 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly
Paper and Code



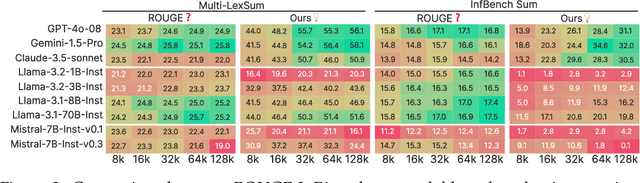
There have been many benchmarks for evaluating long-context language models (LCLMs), but developers often rely on synthetic tasks like needle-in-a-haystack (NIAH) or arbitrary subsets of tasks. It remains unclear whether they translate to the diverse downstream applications of LCLMs, and the inconsistency further complicates model comparison. We investigate the underlying reasons behind current practices and find that existing benchmarks often provide noisy signals due to low coverage of applications, insufficient lengths, unreliable metrics, and incompatibility with base models. In this work, we present HELMET (How to Evaluate Long-context Models Effectively and Thoroughly), a comprehensive benchmark encompassing seven diverse, application-centric categories. We also address many issues in previous benchmarks by adding controllable lengths up to 128k tokens, model-based evaluation for reliable metrics, and few-shot prompting for robustly evaluating base models. Consequently, we demonstrate that HELMET offers more reliable and consistent rankings of frontier LCLMs. Through a comprehensive study of 51 LCLMs, we find that (1) synthetic tasks like NIAH are not good predictors of downstream performance; (2) the diverse categories in HELMET exhibit distinct trends and low correlation with each other; and (3) while most LCLMs achieve perfect NIAH scores, open-source models significantly lag behind closed ones when the task requires full-context reasoning or following complex instructions -- the gap widens with increased lengths. Finally, we recommend using our RAG tasks for fast model development, as they are easy to run and more predictive of other downstream performance; ultimately, we advocate for a holistic evaluation across diverse tasks.