 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
MI-DPG: Decomposable Parameter Generation Network Based on Mutual Information for Multi-Scenario Recommendation
Mar 22, 2026Conversion rate (CVR) prediction models play a vital role in recommendation and advertising systems. Recent research on multi-scenario recommendation shows that learning a unified model to serve multiple scenarios is effective for improving overall performance. However, it remains challenging to improve model prediction performance across scenarios at low model parameter cost, and current solutions are hard to robustly model multi-scenario diversity. In this paper, we propose MI-DPG for the multi-scenario CVR prediction, which learns scenario-conditioned dynamic model parameters for each scenario in a more efficient and effective manner. Specifically, we introduce an auxiliary network to generate scenario-conditioned dynamic weighting matrices, which are obtained by combining decomposed scenario-specific and scenario-shared low-rank matrices with parameter efficiency. For each scene, weighting the backbone model parameters by the weighting matrix helps to specialize the model parameters for different scenarios. It can not only modulate the complete parameter space of the backbone model but also improve the model effectiveness. Furthermore, we design a mutual information regularization to enhance the diversity of model parameters across different scenarios by maximizing the mutual information between the scenario-aware input and the scene-conditioned dynamic weighting matrix. Experiments from three real-world datasets show that MI-DPG significantly outperforms previous multi-scenario recommendation models.
* Accepted by CIKM 2023
Trie-Aware Transformers for Generative Recommendation
Feb 25, 2026Generative recommendation (GR) aligns with advances in generative AI by casting next-item prediction as token-level generation rather than score-based ranking. Most GR methods adopt a two-stage pipeline: (i) \textit{item tokenization}, which maps each item to a sequence of discrete, hierarchically organized tokens; and (ii) \textit{autoregressive generation}, which predicts the next item's tokens conditioned on the tokens of user's interaction history. Although hierarchical tokenization induces a prefix tree (trie) over items, standard autoregressive modeling with conventional Transformers often flattens item tokens into a linear stream and overlooks the underlying topology. To address this, we propose TrieRec, a trie-aware generative recommendation method that augments Transformers with structural inductive biases via two positional encodings. First, a \textit{trie-aware absolute positional encoding} aggregates a token's (node's) local structural context (\eg depth, ancestors, and descendants) into the token representation. Second, a \textit{topology-aware relative positional encoding} injects pairwise structural relations into self-attention to capture topology-induced semantic relatedness. TrieRec is also model-agnostic, efficient, and hyperparameter-free. In our experiments, we implement TrieRec within three representative GR backbones, achieving notably improvements of 8.83\% on average across four real-world datasets.
HELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly
Oct 03, 2024


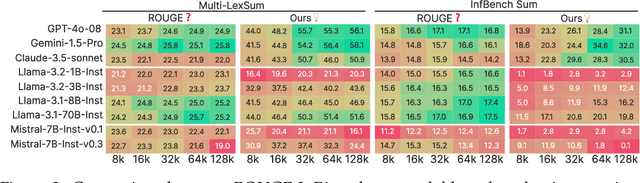
There have been many benchmarks for evaluating long-context language models (LCLMs), but developers often rely on synthetic tasks like needle-in-a-haystack (NIAH) or arbitrary subsets of tasks. It remains unclear whether they translate to the diverse downstream applications of LCLMs, and the inconsistency further complicates model comparison. We investigate the underlying reasons behind current practices and find that existing benchmarks often provide noisy signals due to low coverage of applications, insufficient lengths, unreliable metrics, and incompatibility with base models. In this work, we present HELMET (How to Evaluate Long-context Models Effectively and Thoroughly), a comprehensive benchmark encompassing seven diverse, application-centric categories. We also address many issues in previous benchmarks by adding controllable lengths up to 128k tokens, model-based evaluation for reliable metrics, and few-shot prompting for robustly evaluating base models. Consequently, we demonstrate that HELMET offers more reliable and consistent rankings of frontier LCLMs. Through a comprehensive study of 51 LCLMs, we find that (1) synthetic tasks like NIAH are not good predictors of downstream performance; (2) the diverse categories in HELMET exhibit distinct trends and low correlation with each other; and (3) while most LCLMs achieve perfect NIAH scores, open-source models significantly lag behind closed ones when the task requires full-context reasoning or following complex instructions -- the gap widens with increased lengths. Finally, we recommend using our RAG tasks for fast model development, as they are easy to run and more predictive of other downstream performance; ultimately, we advocate for a holistic evaluation across diverse tasks.
MSR-86K: An Evolving, Multilingual Corpus with 86,300 Hours of Transcribed Audio for Speech Recognition Research
Jun 26, 2024
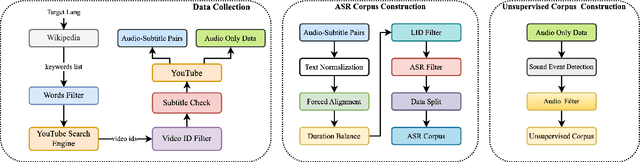


Recently, multilingual artificial intelligence assistants, exemplified by ChatGPT, have gained immense popularity. As a crucial gateway to human-computer interaction, multilingual automatic speech recognition (ASR) has also garnered significant attention, as evidenced by systems like Whisper. However, the proprietary nature of the training data has impeded researchers' efforts to study multilingual ASR. This paper introduces MSR-86K, an evolving, large-scale multilingual corpus for speech recognition research. The corpus is derived from publicly accessible videos on YouTube, comprising 15 languages and a total of 86,300 hours of transcribed ASR data. We also introduce how to use the MSR-86K corpus and other open-source corpora to train a robust multilingual ASR model that is competitive with Whisper. MSR-86K will be publicly released on HuggingFace, and we believe that such a large corpus will pave new avenues for research in multilingual ASR.
Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models
May 24, 2024
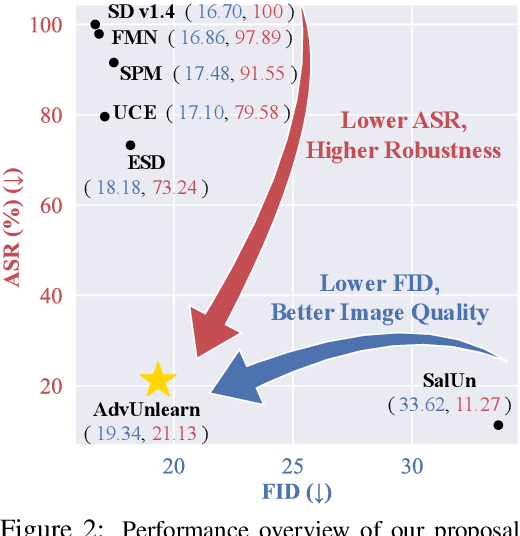
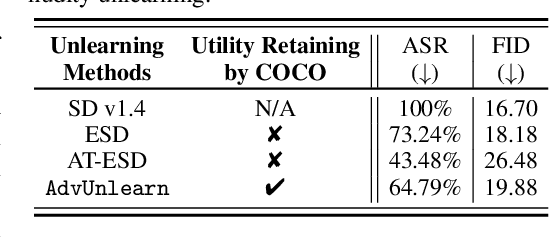

Diffusion models (DMs) have achieved remarkable success in text-to-image generation, but they also pose safety risks, such as the potential generation of harmful content and copyright violations. The techniques of machine unlearning, also known as concept erasing, have been developed to address these risks. However, these techniques remain vulnerable to adversarial prompt attacks, which can prompt DMs post-unlearning to regenerate undesired images containing concepts (such as nudity) meant to be erased. This work aims to enhance the robustness of concept erasing by integrating the principle of adversarial training (AT) into machine unlearning, resulting in the robust unlearning framework referred to as AdvUnlearn. However, achieving this effectively and efficiently is highly nontrivial. First, we find that a straightforward implementation of AT compromises DMs' image generation quality post-unlearning. To address this, we develop a utility-retaining regularization on an additional retain set, optimizing the trade-off between concept erasure robustness and model utility in AdvUnlearn. Moreover, we identify the text encoder as a more suitable module for robustification compared to UNet, ensuring unlearning effectiveness. And the acquired text encoder can serve as a plug-and-play robust unlearner for various DM types. Empirically, we perform extensive experiments to demonstrate the robustness advantage of AdvUnlearn across various DM unlearning scenarios, including the erasure of nudity, objects, and style concepts. In addition to robustness, AdvUnlearn also achieves a balanced tradeoff with model utility. To our knowledge, this is the first work to systematically explore robust DM unlearning through AT, setting it apart from existing methods that overlook robustness in concept erasing. Codes are available at: https://github.com/OPTML-Group/AdvUnlearn
Learning to Maximize Mutual Information for Chain-of-Thought Distillation
Mar 05, 2024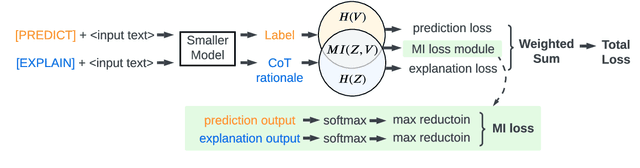
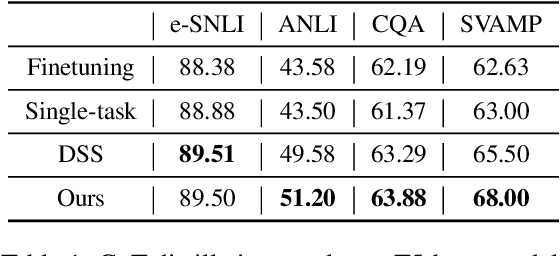
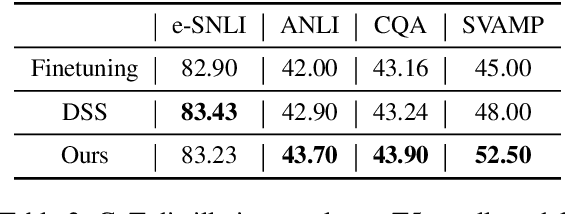
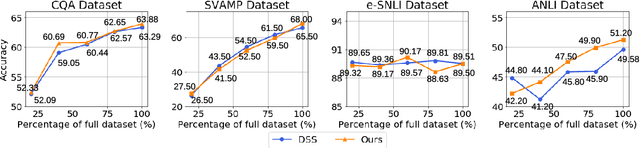
Knowledge distillation, the technique of transferring knowledge from large, complex models to smaller ones, marks a pivotal step towards efficient AI deployment. Distilling Step-by-Step (DSS), a novel method utilizing chain-of-thought (CoT) distillation, has demonstrated promise by imbuing smaller models with the superior reasoning capabilities of their larger counterparts. In DSS, the distilled model acquires the ability to generate rationales and predict labels concurrently through a multi-task learning framework. However, DSS overlooks the intrinsic relationship between the two training tasks, leading to ineffective integration of CoT knowledge with the task of label prediction. To this end, we investigate the mutual relationship of the two tasks from Information Bottleneck perspective and formulate it as maximizing the mutual information of the representation features of the two tasks. We propose a variational approach to solve this optimization problem using a learning-based method. Our experimental results across four datasets demonstrate that our method outperforms the state-of-the-art DSS. Our findings offer insightful guidance for future research on language model distillation as well as applications involving CoT. Code and models will be released soon.
To Generate or Not? Safety-Driven Unlearned Diffusion Models Are Still Easy To Generate Unsafe Images For Now
Oct 18, 2023The recent advances in diffusion models (DMs) have revolutionized the generation of complex and diverse images. However, these models also introduce potential safety hazards, such as the production of harmful content and infringement of data copyrights. Although there have been efforts to create safety-driven unlearning methods to counteract these challenges, doubts remain about their capabilities. To bridge this uncertainty, we propose an evaluation framework built upon adversarial attacks (also referred to as adversarial prompts), in order to discern the trustworthiness of these safety-driven unlearned DMs. Specifically, our research explores the (worst-case) robustness of unlearned DMs in eradicating unwanted concepts, styles, and objects, assessed by the generation of adversarial prompts. We develop a novel adversarial learning approach called UnlearnDiff that leverages the inherent classification capabilities of DMs to streamline the generation of adversarial prompts, making it as simple for DMs as it is for image classification attacks. This technique streamlines the creation of adversarial prompts, making the process as intuitive for generative modeling as it is for image classification assaults. Through comprehensive benchmarking, we assess the unlearning robustness of five prevalent unlearned DMs across multiple tasks. Our results underscore the effectiveness and efficiency of UnlearnDiff when compared to state-of-the-art adversarial prompting methods. Codes are available at https://github.com/OPTML-Group/Diffusion-MU-Attack. WARNING: This paper contains model outputs that may be offensive in nature.
CPPF: A contextual and post-processing-free model for automatic speech recognition
Sep 21, 2023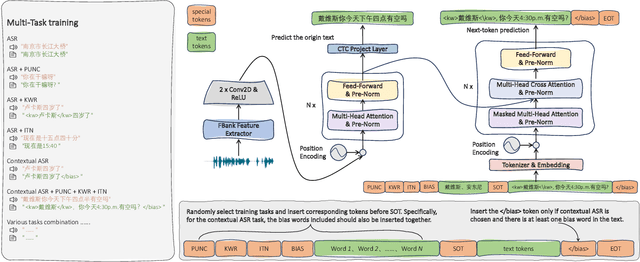
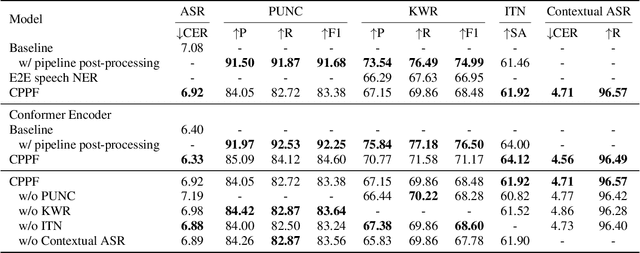

ASR systems have become increasingly widespread in recent years. However, their textual outputs often require post-processing tasks before they can be practically utilized. To address this issue, we draw inspiration from the multifaceted capabilities of LLMs and Whisper, and focus on integrating multiple ASR text processing tasks related to speech recognition into the ASR model. This integration not only shortens the multi-stage pipeline, but also prevents the propagation of cascading errors, resulting in direct generation of post-processed text. In this study, we focus on ASR-related processing tasks, including Contextual ASR and multiple ASR post processing tasks. To achieve this objective, we introduce the CPPF model, which offers a versatile and highly effective alternative to ASR processing. CPPF seamlessly integrates these tasks without any significant loss in recognition performance.
Enhancing Multilingual Speech Recognition through Language Prompt Tuning and Frame-Level Language Adapter
Sep 19, 2023
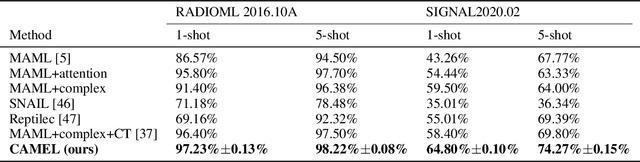

Multilingual intelligent assistants, such as ChatGPT, have recently gained popularity. To further expand the applications of multilingual artificial intelligence assistants and facilitate international communication, it is essential to enhance the performance of multilingual speech recognition, which is a crucial component of speech interaction. In this paper, we propose two simple and parameter-efficient methods: language prompt tuning and frame-level language adapter, to respectively enhance language-configurable and language-agnostic multilingual speech recognition. Additionally, we explore the feasibility of integrating these two approaches using parameter-efficient fine-tuning methods. Our experiments demonstrate significant performance improvements across seven languages using our proposed methods.