 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Structure Reshapes the Representational Geometry of Language Models
Jan 29, 2026Large Language Models (LLMs) have been shown to organize the representations of input sequences into straighter neural trajectories in their deep layers, which has been hypothesized to facilitate next-token prediction via linear extrapolation. Language models can also adapt to diverse tasks and learn new structure in context, and recent work has shown that this in-context learning (ICL) can be reflected in representational changes. Here we bring these two lines of research together to explore whether representation straightening occurs \emph{within} a context during ICL. We measure representational straightening in Gemma 2 models across a diverse set of in-context tasks, and uncover a dichotomy in how LLMs' representations change in context. In continual prediction settings (e.g., natural language, grid world traversal tasks) we observe that increasing context increases the straightness of neural sequence trajectories, which is correlated with improvement in model prediction. Conversely, in structured prediction settings (e.g., few-shot tasks), straightening is inconsistent -- it is only present in phases of the task with explicit structure (e.g., repeating a template), but vanishes elsewhere. These results suggest that ICL is not a monolithic process. Instead, we propose that LLMs function like a Swiss Army knife: depending on task structure, the LLM dynamically selects between strategies, only some of which yield representational straightening.
Understanding Task Representations in Neural Networks via Bayesian Ablation
May 19, 2025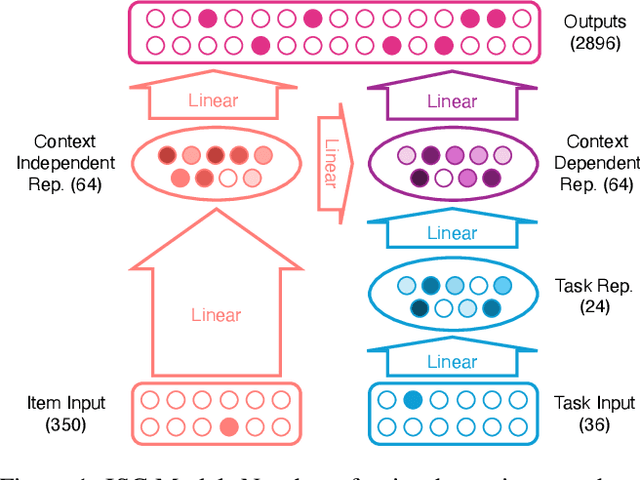
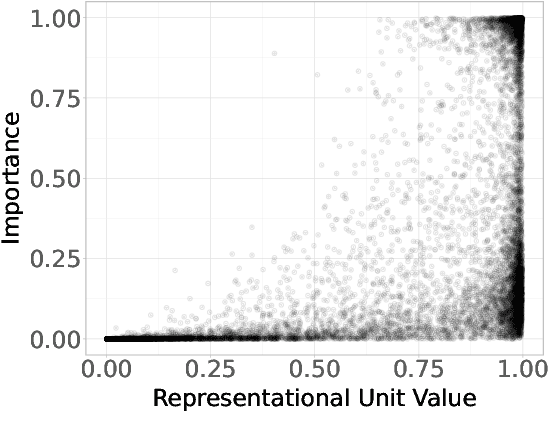
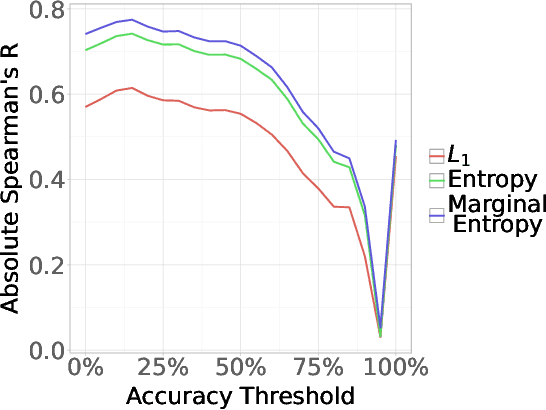
Neural networks are powerful tools for cognitive modeling due to their flexibility and emergent properties. However, interpreting their learned representations remains challenging due to their sub-symbolic semantics. In this work, we introduce a novel probabilistic framework for interpreting latent task representations in neural networks. Inspired by Bayesian inference, our approach defines a distribution over representational units to infer their causal contributions to task performance. Using ideas from information theory, we propose a suite of tools and metrics to illuminate key model properties, including representational distributedness, manifold complexity, and polysemanticity.
Using the Tools of Cognitive Science to Understand Large Language Models at Different Levels of Analysis
Mar 17, 2025Modern artificial intelligence systems, such as large language models, are increasingly powerful but also increasingly hard to understand. Recognizing this problem as analogous to the historical difficulties in understanding the human mind, we argue that methods developed in cognitive science can be useful for understanding large language models. We propose a framework for applying these methods based on Marr's three levels of analysis. By revisiting established cognitive science techniques relevant to each level and illustrating their potential to yield insights into the behavior and internal organization of large language models, we aim to provide a toolkit for making sense of these new kinds of minds.
Emergent Symbolic Mechanisms Support Abstract Reasoning in Large Language Models
Feb 27, 2025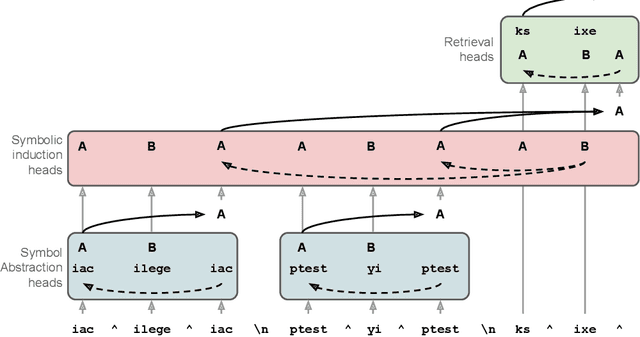
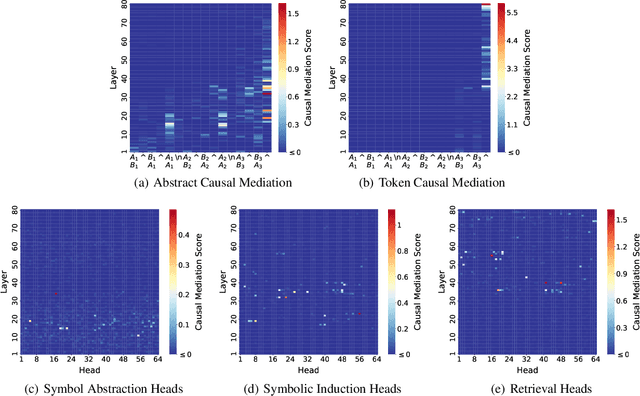
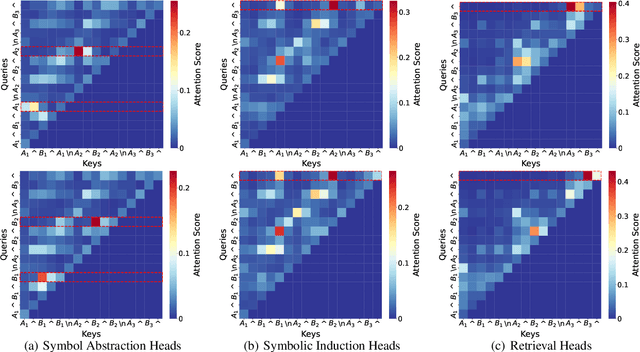
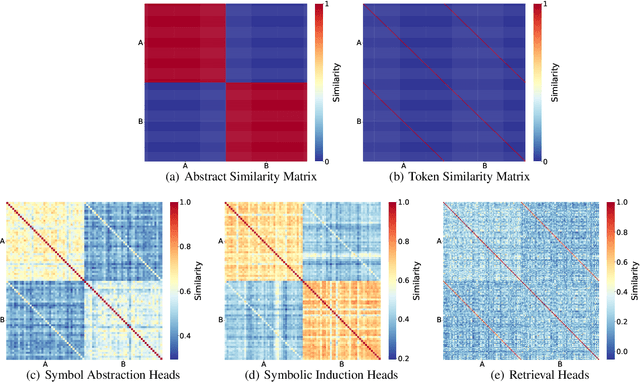
Many recent studies have found evidence for emergent reasoning capabilities in large language models, but debate persists concerning the robustness of these capabilities, and the extent to which they depend on structured reasoning mechanisms. To shed light on these issues, we perform a comprehensive study of the internal mechanisms that support abstract rule induction in an open-source language model (Llama3-70B). We identify an emergent symbolic architecture that implements abstract reasoning via a series of three computations. In early layers, symbol abstraction heads convert input tokens to abstract variables based on the relations between those tokens. In intermediate layers, symbolic induction heads perform sequence induction over these abstract variables. Finally, in later layers, retrieval heads predict the next token by retrieving the value associated with the predicted abstract variable. These results point toward a resolution of the longstanding debate between symbolic and neural network approaches, suggesting that emergent reasoning in neural networks depends on the emergence of symbolic mechanisms.
Understanding the Limits of Vision Language Models Through the Lens of the Binding Problem
Oct 31, 2024



Recent work has documented striking heterogeneity in the performance of state-of-the-art vision language models (VLMs), including both multimodal language models and text-to-image models. These models are able to describe and generate a diverse array of complex, naturalistic images, yet they exhibit surprising failures on basic multi-object reasoning tasks -- such as counting, localization, and simple forms of visual analogy -- that humans perform with near perfect accuracy. To better understand this puzzling pattern of successes and failures, we turn to theoretical accounts of the binding problem in cognitive science and neuroscience, a fundamental problem that arises when a shared set of representational resources must be used to represent distinct entities (e.g., to represent multiple objects in an image), necessitating the use of serial processing to avoid interference. We find that many of the puzzling failures of state-of-the-art VLMs can be explained as arising due to the binding problem, and that these failure modes are strikingly similar to the limitations exhibited by rapid, feedforward processing in the human brain.
Using Contrastive Learning with Generative Similarity to Learn Spaces that Capture Human Inductive Biases
May 29, 2024



Humans rely on strong inductive biases to learn from few examples and abstract useful information from sensory data. Instilling such biases in machine learning models has been shown to improve their performance on various benchmarks including few-shot learning, robustness, and alignment. However, finding effective training procedures to achieve that goal can be challenging as psychologically-rich training data such as human similarity judgments are expensive to scale, and Bayesian models of human inductive biases are often intractable for complex, realistic domains. Here, we address this challenge by introducing a Bayesian notion of generative similarity whereby two datapoints are considered similar if they are likely to have been sampled from the same distribution. This measure can be applied to complex generative processes, including probabilistic programs. We show that generative similarity can be used to define a contrastive learning objective even when its exact form is intractable, enabling learning of spatial embeddings that express specific inductive biases. We demonstrate the utility of our approach by showing how it can be used to capture human inductive biases for geometric shapes, and to better distinguish different abstract drawing styles that are parameterized by probabilistic programs.
A Relational Inductive Bias for Dimensional Abstraction in Neural Networks
Feb 28, 2024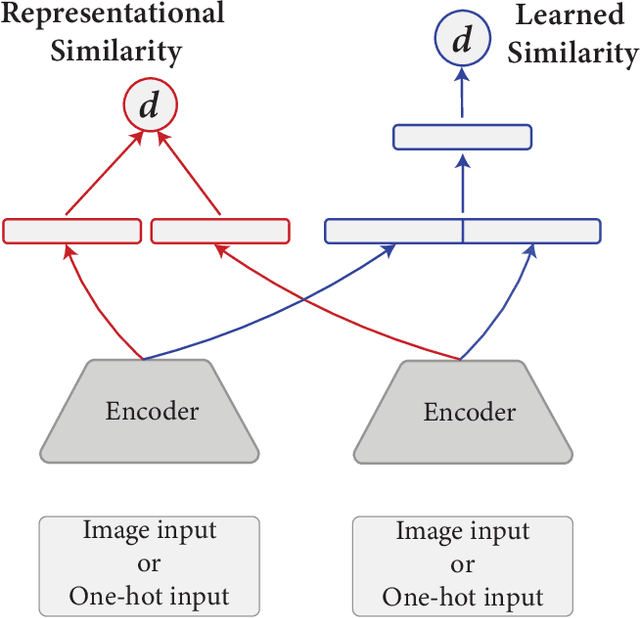
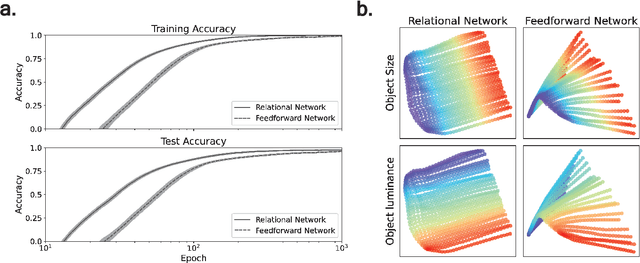
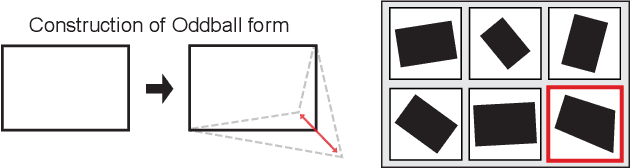
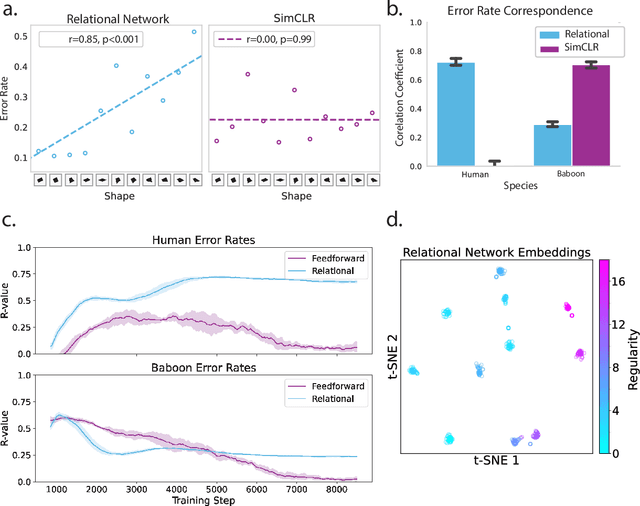
The human cognitive system exhibits remarkable flexibility and generalization capabilities, partly due to its ability to form low-dimensional, compositional representations of the environment. In contrast, standard neural network architectures often struggle with abstract reasoning tasks, overfitting, and requiring extensive data for training. This paper investigates the impact of the relational bottleneck -- a mechanism that focuses processing on relations among inputs -- on the learning of factorized representations conducive to compositional coding and the attendant flexibility of processing. We demonstrate that such a bottleneck not only improves generalization and learning efficiency, but also aligns network performance with human-like behavioral biases. Networks trained with the relational bottleneck developed orthogonal representations of feature dimensions latent in the dataset, reflecting the factorized structure thought to underlie human cognitive flexibility. Moreover, the relational network mimics human biases towards regularity without pre-specified symbolic primitives, suggesting that the bottleneck fosters the emergence of abstract representations that confer flexibility akin to symbols.
Comparing Abstraction in Humans and Large Language Models Using Multimodal Serial Reproduction
Feb 06, 2024



Humans extract useful abstractions of the world from noisy sensory data. Serial reproduction allows us to study how people construe the world through a paradigm similar to the game of telephone, where one person observes a stimulus and reproduces it for the next to form a chain of reproductions. Past serial reproduction experiments typically employ a single sensory modality, but humans often communicate abstractions of the world to each other through language. To investigate the effect language on the formation of abstractions, we implement a novel multimodal serial reproduction framework by asking people who receive a visual stimulus to reproduce it in a linguistic format, and vice versa. We ran unimodal and multimodal chains with both humans and GPT-4 and find that adding language as a modality has a larger effect on human reproductions than GPT-4's. This suggests human visual and linguistic representations are more dissociable than those of GPT-4.
Human-Like Geometric Abstraction in Large Pre-trained Neural Networks
Feb 06, 2024Humans possess a remarkable capacity to recognize and manipulate abstract structure, which is especially apparent in the domain of geometry. Recent research in cognitive science suggests neural networks do not share this capacity, concluding that human geometric abilities come from discrete symbolic structure in human mental representations. However, progress in artificial intelligence (AI) suggests that neural networks begin to demonstrate more human-like reasoning after scaling up standard architectures in both model size and amount of training data. In this study, we revisit empirical results in cognitive science on geometric visual processing and identify three key biases in geometric visual processing: a sensitivity towards complexity, regularity, and the perception of parts and relations. We test tasks from the literature that probe these biases in humans and find that large pre-trained neural network models used in AI demonstrate more human-like abstract geometric processing.
The Relational Bottleneck as an Inductive Bias for Efficient Abstraction
Sep 12, 2023

A central challenge for cognitive science is to explain how abstract concepts are acquired from limited experience. This effort has often been framed in terms of a dichotomy between empiricist and nativist approaches, most recently embodied by debates concerning deep neural networks and symbolic cognitive models. Here, we highlight a recently emerging line of work that suggests a novel reconciliation of these approaches, by exploiting an inductive bias that we term the relational bottleneck. We review a family of models that employ this approach to induce abstractions in a data-efficient manner, emphasizing their potential as candidate models for the acquisition of abstract concepts in the human mind and brain.