 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
Unifying Bayesian Flow Networks and Diffusion Models through Stochastic Differential Equations
Apr 24, 2024
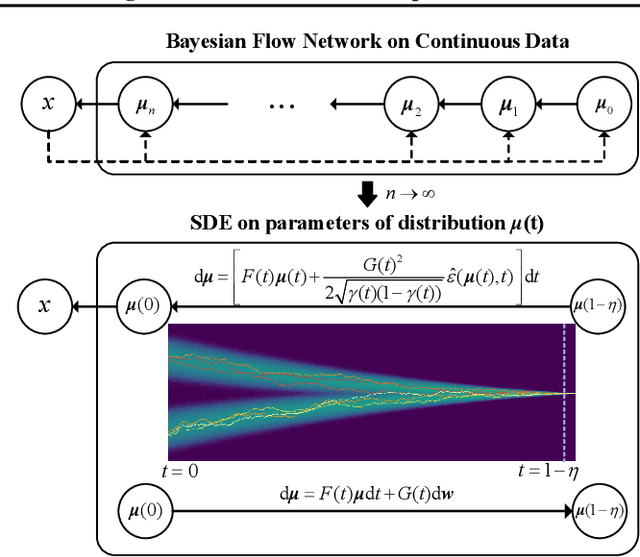
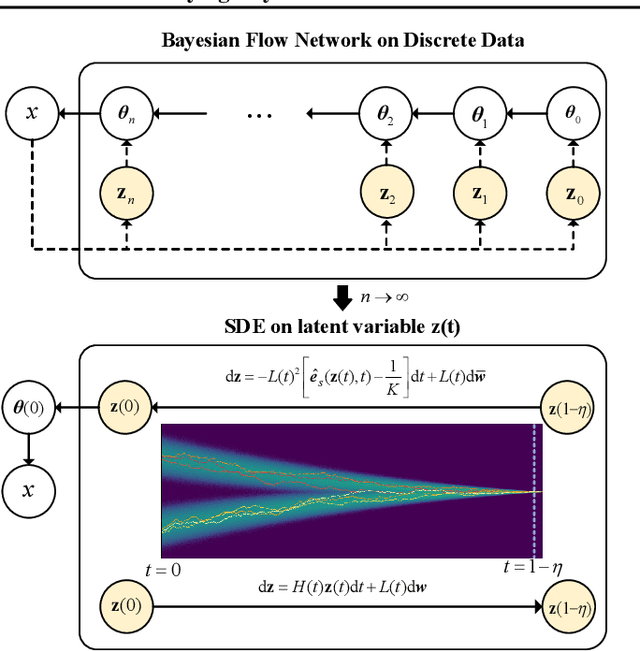

Bayesian flow networks (BFNs) iteratively refine the parameters, instead of the samples in diffusion models (DMs), of distributions at various noise levels through Bayesian inference. Owing to its differentiable nature, BFNs are promising in modeling both continuous and discrete data, while simultaneously maintaining fast sampling capabilities. This paper aims to understand and enhance BFNs by connecting them with DMs through stochastic differential equations (SDEs). We identify the linear SDEs corresponding to the noise-addition processes in BFNs, demonstrate that BFN's regression losses are aligned with denoise score matching, and validate the sampler in BFN as a first-order solver for the respective reverse-time SDE. Based on these findings and existing recipes of fast sampling in DMs, we propose specialized solvers for BFNs that markedly surpass the original BFN sampler in terms of sample quality with a limited number of function evaluations (e.g., 10) on both image and text datasets. Notably, our best sampler achieves an increase in speed of 5~20 times for free. Our code is available at https://github.com/ML-GSAI/BFN-Solver.
AntM$^{2}$C: A Large Scale Dataset For Multi-Scenario Multi-Modal CTR Prediction
Aug 31, 2023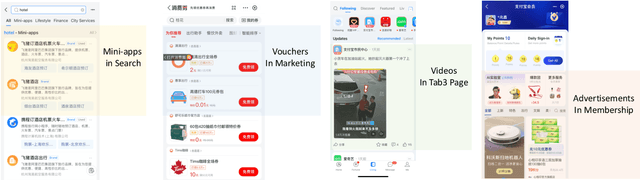

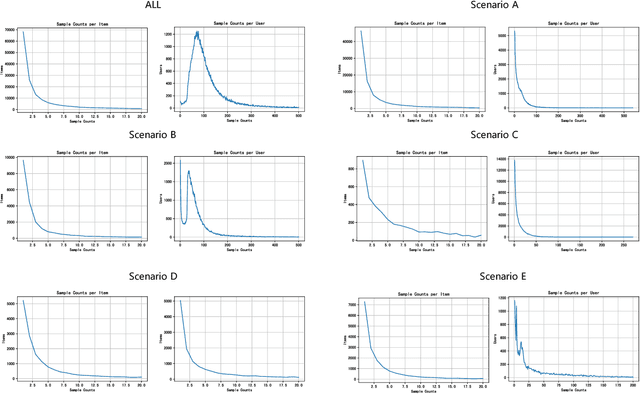

Click-through rate (CTR) prediction is a crucial issue in recommendation systems. There has been an emergence of various public CTR datasets. However, existing datasets primarily suffer from the following limitations. Firstly, users generally click different types of items from multiple scenarios, and modeling from multiple scenarios can provide a more comprehensive understanding of users. Existing datasets only include data for the same type of items from a single scenario. Secondly, multi-modal features are essential in multi-scenario prediction as they address the issue of inconsistent ID encoding between different scenarios. The existing datasets are based on ID features and lack multi-modal features. Third, a large-scale dataset can provide a more reliable evaluation of models, fully reflecting the performance differences between models. The scale of existing datasets is around 100 million, which is relatively small compared to the real-world CTR prediction. To address these limitations, we propose AntM$^{2}$C, a Multi-Scenario Multi-Modal CTR dataset based on industrial data from Alipay. Specifically, AntM$^{2}$C provides the following advantages: 1) It covers CTR data of 5 different types of items, providing insights into the preferences of users for different items, including advertisements, vouchers, mini-programs, contents, and videos. 2) Apart from ID-based features, AntM$^{2}$C also provides 2 multi-modal features, raw text and image features, which can effectively establish connections between items with different IDs. 3) AntM$^{2}$C provides 1 billion CTR data with 200 features, including 200 million users and 6 million items. It is currently the largest-scale CTR dataset available. Based on AntM$^{2}$C, we construct several typical CTR tasks and provide comparisons with baseline methods. The dataset homepage is available at https://www.atecup.cn/home.
Blending Knowledge in Deep Recurrent Networks for Adverse Event Prediction at Hospital Discharge
Apr 09, 2021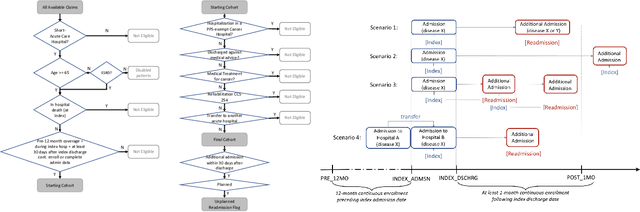
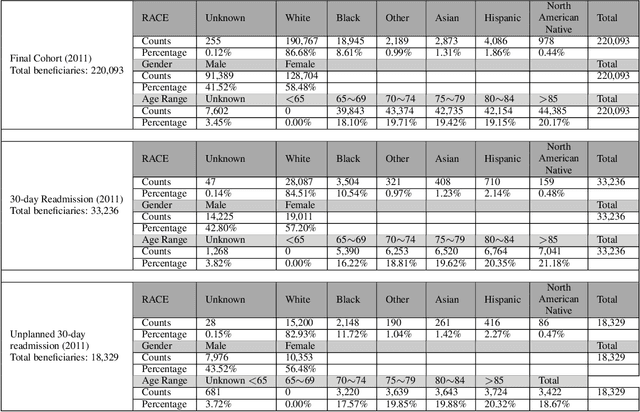
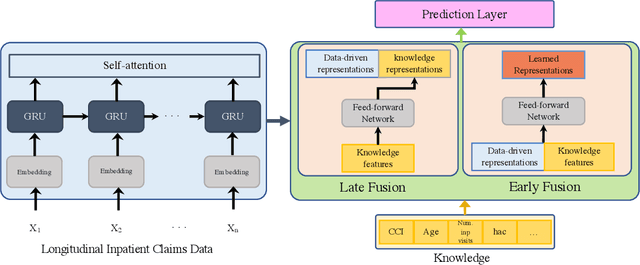

Deep learning architectures have an extremely high-capacity for modeling complex data in a wide variety of domains. However, these architectures have been limited in their ability to support complex prediction problems using insurance claims data, such as readmission at 30 days, mainly due to data sparsity issue. Consequently, classical machine learning methods, especially those that embed domain knowledge in handcrafted features, are often on par with, and sometimes outperform, deep learning approaches. In this paper, we illustrate how the potential of deep learning can be achieved by blending domain knowledge within deep learning architectures to predict adverse events at hospital discharge, including readmissions. More specifically, we introduce a learning architecture that fuses a representation of patient data computed by a self-attention based recurrent neural network, with clinically relevant features. We conduct extensive experiments on a large claims dataset and show that the blended method outperforms the standard machine learning approaches.
Dynamic Knowledge Distillation for Black-box Hypothesis Transfer Learning
Aug 07, 2020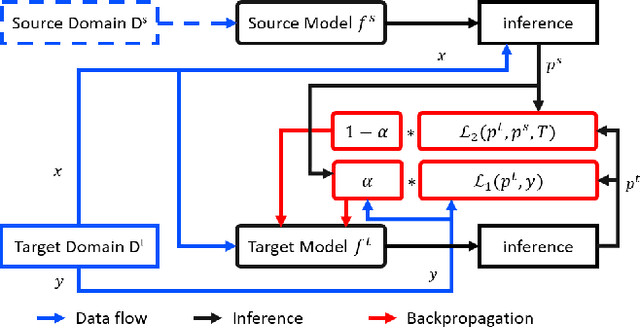
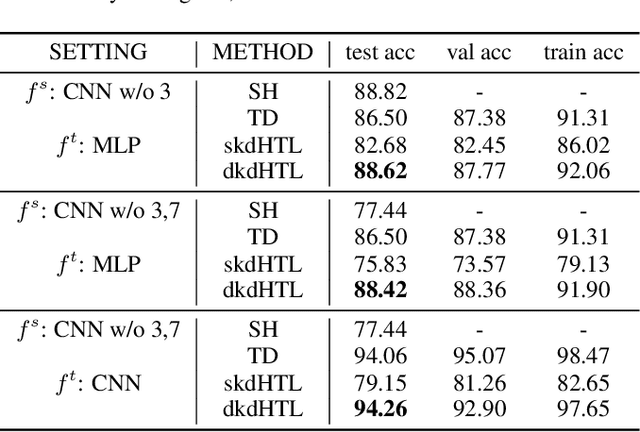
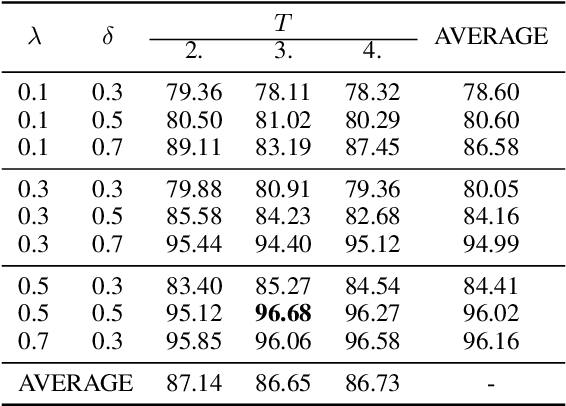
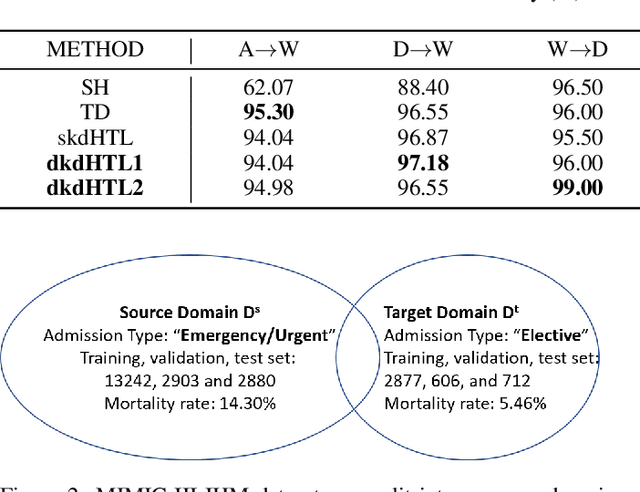
In real world applications like healthcare, it is usually difficult to build a machine learning prediction model that works universally well across different institutions. At the same time, the available model is often proprietary, i.e., neither the model parameter nor the data set used for model training is accessible. In consequence, leveraging the knowledge hidden in the available model (aka. the hypothesis) and adapting it to a local data set becomes extremely challenging. Motivated by this situation, in this paper we aim to address such a specific case within the hypothesis transfer learning framework, in which 1) the source hypothesis is a black-box model and 2) the source domain data is unavailable. In particular, we introduce a novel algorithm called dynamic knowledge distillation for hypothesis transfer learning (dkdHTL). In this method, we use knowledge distillation with instance-wise weighting mechanism to adaptively transfer the "dark" knowledge from the source hypothesis to the target domain.The weighting coefficients of the distillation loss and the standard loss are determined by the consistency between the predicted probability of the source hypothesis and the target ground-truth label.Empirical results on both transfer learning benchmark datasets and a healthcare dataset demonstrate the effectiveness of our method.
The NIPS'17 Competition: A Multi-View Ensemble Classification Model for Clinically Actionable Genetic Mutations
Jun 26, 2018
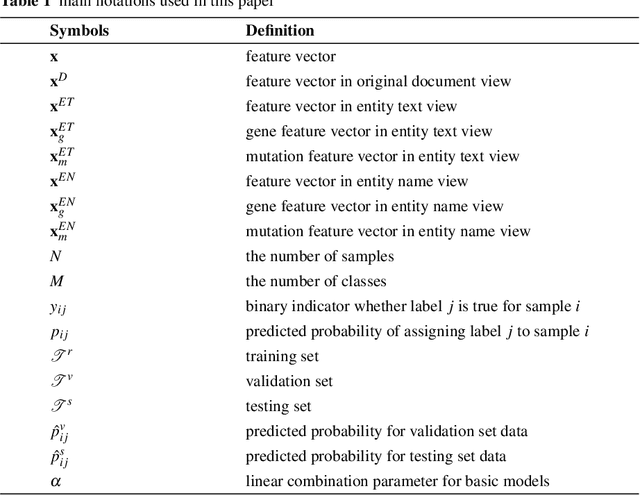
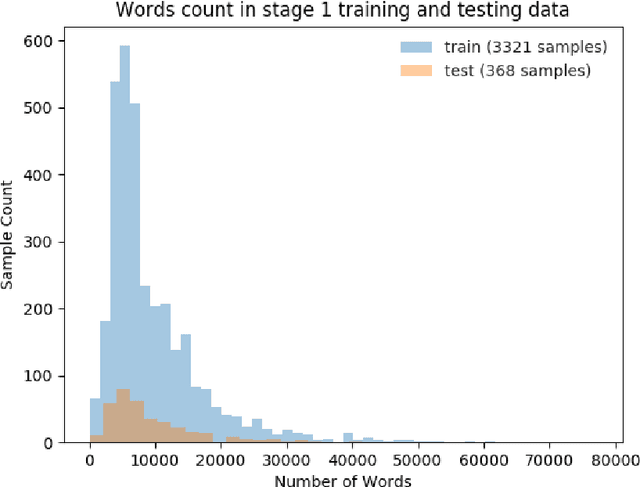

This paper presents details of our winning solutions to the task IV of NIPS 2017 Competition Track entitled Classifying Clinically Actionable Genetic Mutations. The machine learning task aims to classify genetic mutations based on text evidence from clinical literature with promising performance. We develop a novel multi-view machine learning framework with ensemble classification models to solve the problem. During the Challenge, feature combinations derived from three views including document view, entity text view, and entity name view, which complements each other, are comprehensively explored. As the final solution, we submitted an ensemble of nine basic gradient boosting models which shows the best performance in the evaluation. The approach scores 0.5506 and 0.6694 in terms of logarithmic loss on a fixed split in stage-1 testing phase and 5-fold cross validation respectively, which also makes us ranked as a top-1 team out of more than 1,300 solutions in NIPS 2017 Competition Track IV.