 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelograms Strike Back: LLMs Generate Better Analogies than People
Mar 19, 2026Four-term word analogies (A:B::C:D) are classically modeled geometrically as ''parallelograms,'' yet recent work suggests this model poorly captures how humans produce analogies, with simple local-similarity heuristics often providing a better account (Peterson et al., 2020). But does the parallelogram model fail because it is a bad model of analogical relations, or because people are not very good at generating relation-preserving analogies? We compared human and large language model (LLM) analogy completions on the same set of analogy problems from (Peterson et al., 2020). We find that LLM-generated analogies are reliably judged as better than human-generated ones, and are also more closely aligned with the parallelogram structure in a distributional embedding space (GloVe). Crucially, we show that the improvement over human analogies was driven by greater parallelogram alignment and reduced reliance on accessible words rather than enhanced sensitivity to local similarity. Moreover, the LLM advantage is driven not by uniformly superior responses by LLMs, but by humans producing a long tail of weak completions: when only modal (most frequent) responses by both systems are compared, the LLM advantage disappears. However, greater parallelogram alignment and lower word frequency continue to predict which LLM completions are rated higher than those of humans. Overall, these results suggest that the parallelogram model is not a poor account of word analogy. Rather, humans may often fail to produce completions that satisfy this relational constraint, whereas LLMs do so more consistently.
Why Human Guidance Matters in Collaborative Vibe Coding
Feb 11, 2026Writing code has been one of the most transformative ways for human societies to translate abstract ideas into tangible technologies. Modern AI is transforming this process by enabling experts and non-experts alike to generate code without actually writing code, but instead, through natural language instructions, or "vibe coding". While increasingly popular, the cumulative impact of vibe coding on productivity and collaboration, as well as the role of humans in this process, remains unclear. Here, we introduce a controlled experimental framework for studying collaborative vibe coding and use it to compare human-led, AI-led, and hybrid groups. Across 16 experiments involving 604 human participants, we show that people provide uniquely effective high-level instructions for vibe coding across iterations, whereas AI-provided instructions often result in performance collapse. We further demonstrate that hybrid systems perform best when humans retain directional control (providing the instructions), while evaluation is delegated to AI.
Using the Tools of Cognitive Science to Understand Large Language Models at Different Levels of Analysis
Mar 17, 2025Modern artificial intelligence systems, such as large language models, are increasingly powerful but also increasingly hard to understand. Recognizing this problem as analogous to the historical difficulties in understanding the human mind, we argue that methods developed in cognitive science can be useful for understanding large language models. We propose a framework for applying these methods based on Marr's three levels of analysis. By revisiting established cognitive science techniques relevant to each level and illustrating their potential to yield insights into the behavior and internal organization of large language models, we aim to provide a toolkit for making sense of these new kinds of minds.
What is a Number, That a Large Language Model May Know It?
Feb 03, 2025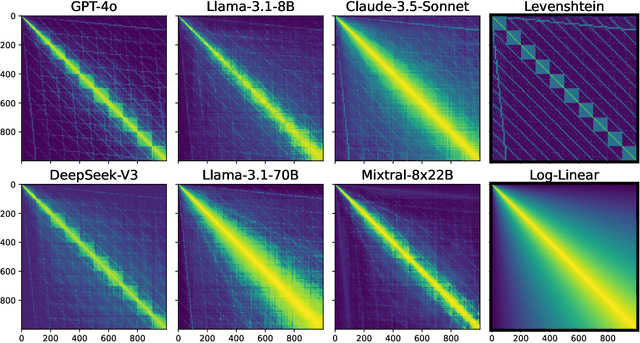

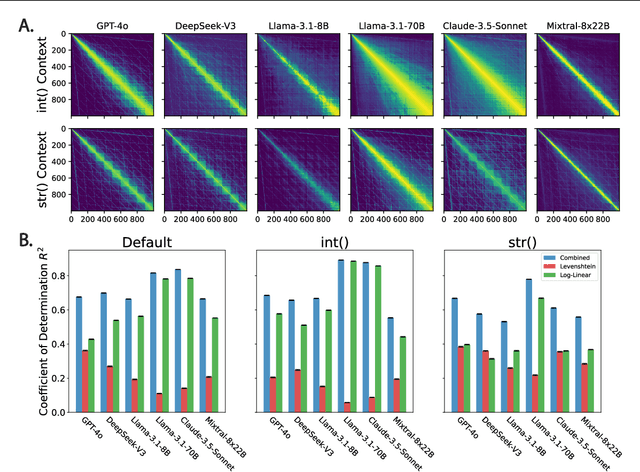

Numbers are a basic part of how humans represent and describe the world around them. As a consequence, learning effective representations of numbers is critical for the success of large language models as they become more integrated into everyday decisions. However, these models face a challenge: depending on context, the same sequence of digit tokens, e.g., 911, can be treated as a number or as a string. What kind of representations arise from this duality, and what are its downstream implications? Using a similarity-based prompting technique from cognitive science, we show that LLMs learn representational spaces that blend string-like and numerical representations. In particular, we show that elicited similarity judgments from these models over integer pairs can be captured by a combination of Levenshtein edit distance and numerical Log-Linear distance, suggesting an entangled representation. In a series of experiments we show how this entanglement is reflected in the latent embeddings, how it can be reduced but not entirely eliminated by context, and how it can propagate into a realistic decision scenario. These results shed light on a representational tension in transformer models that must learn what a number is from text input.
Characterizing Similarities and Divergences in Conversational Tones in Humans and LLMs by Sampling with People
Jun 06, 2024Conversational tones -- the manners and attitudes in which speakers communicate -- are essential to effective communication. Amidst the increasing popularization of Large Language Models (LLMs) over recent years, it becomes necessary to characterize the divergences in their conversational tones relative to humans. However, existing investigations of conversational modalities rely on pre-existing taxonomies or text corpora, which suffer from experimenter bias and may not be representative of real-world distributions for the studies' psycholinguistic domains. Inspired by methods from cognitive science, we propose an iterative method for simultaneously eliciting conversational tones and sentences, where participants alternate between two tasks: (1) one participant identifies the tone of a given sentence and (2) a different participant generates a sentence based on that tone. We run 100 iterations of this process with human participants and GPT-4, then obtain a dataset of sentences and frequent conversational tones. In an additional experiment, humans and GPT-4 annotated all sentences with all tones. With data from 1,339 human participants, 33,370 human judgments, and 29,900 GPT-4 queries, we show how our approach can be used to create an interpretable geometric representation of relations between conversational tones in humans and GPT-4. This work demonstrates how combining ideas from machine learning and cognitive science can address challenges in human-computer interactions.
Using Contrastive Learning with Generative Similarity to Learn Spaces that Capture Human Inductive Biases
May 29, 2024



Humans rely on strong inductive biases to learn from few examples and abstract useful information from sensory data. Instilling such biases in machine learning models has been shown to improve their performance on various benchmarks including few-shot learning, robustness, and alignment. However, finding effective training procedures to achieve that goal can be challenging as psychologically-rich training data such as human similarity judgments are expensive to scale, and Bayesian models of human inductive biases are often intractable for complex, realistic domains. Here, we address this challenge by introducing a Bayesian notion of generative similarity whereby two datapoints are considered similar if they are likely to have been sampled from the same distribution. This measure can be applied to complex generative processes, including probabilistic programs. We show that generative similarity can be used to define a contrastive learning objective even when its exact form is intractable, enabling learning of spatial embeddings that express specific inductive biases. We demonstrate the utility of our approach by showing how it can be used to capture human inductive biases for geometric shapes, and to better distinguish different abstract drawing styles that are parameterized by probabilistic programs.
A Rational Analysis of the Speech-to-Song Illusion
Feb 10, 2024


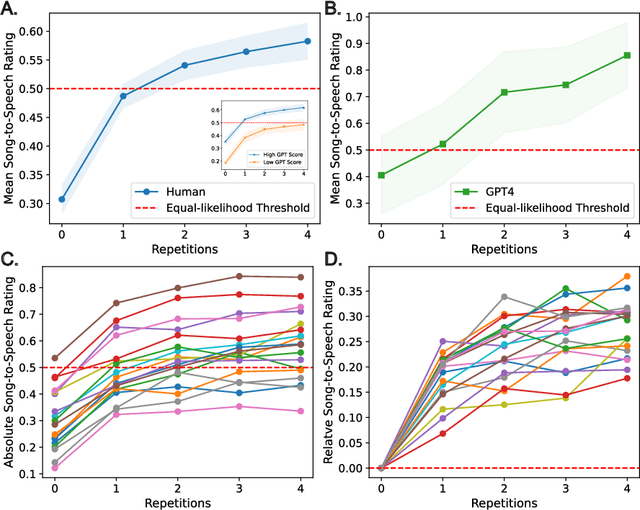
The speech-to-song illusion is a robust psychological phenomenon whereby a spoken sentence sounds increasingly more musical as it is repeated. Despite decades of research, a complete formal account of this transformation is still lacking, and some of its nuanced characteristics, namely, that certain phrases appear to transform while others do not, is not well understood. Here we provide a formal account of this phenomenon, by recasting it as a statistical inference whereby a rational agent attempts to decide whether a sequence of utterances is more likely to have been produced in a song or speech. Using this approach and analyzing song and speech corpora, we further introduce a novel prose-to-lyrics illusion that is purely text-based. In this illusion, simply duplicating written sentences makes them appear more like song lyrics. We provide robust evidence for this new illusion in both human participants and large language models.
Comparing Abstraction in Humans and Large Language Models Using Multimodal Serial Reproduction
Feb 06, 2024



Humans extract useful abstractions of the world from noisy sensory data. Serial reproduction allows us to study how people construe the world through a paradigm similar to the game of telephone, where one person observes a stimulus and reproduces it for the next to form a chain of reproductions. Past serial reproduction experiments typically employ a single sensory modality, but humans often communicate abstractions of the world to each other through language. To investigate the effect language on the formation of abstractions, we implement a novel multimodal serial reproduction framework by asking people who receive a visual stimulus to reproduce it in a linguistic format, and vice versa. We ran unimodal and multimodal chains with both humans and GPT-4 and find that adding language as a modality has a larger effect on human reproductions than GPT-4's. This suggests human visual and linguistic representations are more dissociable than those of GPT-4.
MacGyver: Are Large Language Models Creative Problem Solvers?
Nov 16, 2023



We explore the creative problem-solving capabilities of modern large language models (LLMs) in a constrained setting. The setting requires circumventing a cognitive bias known in psychology as ''functional fixedness'' to use familiar objects in innovative or unconventional ways. To this end, we create MacGyver, an automatically generated dataset consisting of 1,600 real-world problems that deliberately trigger functional fixedness and require thinking 'out-of-the-box'. We then present our collection of problems to both LLMs and humans to compare and contrast their problem-solving abilities. We show that MacGyver is challenging for both groups, but in unique and complementary ways. For example, humans typically excel in solving problems that they are familiar with but may struggle with tasks requiring domain-specific knowledge, leading to a higher variance. On the other hand, LLMs, being exposed to a variety of highly specialized knowledge, attempt broader problems but are prone to overconfidence and propose actions that are physically infeasible or inefficient. We also provide a detailed error analysis of LLMs, and demonstrate the potential of enhancing their problem-solving ability with novel prompting techniques such as iterative step-wise reflection and divergent-convergent thinking. This work provides insight into the creative problem-solving capabilities of humans and AI and illustrates how psychological paradigms can be extended into large-scale tasks for comparing humans and machines.
Improving Interpersonal Communication by Simulating Audiences with Language Models
Nov 03, 2023How do we communicate with others to achieve our goals? We use our prior experience or advice from others, or construct a candidate utterance by predicting how it will be received. However, our experiences are limited and biased, and reasoning about potential outcomes can be difficult and cognitively challenging. In this paper, we explore how we can leverage Large Language Model (LLM) simulations to help us communicate better. We propose the Explore-Generate-Simulate (EGS) framework, which takes as input any scenario where an individual is communicating to an audience with a goal they want to achieve. EGS (1) explores the solution space by producing a diverse set of advice relevant to the scenario, (2) generates communication candidates conditioned on subsets of the advice, and (3) simulates the reactions from various audiences to determine both the best candidate and advice to use. We evaluate the framework on eight scenarios spanning the ten fundamental processes of interpersonal communication. For each scenario, we collect a dataset of human evaluations across candidates and baselines, and showcase that our framework's chosen candidate is preferred over popular generation mechanisms including Chain-of-Thought. We also find that audience simulations achieve reasonably high agreement with human raters across 5 of the 8 scenarios. Finally, we demonstrate the generality of our framework by applying it to real-world scenarios described by users on web forums. Through evaluations and demonstrations, we show that EGS enhances the effectiveness and outcomes of goal-oriented communication across a variety of situations, thus opening up new possibilities for the application of large language models in revolutionizing communication and decision-making processes.