 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Effective, Low Latency Vector Search with Azure Cosmos DB
May 09, 2025Vector indexing enables semantic search over diverse corpora and has become an important interface to databases for both users and AI agents. Efficient vector search requires deep optimizations in database systems. This has motivated a new class of specialized vector databases that optimize for vector search quality and cost. Instead, we argue that a scalable, high-performance, and cost-efficient vector search system can be built inside a cloud-native operational database like Azure Cosmos DB while leveraging the benefits of a distributed database such as high availability, durability, and scale. We do this by deeply integrating DiskANN, a state-of-the-art vector indexing library, inside Azure Cosmos DB NoSQL. This system uses a single vector index per partition stored in existing index trees, and kept in sync with underlying data. It supports < 20ms query latency over an index spanning 10 million of vectors, has stable recall over updates, and offers nearly 15x and 41x lower query cost compared to Zilliz and Pinecone serverless enterprise products. It also scales out to billions of vectors via automatic partitioning. This convergent design presents a point in favor of integrating vector indices into operational databases in the context of recent debates on specialized vector databases, and offers a template for vector indexing in other databases.
Blending Knowledge in Deep Recurrent Networks for Adverse Event Prediction at Hospital Discharge
Apr 09, 2021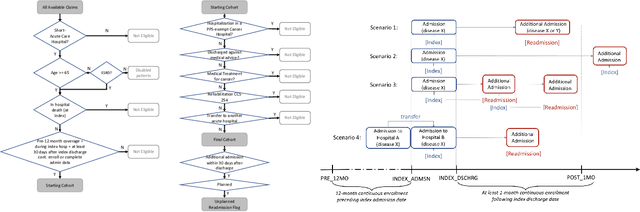
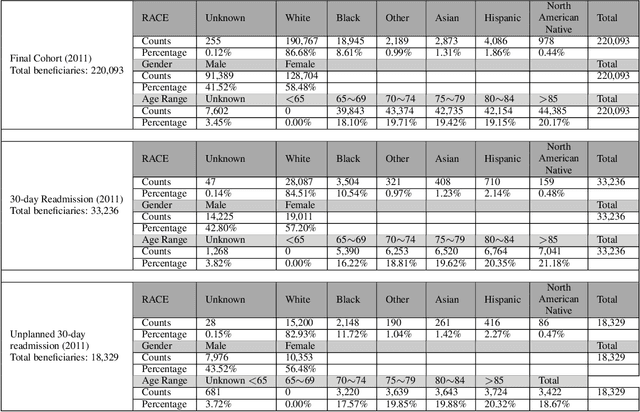
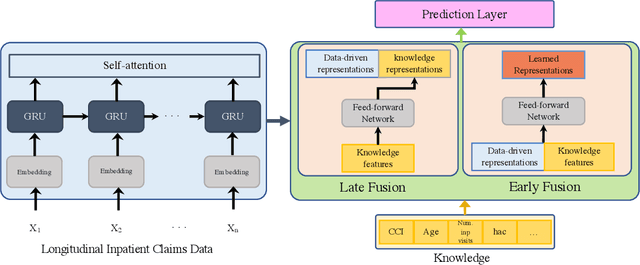

Deep learning architectures have an extremely high-capacity for modeling complex data in a wide variety of domains. However, these architectures have been limited in their ability to support complex prediction problems using insurance claims data, such as readmission at 30 days, mainly due to data sparsity issue. Consequently, classical machine learning methods, especially those that embed domain knowledge in handcrafted features, are often on par with, and sometimes outperform, deep learning approaches. In this paper, we illustrate how the potential of deep learning can be achieved by blending domain knowledge within deep learning architectures to predict adverse events at hospital discharge, including readmissions. More specifically, we introduce a learning architecture that fuses a representation of patient data computed by a self-attention based recurrent neural network, with clinically relevant features. We conduct extensive experiments on a large claims dataset and show that the blended method outperforms the standard machine learning approaches.
Phenotypical Ontology Driven Framework for Multi-Task Learning
Sep 04, 2020
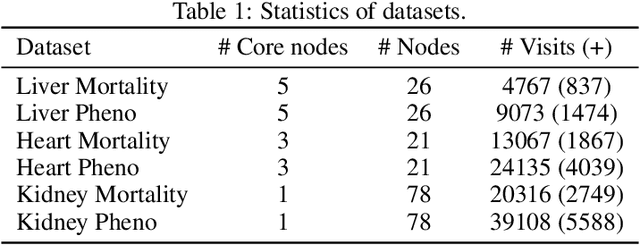
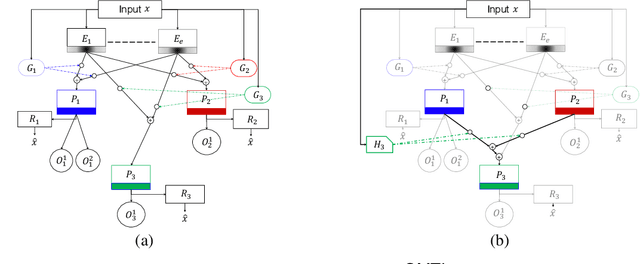
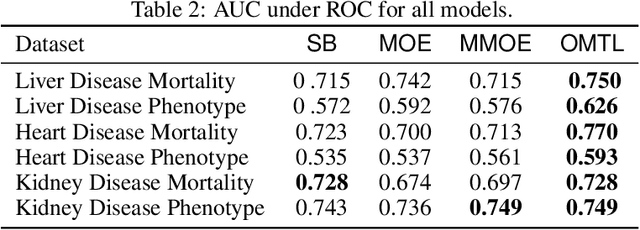
Despite the large number of patients in Electronic Health Records (EHRs), the subset of usable data for modeling outcomes of specific phenotypes are often imbalanced and of modest size. This can be attributed to the uneven coverage of medical concepts in EHRs. In this paper, we propose OMTL, an Ontology-driven Multi-Task Learning framework, that is designed to overcome such data limitations. The key contribution of our work is the effective use of knowledge from a predefined well-established medical relationship graph (ontology) to construct a novel deep learning network architecture that mirrors this ontology. It can effectively leverage knowledge from a well-established medical relationship graph (ontology) by constructing a deep learning network architecture that mirrors this graph. This enables common representations to be shared across related phenotypes, and was found to improve the learning performance. The proposed OMTL naturally allows for multitask learning of different phenotypes on distinct predictive tasks. These phenotypes are tied together by their semantic distance according to the external medical ontology. Using the publicly available MIMIC-III database, we evaluate OMTL and demonstrate its efficacy on several real patient outcome predictions over state-of-the-art multi-task learning schemes.
A Canonical Architecture For Predictive Analytics on Longitudinal Patient Records
Jul 24, 2020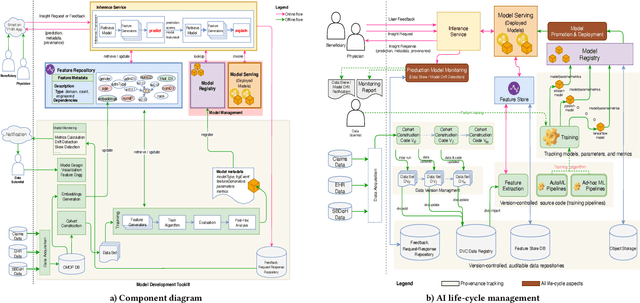
Many institutions within the healthcare ecosystem are making significant investments in AI technologies to optimize their business operations at lower cost with improved patient outcomes. Despite the hype with AI, the full realization of this potential is seriously hindered by several systemic problems, including data privacy, security, bias, fairness, and explainability. In this paper, we propose a novel canonical architecture for the development of AI models in healthcare that addresses these challenges. This system enables the creation and management of AI predictive models throughout all the phases of their life cycle, including data ingestion, model building, and model promotion in production environments. This paper describes this architecture in detail, along with a qualitative evaluation of our experience of using it on real world problems.
ODVICE: An Ontology-Driven Visual Analytic Tool for Interactive Cohort Extraction
May 13, 2020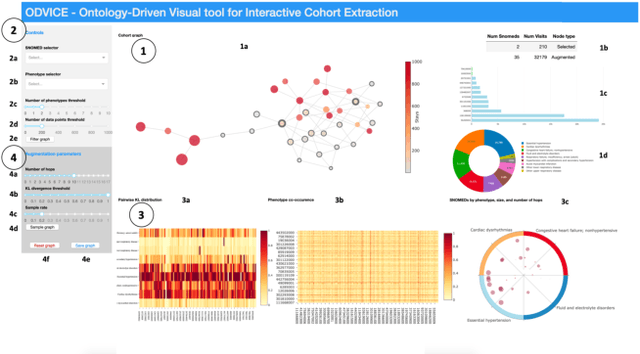

Increased availability of electronic health records (EHR) has enabled researchers to study various medical questions. Cohort selection for the hypothesis under investigation is one of the main consideration for EHR analysis. For uncommon diseases, cohorts extracted from EHRs contain very limited number of records - hampering the robustness of any analysis. Data augmentation methods have been successfully applied in other domains to address this issue mainly using simulated records. In this paper, we present ODVICE, a data augmentation framework that leverages the medical concept ontology to systematically augment records using a novel ontologically guided Monte-Carlo graph spanning algorithm. The tool allows end users to specify a small set of interactive controls to control the augmentation process. We analyze the importance of ODVICE by conducting studies on MIMIC-III dataset for two learning tasks. Our results demonstrate the predictive performance of ODVICE augmented cohorts, showing ~30% improvement in area under the curve (AUC) over the non-augmented dataset and other data augmentation strategies.