 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Latent Diffusion Language Model
May 07, 2026Large language models have achieved remarkable success under the autoregressive paradigm, yet high-quality text generation need not be tied to a fixed left-to-right order. Existing alternatives still struggle to jointly achieve generation efficiency, scalable representation learning, and effective global semantic modeling. We propose Cola DLM, a hierarchical latent diffusion language model that frames text generation through hierarchical information decomposition. Cola DLM first learns a stable text-to-latent mapping with a Text VAE, then models a global semantic prior in continuous latent space with a block-causal DiT, and finally generates text through conditional decoding. From a unified Markov-path perspective, its diffusion process performs latent prior transport rather than token-level observation recovery, thereby separating global semantic organization from local textual realization. This design yields a more flexible non-autoregressive inductive bias, supports semantic compression and prior fitting in continuous space, and naturally extends to other continuous modalities. Through experiments spanning 4 research questions, 8 benchmarks, strictly matched ~2B-parameter autoregressive and LLaDA baselines, and scaling curves up to about 2000 EFLOPs, we identify an effective overall configuration of Cola DLM and verify its strong scaling behavior for text generation. Taken together, the results establish hierarchical continuous latent prior modeling as a principled alternative to strictly token-level language modeling, where generation quality and scaling behavior may better reflect model capability than likelihood, while also suggesting a concrete path toward unified modeling across discrete text and continuous modalities.
LLaDA-Rec: Discrete Diffusion for Parallel Semantic ID Generation in Generative Recommendation
Nov 09, 2025Generative recommendation represents each item as a semantic ID, i.e., a sequence of discrete tokens, and generates the next item through autoregressive decoding. While effective, existing autoregressive models face two intrinsic limitations: (1) unidirectional constraints, where causal attention restricts each token to attend only to its predecessors, hindering global semantic modeling; and (2) error accumulation, where the fixed left-to-right generation order causes prediction errors in early tokens to propagate to the predictions of subsequent token. To address these issues, we propose LLaDA-Rec, a discrete diffusion framework that reformulates recommendation as parallel semantic ID generation. By combining bidirectional attention with the adaptive generation order, the approach models inter-item and intra-item dependencies more effectively and alleviates error accumulation. Specifically, our approach comprises three key designs: (1) a parallel tokenization scheme that produces semantic IDs for bidirectional modeling, addressing the mismatch between residual quantization and bidirectional architectures; (2) two masking mechanisms at the user-history and next-item levels to capture both inter-item sequential dependencies and intra-item semantic relationships; and (3) an adapted beam search strategy for adaptive-order discrete diffusion decoding, resolving the incompatibility of standard beam search with diffusion-based generation. Experiments on three real-world datasets show that LLaDA-Rec consistently outperforms both ID-based and state-of-the-art generative recommenders, establishing discrete diffusion as a new paradigm for generative recommendation.
Masked Diffusion Models as Energy Minimization
Sep 17, 2025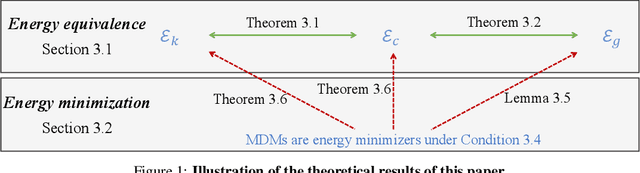
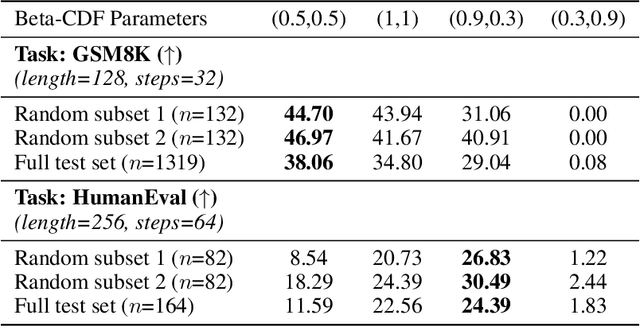
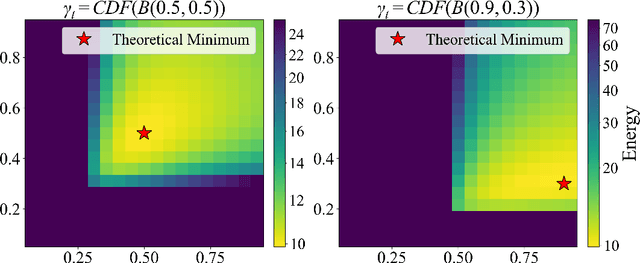
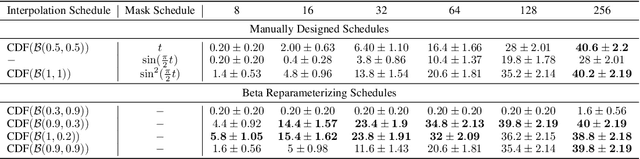
We present a systematic theoretical framework that interprets masked diffusion models (MDMs) as solutions to energy minimization problems in discrete optimal transport. Specifically, we prove that three distinct energy formulations--kinetic, conditional kinetic, and geodesic energy--are mathematically equivalent under the structure of MDMs, and that MDMs minimize all three when the mask schedule satisfies a closed-form optimality condition. This unification not only clarifies the theoretical foundations of MDMs, but also motivates practical improvements in sampling. By parameterizing interpolation schedules via Beta distributions, we reduce the schedule design space to a tractable 2D search, enabling efficient post-training tuning without model modification. Experiments on synthetic and real-world benchmarks demonstrate that our energy-inspired schedules outperform hand-crafted baselines, particularly in low-step sampling settings.
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
May 25, 2025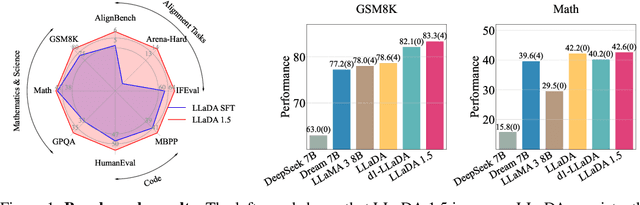
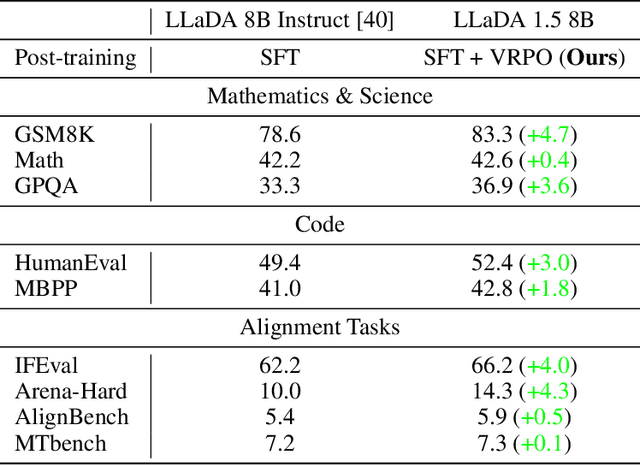
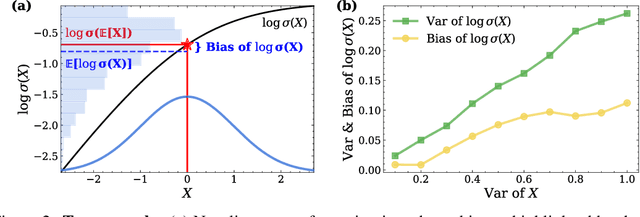
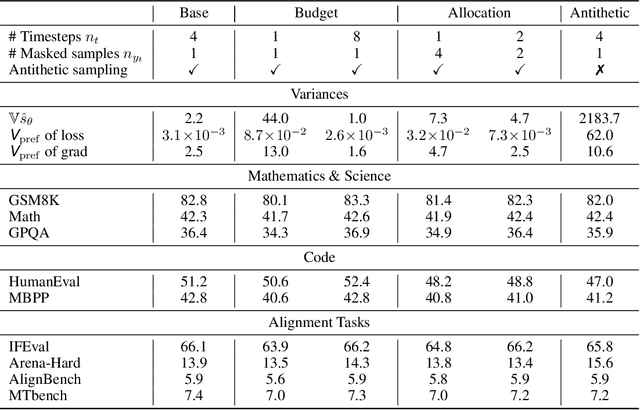
While Masked Diffusion Models (MDMs), such as LLaDA, present a promising paradigm for language modeling, there has been relatively little effort in aligning these models with human preferences via reinforcement learning. The challenge primarily arises from the high variance in Evidence Lower Bound (ELBO)-based likelihood estimates required for preference optimization. To address this issue, we propose Variance-Reduced Preference Optimization (VRPO), a framework that formally analyzes the variance of ELBO estimators and derives bounds on both the bias and variance of preference optimization gradients. Building on this theoretical foundation, we introduce unbiased variance reduction strategies, including optimal Monte Carlo budget allocation and antithetic sampling, that significantly improve the performance of MDM alignment. We demonstrate the effectiveness of VRPO by applying it to LLaDA, and the resulting model, LLaDA 1.5, outperforms its SFT-only predecessor consistently and significantly across mathematical (GSM8K +4.7), code (HumanEval +3.0, MBPP +1.8), and alignment benchmarks (IFEval +4.0, Arena-Hard +4.3). Furthermore, LLaDA 1.5 demonstrates a highly competitive mathematical performance compared to strong language MDMs and ARMs. Project page: https://ml-gsai.github.io/LLaDA-1.5-Demo/.
LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning
May 22, 2025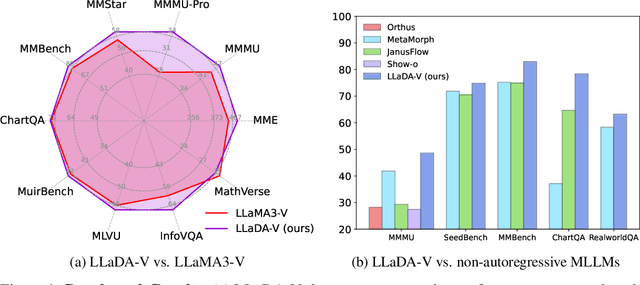
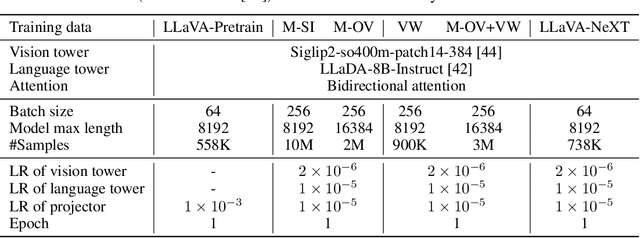
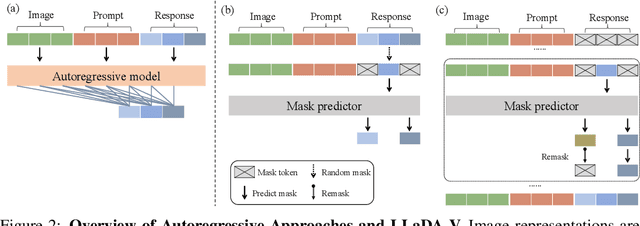
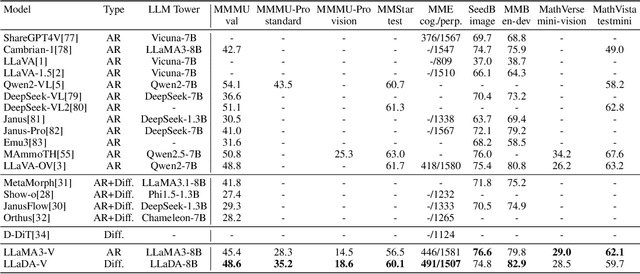
In this work, we introduce LLaDA-V, a purely diffusion-based Multimodal Large Language Model (MLLM) that integrates visual instruction tuning with masked diffusion models, representing a departure from the autoregressive paradigms dominant in current multimodal approaches. Built upon LLaDA, a representative large language diffusion model, LLaDA-V incorporates a vision encoder and MLP connector that projects visual features into the language embedding space, enabling effective multimodal alignment. Our empirical investigation reveals several intriguing results: First, LLaDA-V demonstrates promising multimodal performance despite its language model being weaker on purely textual tasks than counterparts like LLaMA3-8B and Qwen2-7B. When trained on the same instruction data, LLaDA-V is highly competitive to LLaMA3-V across multimodal tasks with better data scalability. It also narrows the performance gap to Qwen2-VL, suggesting the effectiveness of its architecture for multimodal tasks. Second, LLaDA-V achieves state-of-the-art performance in multimodal understanding compared to existing hybrid autoregressive-diffusion and purely diffusion-based MLLMs. Our findings suggest that large language diffusion models show promise in multimodal contexts and warrant further investigation in future research. Project page and codes: https://ml-gsai.github.io/LLaDA-V-demo/.
Real-time Identity Defenses against Malicious Personalization of Diffusion Models
Dec 13, 2024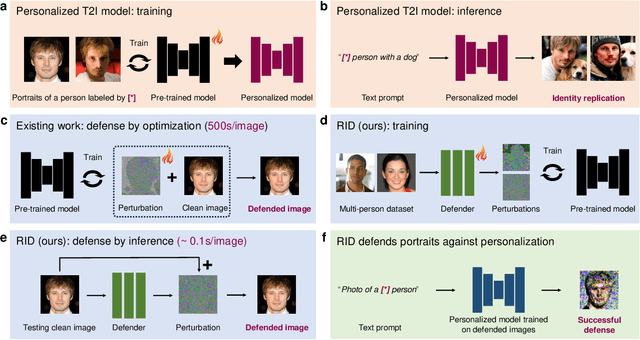
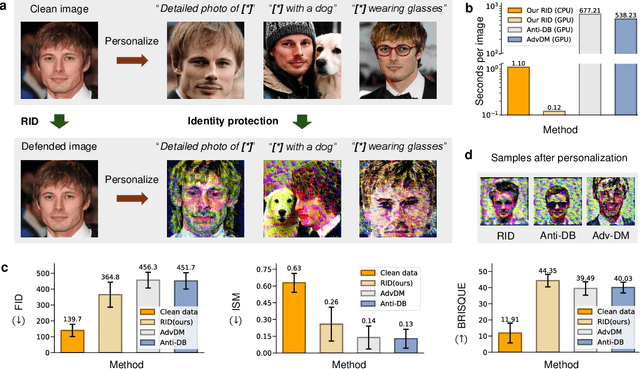
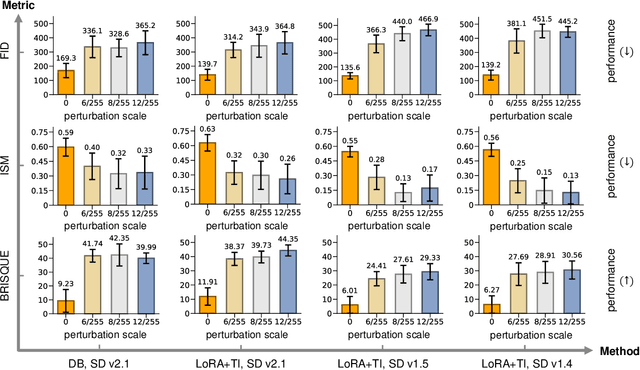
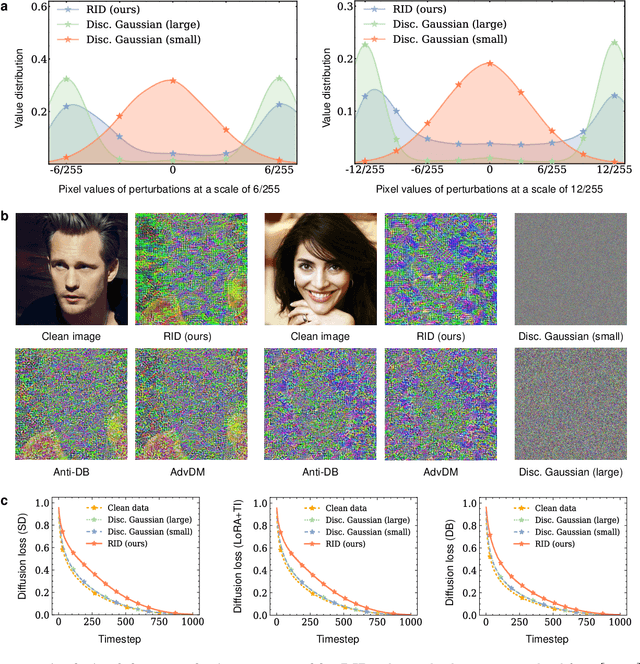
Personalized diffusion models, capable of synthesizing highly realistic images based on a few reference portraits, pose substantial social, ethical, and legal risks by enabling identity replication. Existing defense mechanisms rely on computationally intensive adversarial perturbations tailored to individual images, rendering them impractical for real-world deployment. This study introduces Real-time Identity Defender (RID), a neural network designed to generate adversarial perturbations through a single forward pass, bypassing the need for image-specific optimization. RID achieves unprecedented efficiency, with defense times as low as 0.12 seconds on a single GPU (4,400 times faster than leading methods) and 1.1 seconds per image on a standard Intel i9 CPU, making it suitable for edge devices such as smartphones. Despite its efficiency, RID matches state-of-the-art performance across visual and quantitative benchmarks, effectively mitigating identity replication risks. Our analysis reveals that RID's perturbations mimic the efficacy of traditional defenses while exhibiting properties distinct from natural noise, such as Gaussian perturbations. To enhance robustness, we extend RID into an ensemble framework that integrates multiple pre-trained text-to-image diffusion models, ensuring resilience against black-box attacks and post-processing techniques, including JPEG compression and diffusion-based purification.
Scaling up Masked Diffusion Models on Text
Oct 24, 2024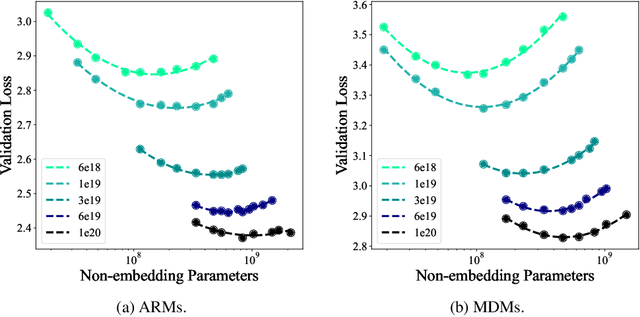

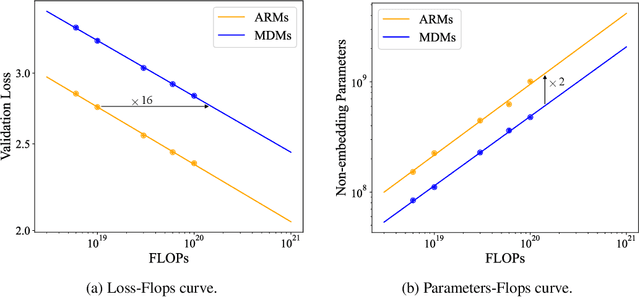

Masked diffusion models (MDMs) have shown promise in language modeling, yet their scalability and effectiveness in core language tasks, such as text generation and language understanding, remain underexplored. This paper establishes the first scaling law for MDMs, demonstrating a scaling rate comparable to autoregressive models (ARMs) and a relatively small compute gap. Motivated by their scalability, we train a family of MDMs with up to 1.1 billion (B) parameters to systematically evaluate their performance against ARMs of comparable or larger sizes. Fully leveraging the probabilistic formulation of MDMs, we propose a simple yet effective \emph{unsupervised classifier-free guidance} that effectively exploits large-scale unpaired data, boosting performance for conditional inference. In language understanding, a 1.1B MDM shows competitive results, outperforming the larger 1.5B GPT-2 model on four out of eight zero-shot benchmarks. In text generation, MDMs provide a flexible trade-off compared to ARMs utilizing KV-cache: MDMs match the performance of ARMs while being 1.4 times faster, or achieve higher quality than ARMs at a higher computational cost. Moreover, MDMs address challenging tasks for ARMs by effectively handling bidirectional reasoning and adapting to temporal shifts in data. Notably, a 1.1B MDM breaks the \emph{reverse curse} encountered by much larger ARMs with significantly more data and computation, such as Llama-2 (13B) and GPT-3 (175B). Our code is available at \url{https://github.com/ML-GSAI/SMDM}.
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
Jun 06, 2024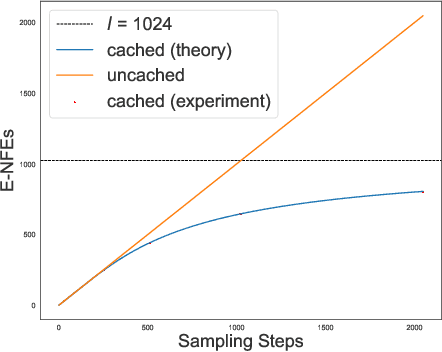
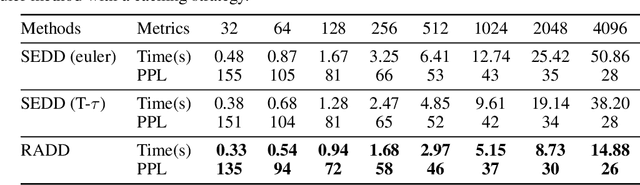
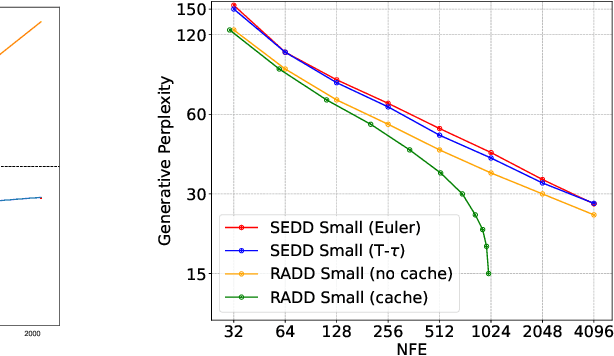
Discrete diffusion models with absorbing processes have shown promise in language modeling. The key quantities to be estimated are the ratios between the marginal probabilities of two transitive states at all timesteps, called the concrete score. In this paper, we reveal that the concrete score in absorbing diffusion can be expressed as conditional probabilities of clean data, multiplied by a time-dependent scalar in an analytic form. Motivated by the finding, we propose reparameterized absorbing discrete diffusion (RADD), a dedicated diffusion model that characterizes the time-independent conditional probabilities. Besides its simplicity, RADD can reduce the number of function evaluations (NFEs) by caching the output of the time-independent network when the noisy sample remains unchanged in a sampling interval. Empirically, RADD is up to 3.5 times faster while consistently achieving a better performance than the strongest baseline. Built upon the new factorization of the concrete score, we further prove a surprising result that the exact likelihood of absorbing diffusion can be rewritten to a simple form (named denoising cross-entropy) and then estimated efficiently by the Monte Carlo method. The resulting approach also applies to the original parameterization of the concrete score. It significantly advances the state-of-the-art discrete diffusion on 5 zero-shot language modeling benchmarks (measured by perplexity) at the GPT-2 scale.
Unifying Bayesian Flow Networks and Diffusion Models through Stochastic Differential Equations
Apr 24, 2024
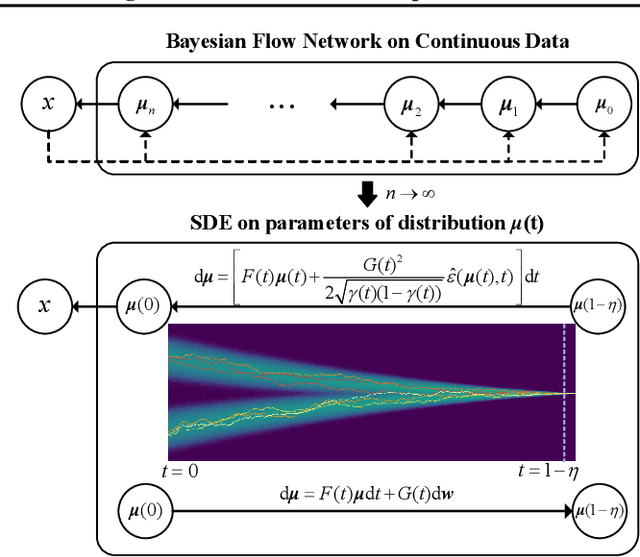
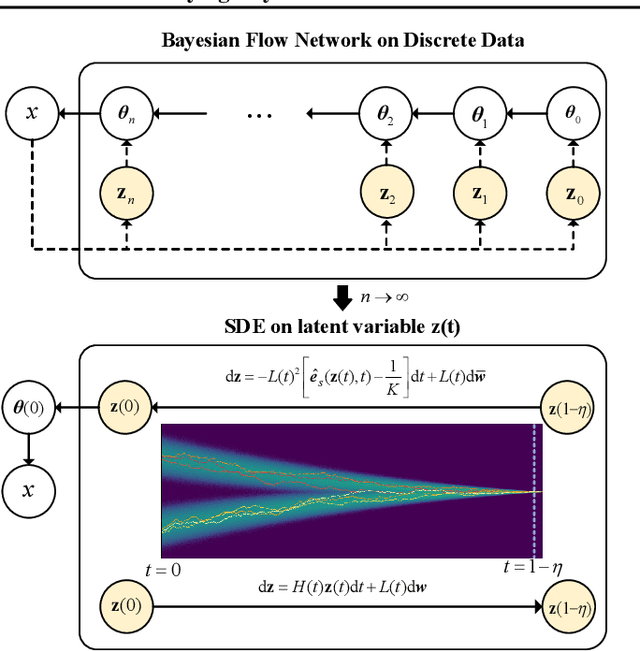

Bayesian flow networks (BFNs) iteratively refine the parameters, instead of the samples in diffusion models (DMs), of distributions at various noise levels through Bayesian inference. Owing to its differentiable nature, BFNs are promising in modeling both continuous and discrete data, while simultaneously maintaining fast sampling capabilities. This paper aims to understand and enhance BFNs by connecting them with DMs through stochastic differential equations (SDEs). We identify the linear SDEs corresponding to the noise-addition processes in BFNs, demonstrate that BFN's regression losses are aligned with denoise score matching, and validate the sampler in BFN as a first-order solver for the respective reverse-time SDE. Based on these findings and existing recipes of fast sampling in DMs, we propose specialized solvers for BFNs that markedly surpass the original BFN sampler in terms of sample quality with a limited number of function evaluations (e.g., 10) on both image and text datasets. Notably, our best sampler achieves an increase in speed of 5~20 times for free. Our code is available at https://github.com/ML-GSAI/BFN-Solver.
The Blessing of Randomness: SDE Beats ODE in General Diffusion-based Image Editing
Nov 02, 2023
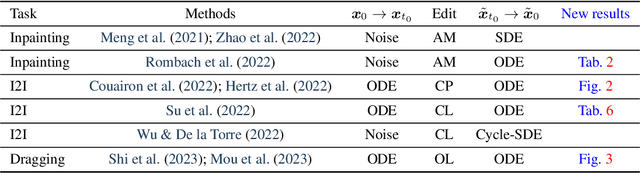

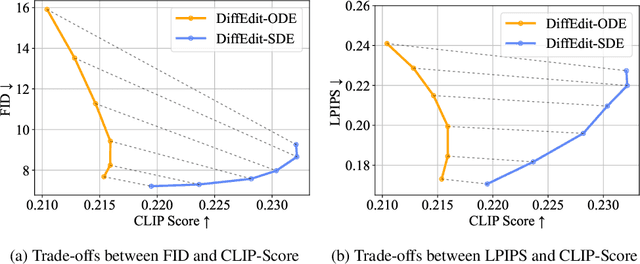
We present a unified probabilistic formulation for diffusion-based image editing, where a latent variable is edited in a task-specific manner and generally deviates from the corresponding marginal distribution induced by the original stochastic or ordinary differential equation (SDE or ODE). Instead, it defines a corresponding SDE or ODE for editing. In the formulation, we prove that the Kullback-Leibler divergence between the marginal distributions of the two SDEs gradually decreases while that for the ODEs remains as the time approaches zero, which shows the promise of SDE in image editing. Inspired by it, we provide the SDE counterparts for widely used ODE baselines in various tasks including inpainting and image-to-image translation, where SDE shows a consistent and substantial improvement. Moreover, we propose SDE-Drag -- a simple yet effective method built upon the SDE formulation for point-based content dragging. We build a challenging benchmark (termed DragBench) with open-set natural, art, and AI-generated images for evaluation. A user study on DragBench indicates that SDE-Drag significantly outperforms our ODE baseline, existing diffusion-based methods, and the renowned DragGAN. Our results demonstrate the superiority and versatility of SDE in image editing and push the boundary of diffusion-based editing methods.