 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Existence and Behaviour of Secondary Attention Sinks
Dec 22, 2025Attention sinks are tokens, often the beginning-of-sequence (BOS) token, that receive disproportionately high attention despite limited semantic relevance. In this work, we identify a class of attention sinks, which we term secondary sinks, that differ fundamentally from the sinks studied in prior works, which we term primary sinks. While prior works have identified that tokens other than BOS can sometimes become sinks, they were found to exhibit properties analogous to the BOS token. Specifically, they emerge at the same layer, persist throughout the network and draw a large amount of attention mass. Whereas, we find the existence of secondary sinks that arise primarily in middle layers and can persist for a variable number of layers, and draw a smaller, but still significant, amount of attention mass. Through extensive experiments across 11 model families, we analyze where these secondary sinks appear, their properties, how they are formed, and their impact on the attention mechanism. Specifically, we show that: (1) these sinks are formed by specific middle-layer MLP modules; these MLPs map token representations to vectors that align with the direction of the primary sink of that layer. (2) The $\ell_2$-norm of these vectors determines the sink score of the secondary sink, and also the number of layers it lasts for, thereby leading to different impacts on the attention mechanisms accordingly. (3) The primary sink weakens in middle layers, coinciding with the emergence of secondary sinks. We observe that in larger-scale models, the location and lifetime of the sinks, together referred to as sink levels, appear in a more deterministic and frequent manner. Specifically, we identify three sink levels in QwQ-32B and six levels in Qwen3-14B.
FRuDA: Framework for Distributed Adversarial Domain Adaptation
Dec 26, 2021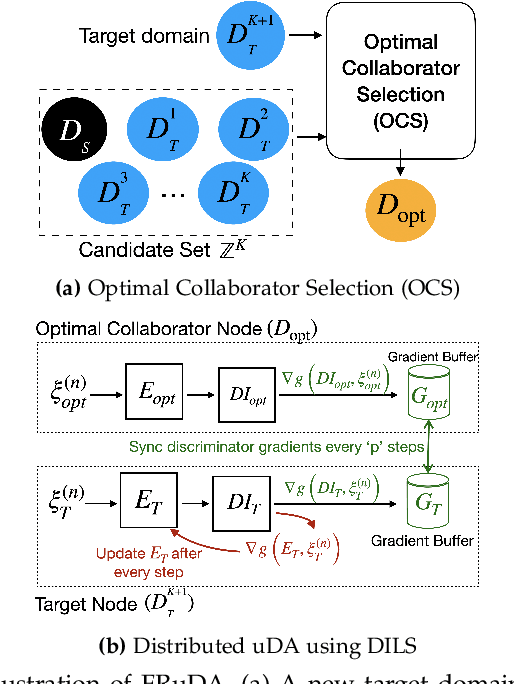
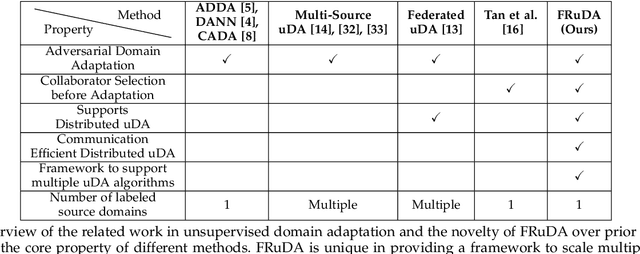
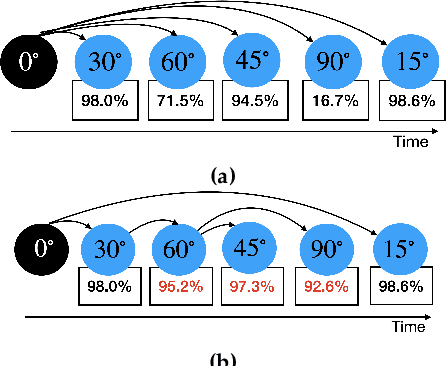

Breakthroughs in unsupervised domain adaptation (uDA) can help in adapting models from a label-rich source domain to unlabeled target domains. Despite these advancements, there is a lack of research on how uDA algorithms, particularly those based on adversarial learning, can work in distributed settings. In real-world applications, target domains are often distributed across thousands of devices, and existing adversarial uDA algorithms -- which are centralized in nature -- cannot be applied in these settings. To solve this important problem, we introduce FRuDA: an end-to-end framework for distributed adversarial uDA. Through a careful analysis of the uDA literature, we identify the design goals for a distributed uDA system and propose two novel algorithms to increase adaptation accuracy and training efficiency of adversarial uDA in distributed settings. Our evaluation of FRuDA with five image and speech datasets show that it can boost target domain accuracy by up to 50% and improve the training efficiency of adversarial uDA by at least 11 times.
Towards Generalisable Deep Inertial Tracking via Geometry-Aware Learning
Jun 29, 2021
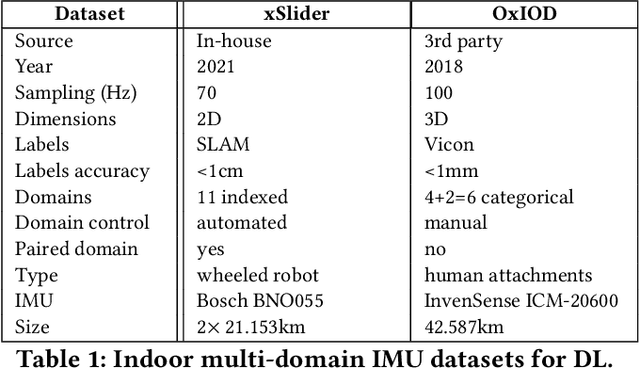
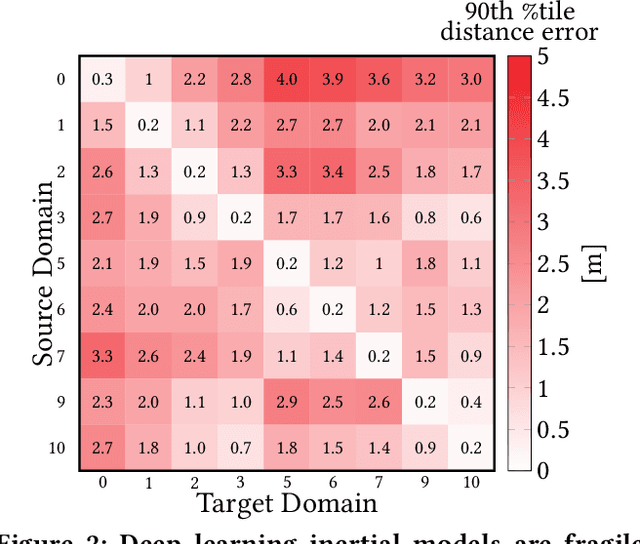
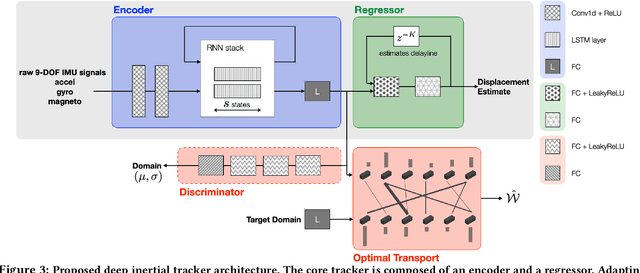
Autonomous navigation in uninstrumented and unprepared environments is a fundamental demand for next generation indoor and outdoor location-based services. To bring about such ambition, a suite of collaborative sensing modalities is required in order to sustain performance irrespective of challenging dynamic conditions. Of the many modalities on offer, inertial tracking plays a key role under momentary unfavourable operational conditions owing to its independence of the surrounding environment. However, inertial tracking has traditionally (i) suffered from excessive error growth and (ii) required extensive and cumbersome tuning. Both of these issues have limited the appeal and utility of inertial tracking. In this paper, we present DIT: a novel Deep learning Inertial Tracking system that overcomes prior limitations; namely, by (i) significantly reducing tracking drift and (ii) seamlessly constructing robust and generalisable learned models. DIT describes two core contributions: (i) DIT employs a robotic platform augmented with a mechanical slider subsystem that automatically samples inertial signal variabilities arising from different sensor mounting geometries. We use the platform to curate in-house a 7.2 million sample dataset covering an aggregate distance of 21 kilometres split into 11 indexed sensor mounting geometries. (ii) DIT uses deep learning, optimal transport, and domain adaptation (DA) to create a model which is robust to variabilities in sensor mounting geometry. The overall system synthesises high-performance and generalisable inertial navigation models in an end-to-end, robotic-learning fashion. In our evaluation, DIT outperforms an industrial-grade sensor fusion baseline by 10x (90th percentile) and a state-of-the-art adversarial DA technique by > 2.5x in performance (90th percentile) and >10x in training time.
Mic2Mic: Using Cycle-Consistent Generative Adversarial Networks to Overcome Microphone Variability in Speech Systems
Mar 27, 2020
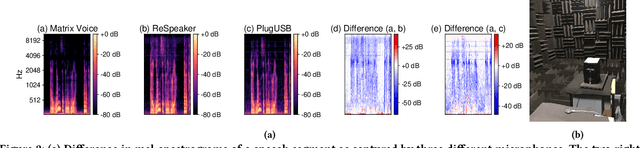
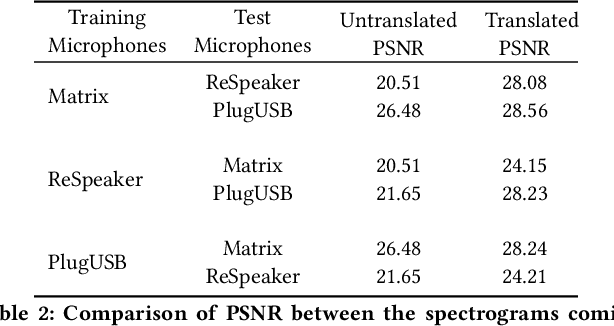
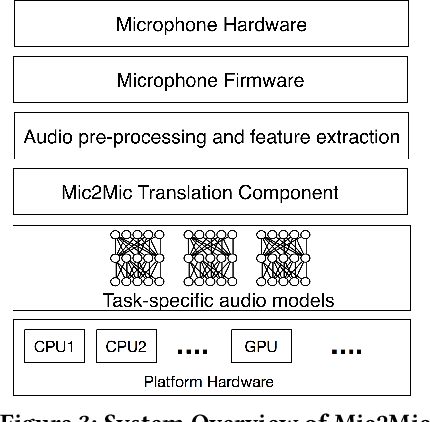
Mobile and embedded devices are increasingly using microphones and audio-based computational models to infer user context. A major challenge in building systems that combine audio models with commodity microphones is to guarantee their accuracy and robustness in the real-world. Besides many environmental dynamics, a primary factor that impacts the robustness of audio models is microphone variability. In this work, we propose Mic2Mic -- a machine-learned system component -- which resides in the inference pipeline of audio models and at real-time reduces the variability in audio data caused by microphone-specific factors. Two key considerations for the design of Mic2Mic were: a) to decouple the problem of microphone variability from the audio task, and b) put a minimal burden on end-users to provide training data. With these in mind, we apply the principles of cycle-consistent generative adversarial networks (CycleGANs) to learn Mic2Mic using unlabeled and unpaired data collected from different microphones. Our experiments show that Mic2Mic can recover between 66% to 89% of the accuracy lost due to microphone variability for two common audio tasks.