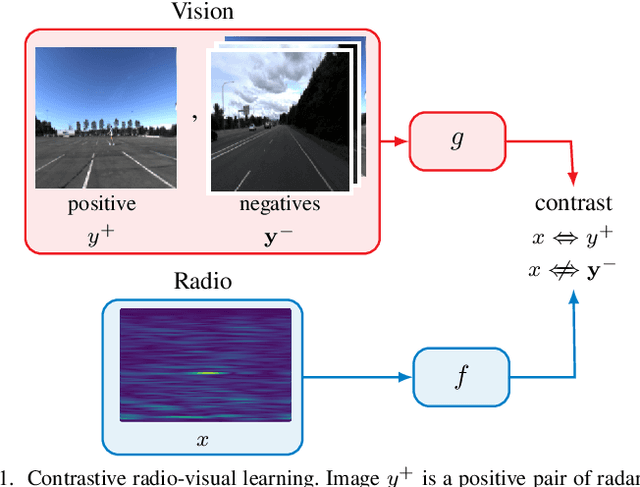
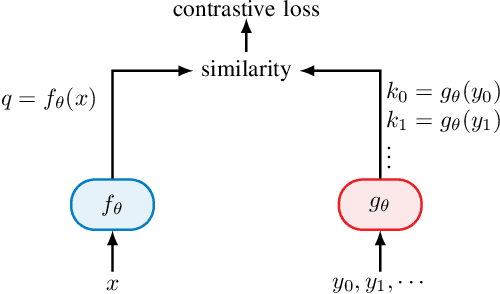
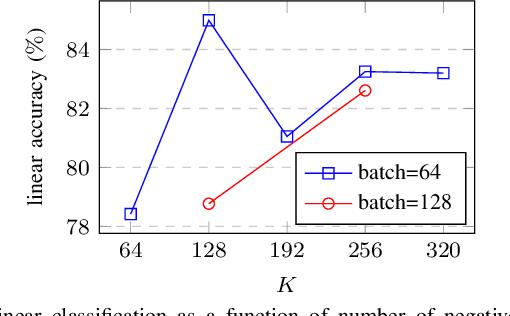
In future 6G cellular networks, a joint communication and sensing protocol will allow the network to perceive the environment, opening the door for many new applications atop a unified communication-perception infrastructure. However, interpreting the sparse radio representation of sensing scenes is challenging, which hinders the potential of these emergent systems. We propose to combine radio and vision to automatically learn a radio-only sensing model with minimal human intervention. We want to build a radio sensing model that can feed on millions of uncurated data points. To this end, we leverage recent advances in self-supervised learning and formulate a new label-free radio-visual co-learning scheme, whereby vision trains radio via cross-modal mutual information. We implement and evaluate our scheme according to the common linear classification benchmark, and report qualitative and quantitative performance metrics. In our evaluation, the representation learnt by radio-visual self-supervision works well for a downstream sensing demonstrator, and outperforms its fully-supervised counterpart when less labelled data is used. This indicates that self-supervised learning could be an important enabler for future scalable radio sensing systems.
Towards Generalisable Deep Inertial Tracking via Geometry-Aware Learning
Jun 29, 2021
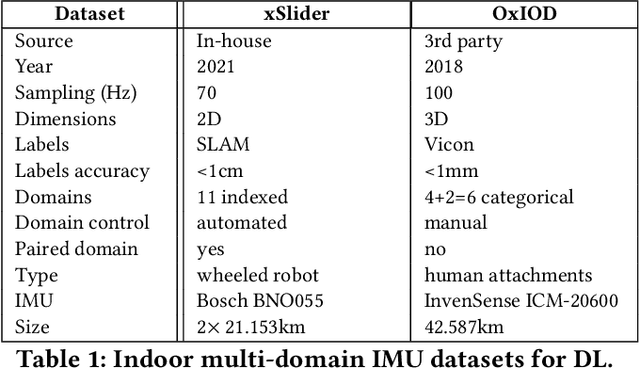
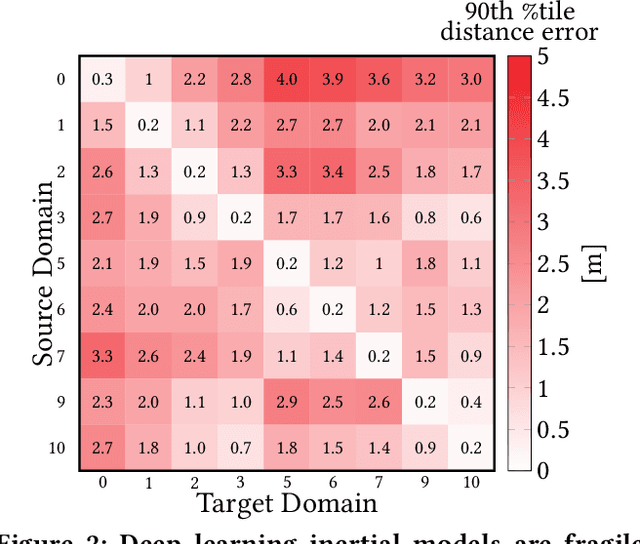
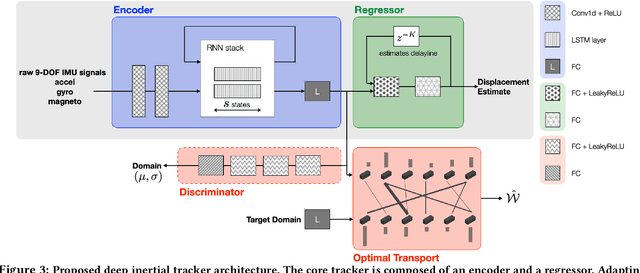
Autonomous navigation in uninstrumented and unprepared environments is a fundamental demand for next generation indoor and outdoor location-based services. To bring about such ambition, a suite of collaborative sensing modalities is required in order to sustain performance irrespective of challenging dynamic conditions. Of the many modalities on offer, inertial tracking plays a key role under momentary unfavourable operational conditions owing to its independence of the surrounding environment. However, inertial tracking has traditionally (i) suffered from excessive error growth and (ii) required extensive and cumbersome tuning. Both of these issues have limited the appeal and utility of inertial tracking. In this paper, we present DIT: a novel Deep learning Inertial Tracking system that overcomes prior limitations; namely, by (i) significantly reducing tracking drift and (ii) seamlessly constructing robust and generalisable learned models. DIT describes two core contributions: (i) DIT employs a robotic platform augmented with a mechanical slider subsystem that automatically samples inertial signal variabilities arising from different sensor mounting geometries. We use the platform to curate in-house a 7.2 million sample dataset covering an aggregate distance of 21 kilometres split into 11 indexed sensor mounting geometries. (ii) DIT uses deep learning, optimal transport, and domain adaptation (DA) to create a model which is robust to variabilities in sensor mounting geometry. The overall system synthesises high-performance and generalisable inertial navigation models in an end-to-end, robotic-learning fashion. In our evaluation, DIT outperforms an industrial-grade sensor fusion baseline by 10x (90th percentile) and a state-of-the-art adversarial DA technique by > 2.5x in performance (90th percentile) and >10x in training time.