 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Mitigating the Influence of the Prior Distribution in Large Language Models
Apr 17, 2025Large language models (LLMs) sometimes fail to respond appropriately to deterministic tasks -- such as counting or forming acronyms -- because the implicit prior distribution they have learned over sequences of tokens influences their responses. In this work, we show that, in at least some cases, LLMs actually compute the information needed to perform these tasks correctly, and we identify some interventions that can allow them to access this information to improve their performance. First, we show that simply prompting the language model to not rely on its prior knowledge leads to dramatic improvements in prior-dominated tasks. We then use mechanistic interpretability techniques to localize the prior within the LLM and manipulate the extent to which that prior influences its responses. Specifically, we show that it is possible to identify layers of the underlying neural network that correlate with the prior probability of a response and that lightweight finetuning of these layers with basic prompts on prior-dominated tasks achieves high performance on held-out answers. These results suggest that the information required to produce a correct response is contained within the representations of the problems formed by the models. Furthermore, we show that this finetuning is significantly more effective for prior-dominated tasks, and that the error after finetuning is no longer correlated with the prior. Our results suggest that it may be possible to define effective methods for manipulating the extent to which LLMs rely upon their priors in solving problems, potentially increasing their performance in settings where LLMs hallucinate for reasons related to the prior probability of token sequences.
Localized Cultural Knowledge is Conserved and Controllable in Large Language Models
Apr 14, 2025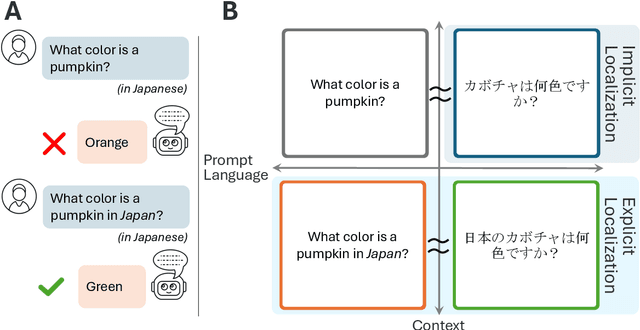

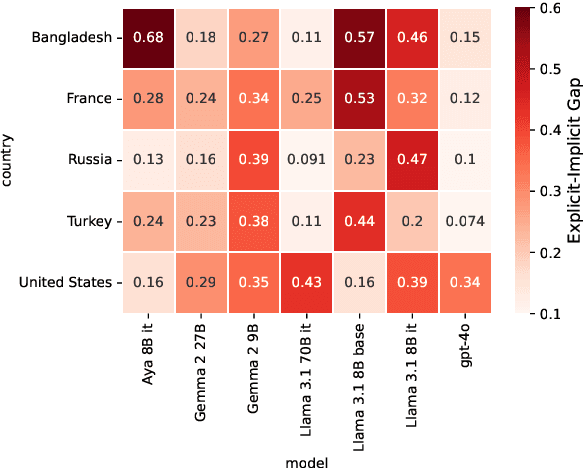
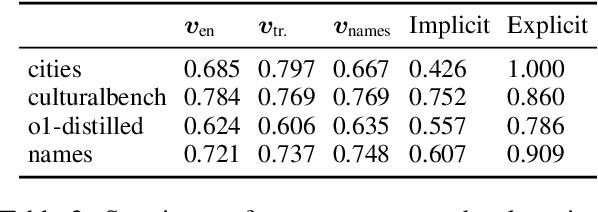
Just as humans display language patterns influenced by their native tongue when speaking new languages, LLMs often default to English-centric responses even when generating in other languages. Nevertheless, we observe that local cultural information persists within the models and can be readily activated for cultural customization. We first demonstrate that explicitly providing cultural context in prompts significantly improves the models' ability to generate culturally localized responses. We term the disparity in model performance with versus without explicit cultural context the explicit-implicit localization gap, indicating that while cultural knowledge exists within LLMs, it may not naturally surface in multilingual interactions if cultural context is not explicitly provided. Despite the explicit prompting benefit, however, the answers reduce in diversity and tend toward stereotypes. Second, we identify an explicit cultural customization vector, conserved across all non-English languages we explore, which enables LLMs to be steered from the synthetic English cultural world-model toward each non-English cultural world. Steered responses retain the diversity of implicit prompting and reduce stereotypes to dramatically improve the potential for customization. We discuss the implications of explicit cultural customization for understanding the conservation of alternative cultural world models within LLMs, and their controllable utility for translation, cultural customization, and the possibility of making the explicit implicit through soft control for expanded LLM function and appeal.
Using the Tools of Cognitive Science to Understand Large Language Models at Different Levels of Analysis
Mar 17, 2025Modern artificial intelligence systems, such as large language models, are increasingly powerful but also increasingly hard to understand. Recognizing this problem as analogous to the historical difficulties in understanding the human mind, we argue that methods developed in cognitive science can be useful for understanding large language models. We propose a framework for applying these methods based on Marr's three levels of analysis. By revisiting established cognitive science techniques relevant to each level and illustrating their potential to yield insights into the behavior and internal organization of large language models, we aim to provide a toolkit for making sense of these new kinds of minds.
What is a Number, That a Large Language Model May Know It?
Feb 03, 2025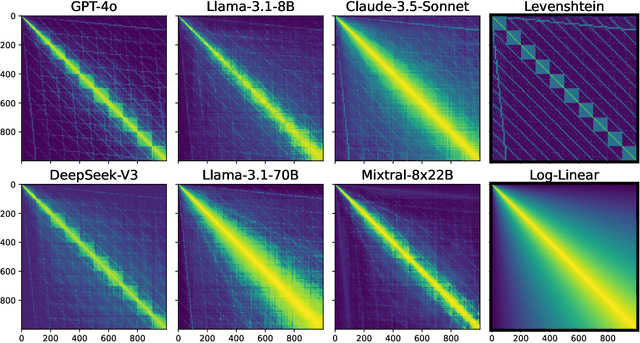

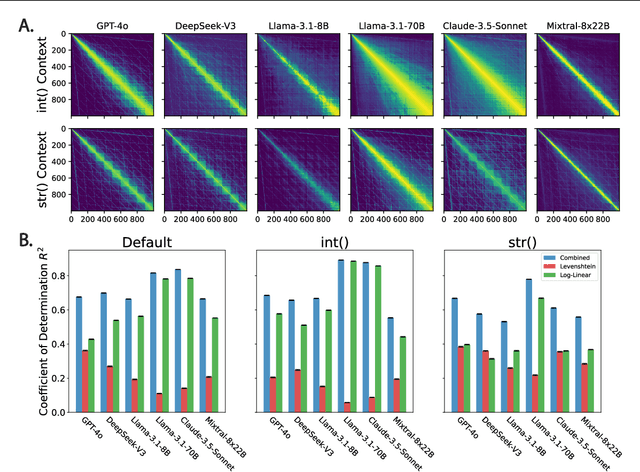

Numbers are a basic part of how humans represent and describe the world around them. As a consequence, learning effective representations of numbers is critical for the success of large language models as they become more integrated into everyday decisions. However, these models face a challenge: depending on context, the same sequence of digit tokens, e.g., 911, can be treated as a number or as a string. What kind of representations arise from this duality, and what are its downstream implications? Using a similarity-based prompting technique from cognitive science, we show that LLMs learn representational spaces that blend string-like and numerical representations. In particular, we show that elicited similarity judgments from these models over integer pairs can be captured by a combination of Levenshtein edit distance and numerical Log-Linear distance, suggesting an entangled representation. In a series of experiments we show how this entanglement is reflected in the latent embeddings, how it can be reduced but not entirely eliminated by context, and how it can propagate into a realistic decision scenario. These results shed light on a representational tension in transformer models that must learn what a number is from text input.
Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers
Nov 13, 2024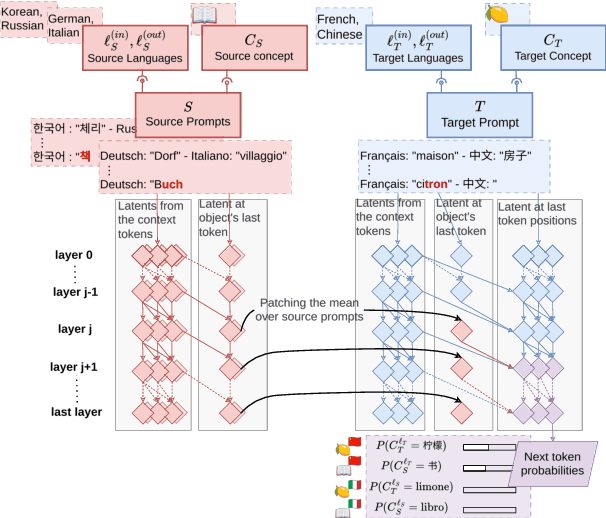
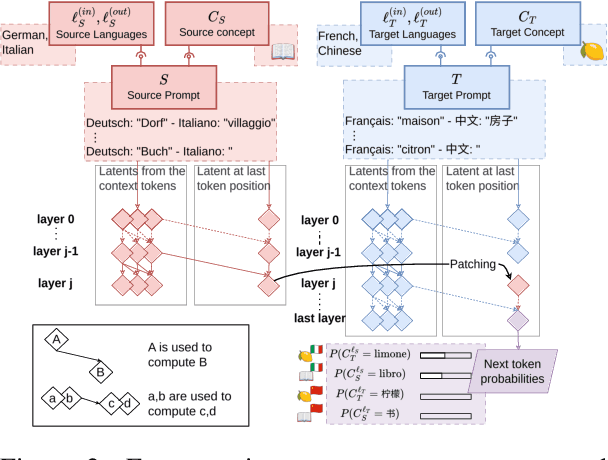
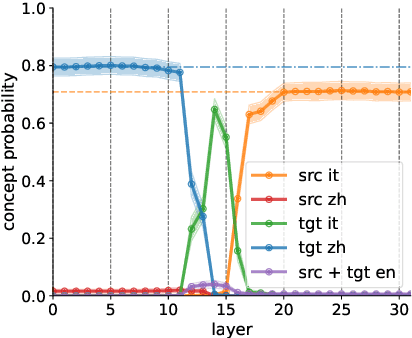
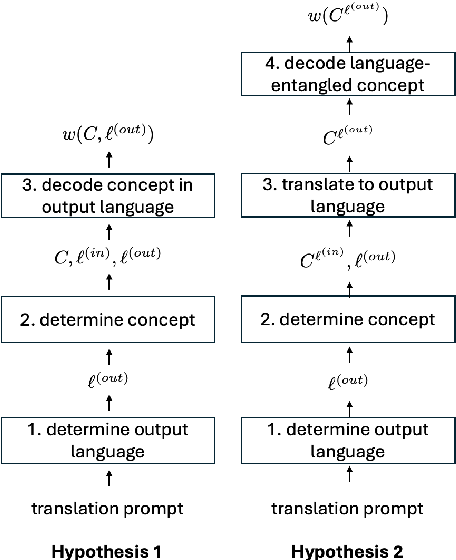
A central question in multilingual language modeling is whether large language models (LLMs) develop a universal concept representation, disentangled from specific languages. In this paper, we address this question by analyzing latent representations (latents) during a word translation task in transformer-based LLMs. We strategically extract latents from a source translation prompt and insert them into the forward pass on a target translation prompt. By doing so, we find that the output language is encoded in the latent at an earlier layer than the concept to be translated. Building on this insight, we conduct two key experiments. First, we demonstrate that we can change the concept without changing the language and vice versa through activation patching alone. Second, we show that patching with the mean over latents across different languages does not impair and instead improves the models' performance in translating the concept. Our results provide evidence for the existence of language-agnostic concept representations within the investigated models.
Self-Recognition in Language Models
Jul 09, 2024



A rapidly growing number of applications rely on a small set of closed-source language models (LMs). This dependency might introduce novel security risks if LMs develop self-recognition capabilities. Inspired by human identity verification methods, we propose a novel approach for assessing self-recognition in LMs using model-generated "security questions". Our test can be externally administered to keep track of frontier models as it does not require access to internal model parameters or output probabilities. We use our test to examine self-recognition in ten of the most capable open- and closed-source LMs currently publicly available. Our extensive experiments found no empirical evidence of general or consistent self-recognition in any examined LM. Instead, our results suggest that given a set of alternatives, LMs seek to pick the "best" answer, regardless of its origin. Moreover, we find indications that preferences about which models produce the best answers are consistent across LMs. We additionally uncover novel insights on position bias considerations for LMs in multiple-choice settings.
Do Llamas Work in English? On the Latent Language of Multilingual Transformers
Feb 24, 2024We ask whether multilingual language models trained on unbalanced, English-dominated corpora use English as an internal pivot language -- a question of key importance for understanding how language models function and the origins of linguistic bias. Focusing on the Llama-2 family of transformer models, our study uses carefully constructed non-English prompts with a unique correct single-token continuation. From layer to layer, transformers gradually map an input embedding of the final prompt token to an output embedding from which next-token probabilities are computed. Tracking intermediate embeddings through their high-dimensional space reveals three distinct phases, whereby intermediate embeddings (1) start far away from output token embeddings; (2) already allow for decoding a semantically correct next token in the middle layers, but give higher probability to its version in English than in the input language; (3) finally move into an input-language-specific region of the embedding space. We cast these results into a conceptual model where the three phases operate in "input space", "concept space", and "output space", respectively. Crucially, our evidence suggests that the abstract "concept space" lies closer to English than to other languages, which may have important consequences regarding the biases held by multilingual language models.
Evaluating Language Model Agency through Negotiations
Jan 09, 2024


Companies, organizations, and governments increasingly exploit Language Models' (LM) remarkable capability to display agent-like behavior. As LMs are adopted to perform tasks with growing autonomy, there exists an urgent need for reliable and scalable evaluation benchmarks. Current, predominantly static LM benchmarks are ill-suited to evaluate such dynamic applications. Thus, we propose jointly evaluating LM performance and alignment through the lenses of negotiation games. We argue that this common task better reflects real-world deployment conditions while offering insights into LMs' decision-making processes. Crucially, negotiation games allow us to study multi-turn, and cross-model interactions, modulate complexity, and side-step accidental data leakage in evaluation. We report results for six publicly accessible LMs from several major providers on a variety of negotiation games, evaluating both self-play and cross-play performance. Noteworthy findings include: (i) open-source models are currently unable to complete these tasks; (ii) cooperative bargaining games prove challenging; and (iii) the most powerful models do not always "win".
Prevalence and prevention of large language model use in crowd work
Oct 24, 2023

We show that the use of large language models (LLMs) is prevalent among crowd workers, and that targeted mitigation strategies can significantly reduce, but not eliminate, LLM use. On a text summarization task where workers were not directed in any way regarding their LLM use, the estimated prevalence of LLM use was around 30%, but was reduced by about half by asking workers to not use LLMs and by raising the cost of using them, e.g., by disabling copy-pasting. Secondary analyses give further insight into LLM use and its prevention: LLM use yields high-quality but homogeneous responses, which may harm research concerned with human (rather than model) behavior and degrade future models trained with crowdsourced data. At the same time, preventing LLM use may be at odds with obtaining high-quality responses; e.g., when requesting workers not to use LLMs, summaries contained fewer keywords carrying essential information. Our estimates will likely change as LLMs increase in popularity or capabilities, and as norms around their usage change. Yet, understanding the co-evolution of LLM-based tools and users is key to maintaining the validity of research done using crowdsourcing, and we provide a critical baseline before widespread adoption ensues.
Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks
Jun 13, 2023



Large language models (LLMs) are remarkable data annotators. They can be used to generate high-fidelity supervised training data, as well as survey and experimental data. With the widespread adoption of LLMs, human gold--standard annotations are key to understanding the capabilities of LLMs and the validity of their results. However, crowdsourcing, an important, inexpensive way to obtain human annotations, may itself be impacted by LLMs, as crowd workers have financial incentives to use LLMs to increase their productivity and income. To investigate this concern, we conducted a case study on the prevalence of LLM usage by crowd workers. We reran an abstract summarization task from the literature on Amazon Mechanical Turk and, through a combination of keystroke detection and synthetic text classification, estimate that 33-46% of crowd workers used LLMs when completing the task. Although generalization to other, less LLM-friendly tasks is unclear, our results call for platforms, researchers, and crowd workers to find new ways to ensure that human data remain human, perhaps using the methodology proposed here as a stepping stone. Code/data: https://github.com/epfl-dlab/GPTurk