 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in the Maze: Overcoming Context Limitations in Long-Horizon Agentic Search
Oct 21, 2025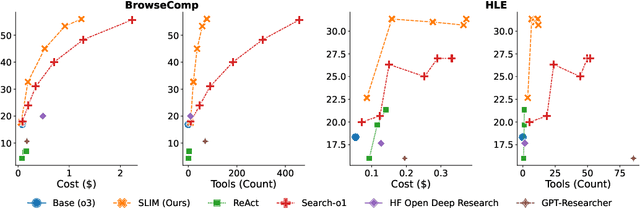



Long-horizon agentic search requires iteratively exploring the web over long trajectories and synthesizing information across many sources, and is the foundation for enabling powerful applications like deep research systems. In this work, we show that popular agentic search frameworks struggle to scale to long trajectories primarily due to context limitations-they accumulate long, noisy content, hit context window and tool budgets, or stop early. Then, we introduce SLIM (Simple Lightweight Information Management), a simple framework that separates retrieval into distinct search and browse tools, and periodically summarizes the trajectory, keeping context concise while enabling longer, more focused searches. On long-horizon tasks, SLIM achieves comparable performance at substantially lower cost and with far fewer tool calls than strong open-source baselines across multiple base models. Specifically, with o3 as the base model, SLIM achieves 56% on BrowseComp and 31% on HLE, outperforming all open-source frameworks by 8 and 4 absolute points, respectively, while incurring 4-6x fewer tool calls. Finally, we release an automated fine-grained trajectory analysis pipeline and error taxonomy for characterizing long-horizon agentic search frameworks; SLIM exhibits fewer hallucinations than prior systems. We hope our analysis framework and simple tool design inform future long-horizon agents.
Query-Focused Retrieval Heads Improve Long-Context Reasoning and Re-ranking
Jun 11, 2025Recent work has identified retrieval heads (Wu et al., 2025b), a subset of attention heads responsible for retrieving salient information in long-context language models (LMs), as measured by their copy-paste behavior in Needle-in-a-Haystack tasks. In this paper, we introduce QRHEAD (Query-Focused Retrieval Head), an improved set of attention heads that enhance retrieval from long context. We identify QRHEAD by aggregating attention scores with respect to the input query, using a handful of examples from real-world tasks (e.g., long-context QA). We further introduce QR- RETRIEVER, an efficient and effective retriever that uses the accumulated attention mass of QRHEAD as retrieval scores. We use QR- RETRIEVER for long-context reasoning by selecting the most relevant parts with the highest retrieval scores. On multi-hop reasoning tasks LongMemEval and CLIPPER, this yields over 10% performance gains over full context and outperforms strong dense retrievers. We also evaluate QRRETRIEVER as a re-ranker on the BEIR benchmark and find that it achieves strong zero-shot performance, outperforming other LLM-based re-rankers such as RankGPT. Further analysis shows that both the querycontext attention scoring and task selection are crucial for identifying QRHEAD with strong downstream utility. Overall, our work contributes a general-purpose retriever and offers interpretability insights into the long-context capabilities of LMs.
Precise Information Control in Long-Form Text Generation
Jun 06, 2025A central challenge in modern language models (LMs) is intrinsic hallucination: the generation of information that is plausible but unsubstantiated relative to input context. To study this problem, we propose Precise Information Control (PIC), a new task formulation that requires models to generate long-form outputs grounded in a provided set of short self-contained statements, known as verifiable claims, without adding any unsupported ones. For comprehensiveness, PIC includes a full setting that tests a model's ability to include exactly all input claims, and a partial setting that requires the model to selectively incorporate only relevant claims. We present PIC-Bench, a benchmark of eight long-form generation tasks (e.g., summarization, biography generation) adapted to the PIC setting, where LMs are supplied with well-formed, verifiable input claims. Our evaluation of a range of open and proprietary LMs on PIC-Bench reveals that, surprisingly, state-of-the-art LMs still intrinsically hallucinate in over 70% of outputs. To alleviate this lack of faithfulness, we introduce a post-training framework, using a weakly supervised preference data construction method, to train an 8B PIC-LM with stronger PIC ability--improving from 69.1% to 91.0% F1 in the full PIC setting. When integrated into end-to-end factual generation pipelines, PIC-LM improves exact match recall by 17.1% on ambiguous QA with retrieval, and factual precision by 30.5% on a birthplace verification task, underscoring the potential of precisely grounded generation.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
LongProc: Benchmarking Long-Context Language Models on Long Procedural Generation
Jan 09, 2025



Existing benchmarks for evaluating long-context language models (LCLMs) primarily focus on long-context recall, requiring models to produce short responses based on a few critical snippets while processing thousands of irrelevant tokens. We introduce LongProc (Long Procedural Generation), a new benchmark that requires both the integration of highly dispersed information and long-form generation. LongProc consists of six diverse procedural generation tasks, such as extracting structured information from HTML pages into a TSV format and executing complex search procedures to create travel plans. These tasks challenge LCLMs by testing their ability to follow detailed procedural instructions, synthesize and reason over dispersed information, and generate structured, long-form outputs (up to 8K tokens). Furthermore, as these tasks adhere to deterministic procedures and yield structured outputs, they enable reliable rule-based evaluation. We evaluate 17 LCLMs on LongProc across three difficulty levels, with maximum numbers of output tokens set at 500, 2K, and 8K. Notably, while all tested models claim a context window size above 32K tokens, open-weight models typically falter on 2K-token tasks, and closed-source models like GPT-4o show significant degradation on 8K-token tasks. Further analysis reveals that LCLMs struggle to maintain long-range coherence in long-form generations. These findings highlight critical limitations in current LCLMs and suggest substantial room for improvement. Data and code available at: https://princeton-pli.github.io/LongProc
How to Train Long-Context Language Models (Effectively)
Oct 03, 2024We study continued training and supervised fine-tuning (SFT) of a language model (LM) to make effective use of long-context information. We first establish a reliable evaluation protocol to guide model development -- Instead of perplexity or simple needle-in-a-haystack (NIAH) tests, we use a broad set of long-context tasks, and we evaluate models after SFT with instruction data as this better reveals long-context abilities. Supported by our robust evaluations, we run thorough experiments to decide the data mix for continued pre-training, the instruction tuning dataset, and many other design choices. We find that (1) code repositories and books are excellent sources of long data, but it is crucial to combine them with high-quality short data; (2) training with a sequence length beyond the evaluation length boosts long-context performance; (3) for SFT, using only short instruction datasets yields strong performance on long-context tasks. Our final model, ProLong-8B, which is initialized from Llama-3 and trained on 40B tokens, demonstrates state-of-the-art long-context performance among similarly sized models at a length of 128K. ProLong outperforms Llama-3.18B-Instruct on the majority of long-context tasks despite having seen only 5% as many tokens during long-context training. Additionally, ProLong can effectively process up to 512K tokens, one of the longest context windows of publicly available LMs.
HELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly
Oct 03, 2024


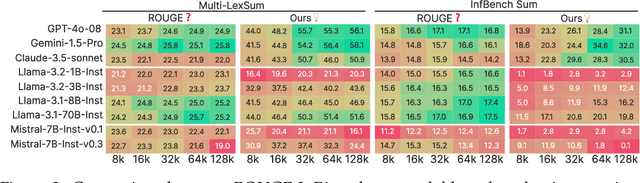
There have been many benchmarks for evaluating long-context language models (LCLMs), but developers often rely on synthetic tasks like needle-in-a-haystack (NIAH) or arbitrary subsets of tasks. It remains unclear whether they translate to the diverse downstream applications of LCLMs, and the inconsistency further complicates model comparison. We investigate the underlying reasons behind current practices and find that existing benchmarks often provide noisy signals due to low coverage of applications, insufficient lengths, unreliable metrics, and incompatibility with base models. In this work, we present HELMET (How to Evaluate Long-context Models Effectively and Thoroughly), a comprehensive benchmark encompassing seven diverse, application-centric categories. We also address many issues in previous benchmarks by adding controllable lengths up to 128k tokens, model-based evaluation for reliable metrics, and few-shot prompting for robustly evaluating base models. Consequently, we demonstrate that HELMET offers more reliable and consistent rankings of frontier LCLMs. Through a comprehensive study of 51 LCLMs, we find that (1) synthetic tasks like NIAH are not good predictors of downstream performance; (2) the diverse categories in HELMET exhibit distinct trends and low correlation with each other; and (3) while most LCLMs achieve perfect NIAH scores, open-source models significantly lag behind closed ones when the task requires full-context reasoning or following complex instructions -- the gap widens with increased lengths. Finally, we recommend using our RAG tasks for fast model development, as they are easy to run and more predictive of other downstream performance; ultimately, we advocate for a holistic evaluation across diverse tasks.
BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval
Jul 16, 2024



Existing retrieval benchmarks primarily consist of information-seeking queries (e.g., aggregated questions from search engines) where keyword or semantic-based retrieval is usually sufficient. However, many complex real-world queries require in-depth reasoning to identify relevant documents that go beyond surface form matching. For example, finding documentation for a coding question requires understanding the logic and syntax of the functions involved. To better benchmark retrieval on such challenging queries, we introduce BRIGHT, the first text retrieval benchmark that requires intensive reasoning to retrieve relevant documents. BRIGHT is constructed from the 1,398 real-world queries collected from diverse domains (such as economics, psychology, robotics, software engineering, earth sciences, etc.), sourced from naturally occurring or carefully curated human data. Extensive evaluation reveals that even state-of-the-art retrieval models perform poorly on BRIGHT. The leading model on the MTEB leaderboard [38 ], which achieves a score of 59.0 nDCG@10,2 produces a score of nDCG@10 of 18.0 on BRIGHT. We further demonstrate that augmenting queries with Chain-of-Thought reasoning generated by large language models (LLMs) improves performance by up to 12.2 points. Moreover, BRIGHT is robust against data leakage during pretraining of the benchmarked models as we validate by showing similar performance even when documents from the benchmark are included in the training data. We believe that BRIGHT paves the way for future research on retrieval systems in more realistic and challenging settings. Our code and data are available at https://brightbenchmark.github.io.
Long-Context Language Modeling with Parallel Context Encoding
Feb 26, 2024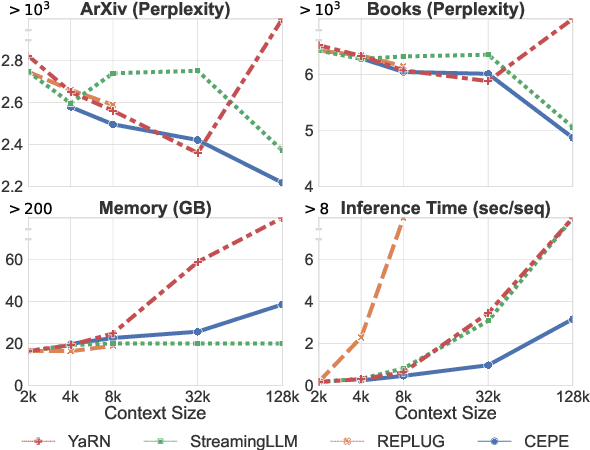
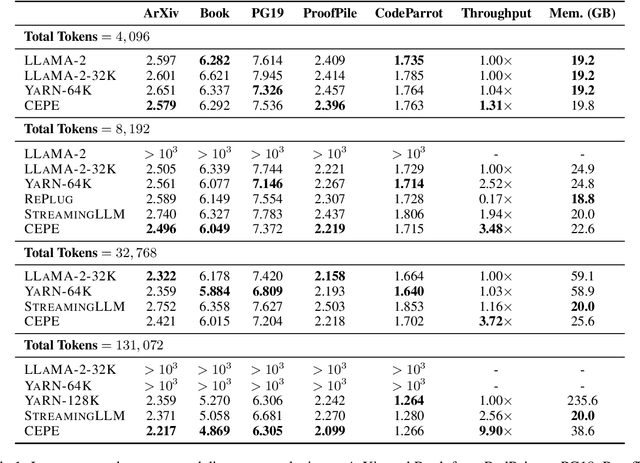
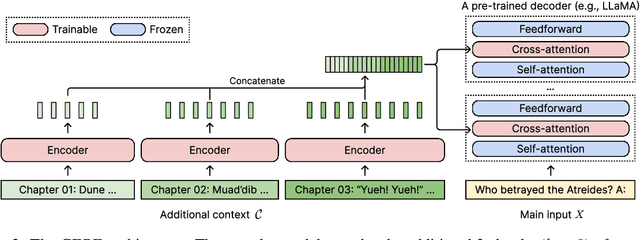
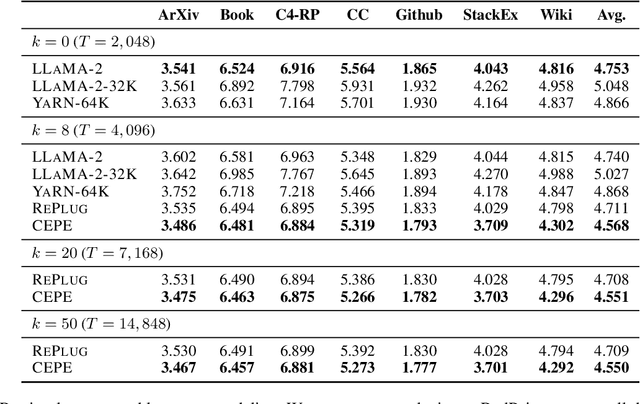
Extending large language models (LLMs) to process longer inputs is crucial for numerous applications. However, the considerable computational cost of transformers, coupled with limited generalization of positional encoding, restricts the size of their context window. We introduce Context Expansion with Parallel Encoding (CEPE), a framework that can be applied to any existing decoder-only LLMs to extend their context window. CEPE adopts a small encoder to process long inputs chunk by chunk and enables the frozen decoder to leverage additional contexts via cross-attention. CEPE is efficient, generalizable, and versatile: trained with 8K-token documents, CEPE extends the context window of LLAMA-2 to 128K tokens, offering 10x the throughput with only 1/6 of the memory. CEPE yields strong performance on language modeling and in-context learning. CEPE also excels in retrieval-augmented applications, while existing long-context models degenerate with retrieved contexts. We further introduce a CEPE variant that can extend the context window of instruction-tuned models with only unlabeled data, and showcase its effectiveness on LLAMA-2-CHAT, leading to a strong instruction-following model that can leverage very long context on downstream tasks.
Improving Interpersonal Communication by Simulating Audiences with Language Models
Nov 03, 2023How do we communicate with others to achieve our goals? We use our prior experience or advice from others, or construct a candidate utterance by predicting how it will be received. However, our experiences are limited and biased, and reasoning about potential outcomes can be difficult and cognitively challenging. In this paper, we explore how we can leverage Large Language Model (LLM) simulations to help us communicate better. We propose the Explore-Generate-Simulate (EGS) framework, which takes as input any scenario where an individual is communicating to an audience with a goal they want to achieve. EGS (1) explores the solution space by producing a diverse set of advice relevant to the scenario, (2) generates communication candidates conditioned on subsets of the advice, and (3) simulates the reactions from various audiences to determine both the best candidate and advice to use. We evaluate the framework on eight scenarios spanning the ten fundamental processes of interpersonal communication. For each scenario, we collect a dataset of human evaluations across candidates and baselines, and showcase that our framework's chosen candidate is preferred over popular generation mechanisms including Chain-of-Thought. We also find that audience simulations achieve reasonably high agreement with human raters across 5 of the 8 scenarios. Finally, we demonstrate the generality of our framework by applying it to real-world scenarios described by users on web forums. Through evaluations and demonstrations, we show that EGS enhances the effectiveness and outcomes of goal-oriented communication across a variety of situations, thus opening up new possibilities for the application of large language models in revolutionizing communication and decision-making processes.