 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of States: Routing Token-Level Dynamics for Multimodal Generation
Nov 15, 2025We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.
Causal Head Gating: A Framework for Interpreting Roles of Attention Heads in Transformers
May 19, 2025We present causal head gating (CHG), a scalable method for interpreting the functional roles of attention heads in transformer models. CHG learns soft gates over heads and assigns them a causal taxonomy - facilitating, interfering, or irrelevant - based on their impact on task performance. Unlike prior approaches in mechanistic interpretability, which are hypothesis-driven and require prompt templates or target labels, CHG applies directly to any dataset using standard next-token prediction. We evaluate CHG across multiple large language models (LLMs) in the Llama 3 model family and diverse tasks, including syntax, commonsense, and mathematical reasoning, and show that CHG scores yield causal - not merely correlational - insight, validated via ablation and causal mediation analyses. We also introduce contrastive CHG, a variant that isolates sub-circuits for specific task components. Our findings reveal that LLMs contain multiple sparse, sufficient sub-circuits, that individual head roles depend on interactions with others (low modularity), and that instruction following and in-context learning rely on separable mechanisms.
Emergent Symbolic Mechanisms Support Abstract Reasoning in Large Language Models
Feb 27, 2025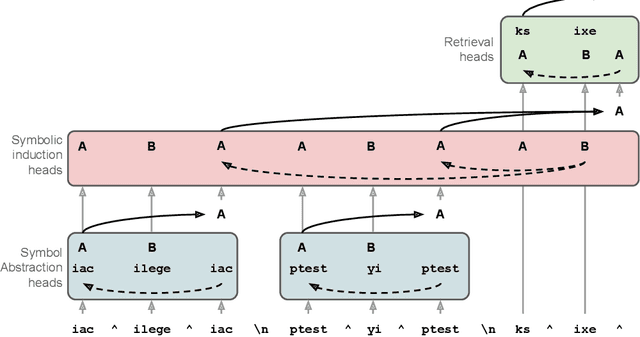
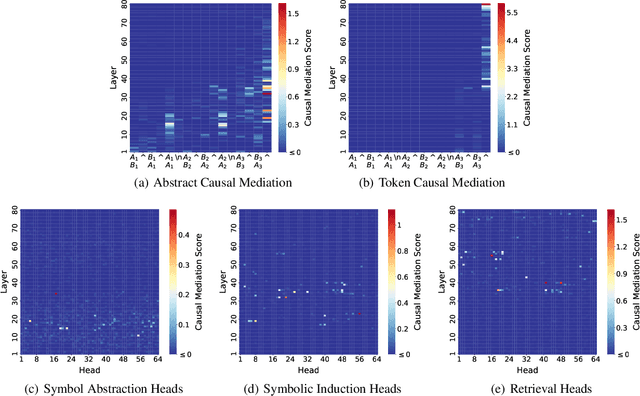
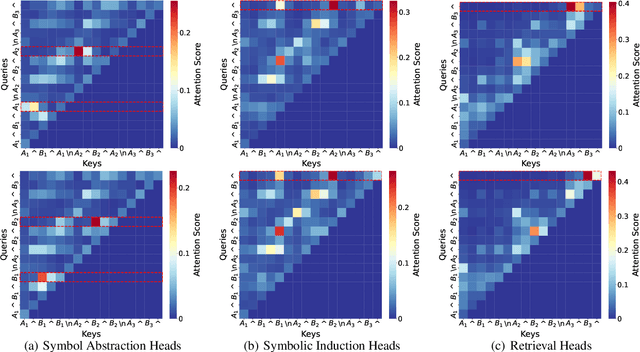
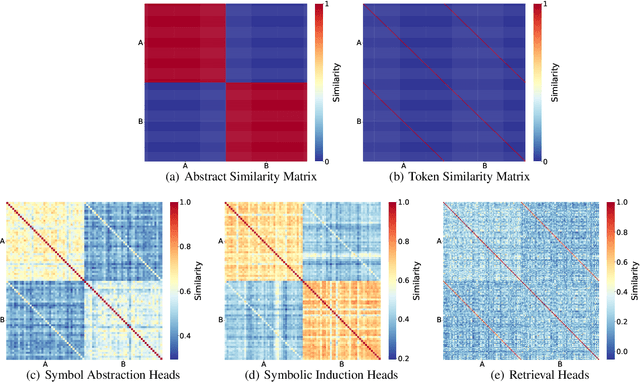
Many recent studies have found evidence for emergent reasoning capabilities in large language models, but debate persists concerning the robustness of these capabilities, and the extent to which they depend on structured reasoning mechanisms. To shed light on these issues, we perform a comprehensive study of the internal mechanisms that support abstract rule induction in an open-source language model (Llama3-70B). We identify an emergent symbolic architecture that implements abstract reasoning via a series of three computations. In early layers, symbol abstraction heads convert input tokens to abstract variables based on the relations between those tokens. In intermediate layers, symbolic induction heads perform sequence induction over these abstract variables. Finally, in later layers, retrieval heads predict the next token by retrieving the value associated with the predicted abstract variable. These results point toward a resolution of the longstanding debate between symbolic and neural network approaches, suggesting that emergent reasoning in neural networks depends on the emergence of symbolic mechanisms.
Training-Free Guidance Beyond Differentiability: Scalable Path Steering with Tree Search in Diffusion and Flow Models
Feb 17, 2025Training-free guidance enables controlled generation in diffusion and flow models, but most existing methods assume differentiable objectives and rely on gradients. This work focuses on training-free guidance addressing challenges from non-differentiable objectives and discrete data distributions. We propose an algorithmic framework TreeG: Tree Search-Based Path Steering Guidance, applicable to both continuous and discrete settings in diffusion and flow models. TreeG offers a unified perspective on training-free guidance: proposing candidates for the next step, evaluating candidates, and selecting the best to move forward, enhanced by a tree search mechanism over active paths or parallelizing exploration. We comprehensively investigate the design space of TreeG over the candidate proposal module and the evaluation function, instantiating TreeG into three novel algorithms. Our experiments show that TreeG consistently outperforms the top guidance baselines in symbolic music generation, small molecule generation, and enhancer DNA design, all of which involve non-differentiable challenges. Additionally, we identify an inference-time scaling law showing TreeG's scalability in inference-time computation.
Latent Diffusion Models for Controllable RNA Sequence Generation
Sep 15, 2024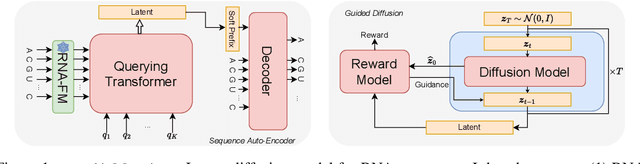
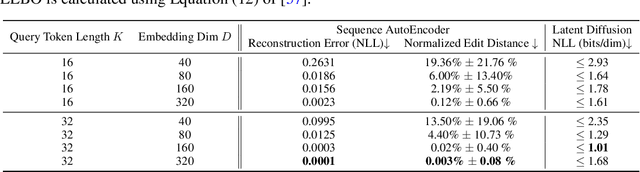

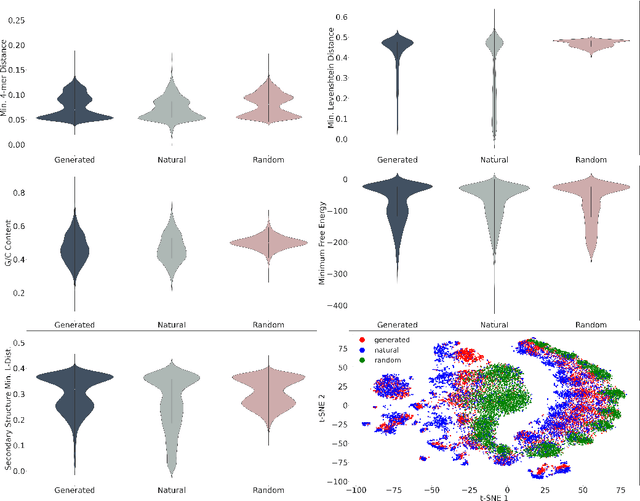
This paper presents RNAdiffusion, a latent diffusion model for generating and optimizing discrete RNA sequences. RNA is a particularly dynamic and versatile molecule in biological processes. RNA sequences exhibit high variability and diversity, characterized by their variable lengths, flexible three-dimensional structures, and diverse functions. We utilize pretrained BERT-type models to encode raw RNAs into token-level biologically meaningful representations. A Q-Former is employed to compress these representations into a fixed-length set of latent vectors, with an autoregressive decoder trained to reconstruct RNA sequences from these latent variables. We then develop a continuous diffusion model within this latent space. To enable optimization, we train reward networks to estimate functional properties of RNA from the latent variables. We employ gradient-based guidance during the backward diffusion process, aiming to generate RNA sequences that are optimized for higher rewards. Empirical experiments confirm that RNAdiffusion generates non-coding RNAs that align with natural distributions across various biological indicators. We fine-tuned the diffusion model on untranslated regions (UTRs) of mRNA and optimize sample sequences for protein translation efficiencies. Our guided diffusion model effectively generates diverse UTR sequences with high Mean Ribosome Loading (MRL) and Translation Efficiency (TE), surpassing baselines. These results hold promise for studies on RNA sequence-function relationships, protein synthesis, and enhancing therapeutic RNA design.
Gradient Guidance for Diffusion Models: An Optimization Perspective
Apr 23, 2024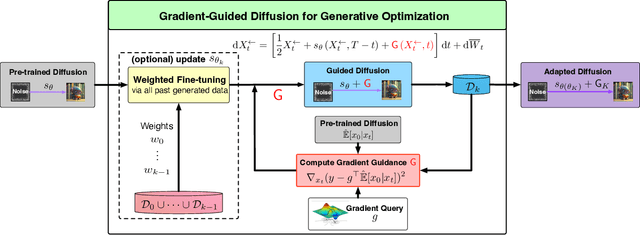
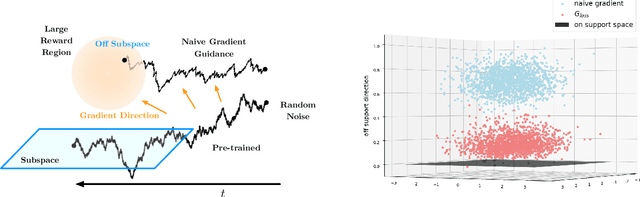
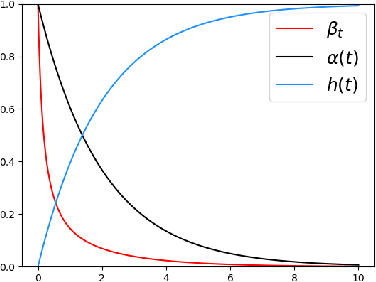
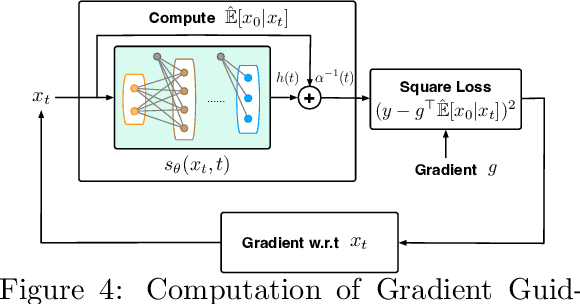
Diffusion models have demonstrated empirical successes in various applications and can be adapted to task-specific needs via guidance. This paper introduces a form of gradient guidance for adapting or fine-tuning diffusion models towards user-specified optimization objectives. We study the theoretic aspects of a guided score-based sampling process, linking the gradient-guided diffusion model to first-order optimization. We show that adding gradient guidance to the sampling process of a pre-trained diffusion model is essentially equivalent to solving a regularized optimization problem, where the regularization term acts as a prior determined by the pre-training data. Diffusion models are able to learn data's latent subspace, however, explicitly adding the gradient of an external objective function to the sample process would jeopardize the structure in generated samples. To remedy this issue, we consider a modified form of gradient guidance based on a forward prediction loss, which leverages the pre-trained score function to preserve the latent structure in generated samples. We further consider an iteratively fine-tuned version of gradient-guided diffusion where one can query gradients at newly generated data points and update the score network using new samples. This process mimics a first-order optimization iteration in expectation, for which we proved O(1/K) convergence rate to the global optimum when the objective function is concave.
Rank-DETR for High Quality Object Detection
Oct 19, 2023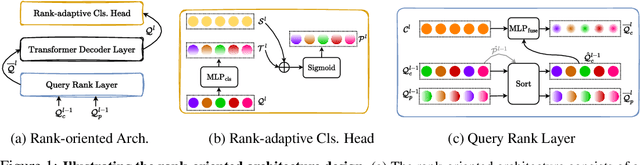


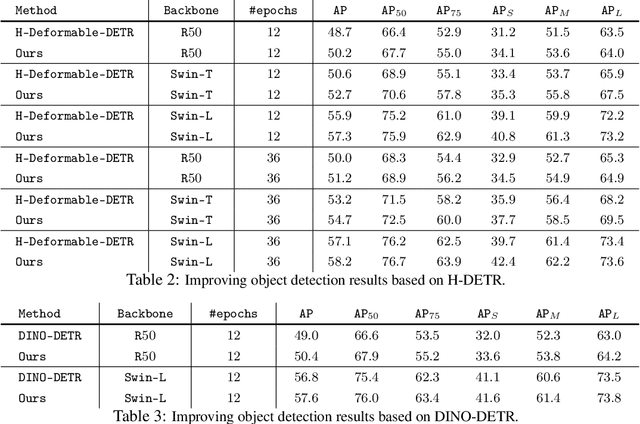
Modern detection transformers (DETRs) use a set of object queries to predict a list of bounding boxes, sort them by their classification confidence scores, and select the top-ranked predictions as the final detection results for the given input image. A highly performant object detector requires accurate ranking for the bounding box predictions. For DETR-based detectors, the top-ranked bounding boxes suffer from less accurate localization quality due to the misalignment between classification scores and localization accuracy, thus impeding the construction of high-quality detectors. In this work, we introduce a simple and highly performant DETR-based object detector by proposing a series of rank-oriented designs, combinedly called Rank-DETR. Our key contributions include: (i) a rank-oriented architecture design that can prompt positive predictions and suppress the negative ones to ensure lower false positive rates, as well as (ii) a rank-oriented loss function and matching cost design that prioritizes predictions of more accurate localization accuracy during ranking to boost the AP under high IoU thresholds. We apply our method to improve the recent SOTA methods (e.g., H-DETR and DINO-DETR) and report strong COCO object detection results when using different backbones such as ResNet-$50$, Swin-T, and Swin-L, demonstrating the effectiveness of our approach. Code is available at \url{https://github.com/LeapLabTHU/Rank-DETR}.
GlyphControl: Glyph Conditional Control for Visual Text Generation
May 29, 2023



Recently, there has been a growing interest in developing diffusion-based text-to-image generative models capable of generating coherent and well-formed visual text. In this paper, we propose a novel and efficient approach called GlyphControl to address this task. Unlike existing methods that rely on character-aware text encoders like ByT5 and require retraining of text-to-image models, our approach leverages additional glyph conditional information to enhance the performance of the off-the-shelf Stable-Diffusion model in generating accurate visual text. By incorporating glyph instructions, users can customize the content, location, and size of the generated text according to their specific requirements. To facilitate further research in visual text generation, we construct a training benchmark dataset called LAION-Glyph. We evaluate the effectiveness of our approach by measuring OCR-based metrics and CLIP scores of the generated visual text. Our empirical evaluations demonstrate that GlyphControl outperforms the recent DeepFloyd IF approach in terms of OCR accuracy and CLIP scores, highlighting the efficacy of our method.