 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Context Language Modeling with Parallel Context Encoding
Paper and Code
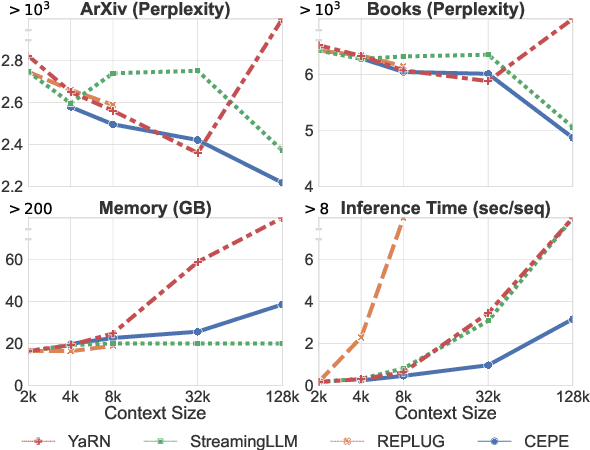
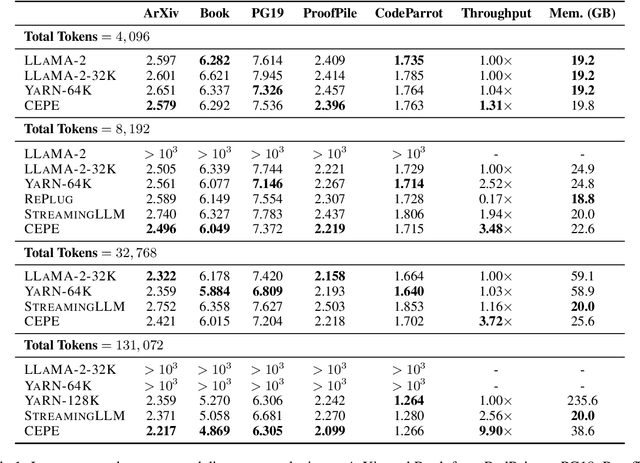
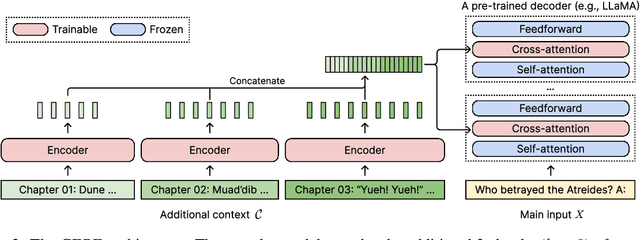
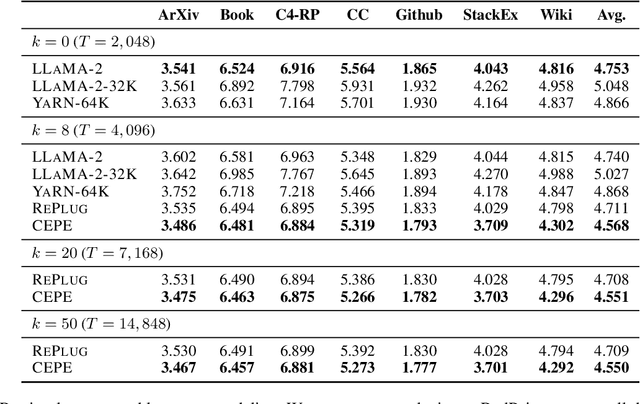
Extending large language models (LLMs) to process longer inputs is crucial for numerous applications. However, the considerable computational cost of transformers, coupled with limited generalization of positional encoding, restricts the size of their context window. We introduce Context Expansion with Parallel Encoding (CEPE), a framework that can be applied to any existing decoder-only LLMs to extend their context window. CEPE adopts a small encoder to process long inputs chunk by chunk and enables the frozen decoder to leverage additional contexts via cross-attention. CEPE is efficient, generalizable, and versatile: trained with 8K-token documents, CEPE extends the context window of LLAMA-2 to 128K tokens, offering 10x the throughput with only 1/6 of the memory. CEPE yields strong performance on language modeling and in-context learning. CEPE also excels in retrieval-augmented applications, while existing long-context models degenerate with retrieved contexts. We further introduce a CEPE variant that can extend the context window of instruction-tuned models with only unlabeled data, and showcase its effectiveness on LLAMA-2-CHAT, leading to a strong instruction-following model that can leverage very long context on downstream tasks.