 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreBench: Human-Aligned Creativity Evaluation from Idea to Process to Product
Nov 17, 2025Human-defined creativity is highly abstract, posing a challenge for multimodal large language models (MLLMs) to comprehend and assess creativity that aligns with human judgments. The absence of an existing benchmark further exacerbates this dilemma. To this end, we propose CreBench, which consists of two key components: 1) an evaluation benchmark covering the multiple dimensions from creative idea to process to products; 2) CreMIT (Creativity Multimodal Instruction Tuning dataset), a multimodal creativity evaluation dataset, consisting of 2.2K diverse-sourced multimodal data, 79.2K human feedbacks and 4.7M multi-typed instructions. Specifically, to ensure MLLMs can handle diverse creativity-related queries, we prompt GPT to refine these human feedbacks to activate stronger creativity assessment capabilities. CreBench serves as a foundation for building MLLMs that understand human-aligned creativity. Based on the CreBench, we fine-tune open-source general MLLMs, resulting in CreExpert, a multimodal creativity evaluation expert model. Extensive experiments demonstrate that the proposed CreExpert models achieve significantly better alignment with human creativity evaluation compared to state-of-the-art MLLMs, including the most advanced GPT-4V and Gemini-Pro-Vision.
Enhancing Technical Documents Retrieval for RAG
Sep 04, 2025In this paper, we introduce Technical-Embeddings, a novel framework designed to optimize semantic retrieval in technical documentation, with applications in both hardware and software development. Our approach addresses the challenges of understanding and retrieving complex technical content by leveraging the capabilities of Large Language Models (LLMs). First, we enhance user queries by generating expanded representations that better capture user intent and improve dataset diversity, thereby enriching the fine-tuning process for embedding models. Second, we apply summary extraction techniques to encode essential contextual information, refining the representation of technical documents. To further enhance retrieval performance, we fine-tune a bi-encoder BERT model using soft prompting, incorporating separate learning parameters for queries and document context to capture fine-grained semantic nuances. We evaluate our approach on two public datasets, RAG-EDA and Rust-Docs-QA, demonstrating that Technical-Embeddings significantly outperforms baseline models in both precision and recall. Our findings highlight the effectiveness of integrating query expansion and contextual summarization to enhance information access and comprehension in technical domains. This work advances the state of Retrieval-Augmented Generation (RAG) systems, offering new avenues for efficient and accurate technical document retrieval in engineering and product development workflows.
A Survey on Latent Reasoning
Jul 08, 2025



Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model's expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model's continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
Residual Attention Single-Head Vision Transformer Network for Rolling Bearing Fault Diagnosis in Noisy Environments
Nov 27, 2024



Rolling bearings play a crucial role in industrial machinery, directly influencing equipment performance, durability, and safety. However, harsh operating conditions, such as high speeds and temperatures, often lead to bearing malfunctions, resulting in downtime, economic losses, and safety hazards. This paper proposes the Residual Attention Single-Head Vision Transformer Network (RA-SHViT-Net) for fault diagnosis in rolling bearings. Vibration signals are transformed from the time to frequency domain using the Fast Fourier Transform (FFT) before being processed by RA-SHViT-Net. The model employs the Single-Head Vision Transformer (SHViT) to capture local and global features, balancing computational efficiency and predictive accuracy. To enhance feature extraction, the Adaptive Hybrid Attention Block (AHAB) integrates channel and spatial attention mechanisms. The network architecture includes Depthwise Convolution, Single-Head Self-Attention, Residual Feed-Forward Networks (Res-FFN), and AHAB modules, ensuring robust feature representation and mitigating gradient vanishing issues. Evaluation on the Case Western Reserve University and Paderborn University datasets demonstrates the RA-SHViT-Net's superior accuracy and robustness in complex, noisy environments. Ablation studies further validate the contributions of individual components, establishing RA-SHViT-Net as an effective tool for early fault detection and classification, promoting efficient maintenance strategies in industrial settings. Keywords: rolling bearings, fault diagnosis, Vision Transformer, attention mechanism, noisy environments, Fast Fourier Transform (FFT)
Preserving Full Degradation Details for Blind Image Super-Resolution
Jul 02, 2024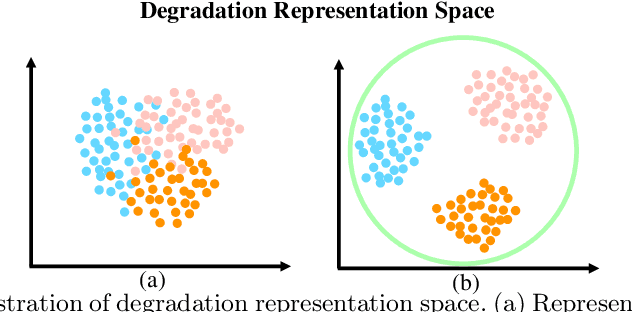
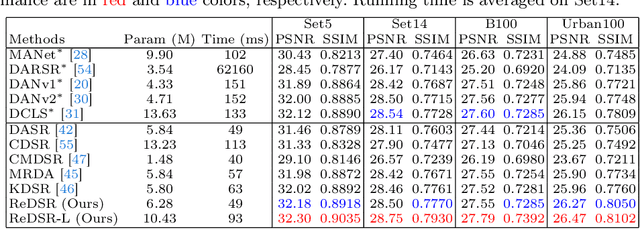
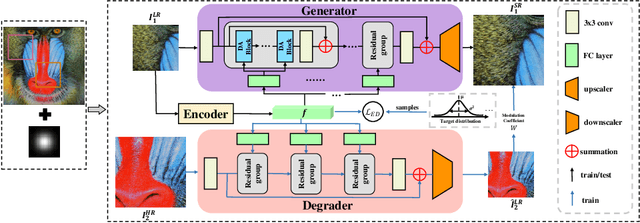
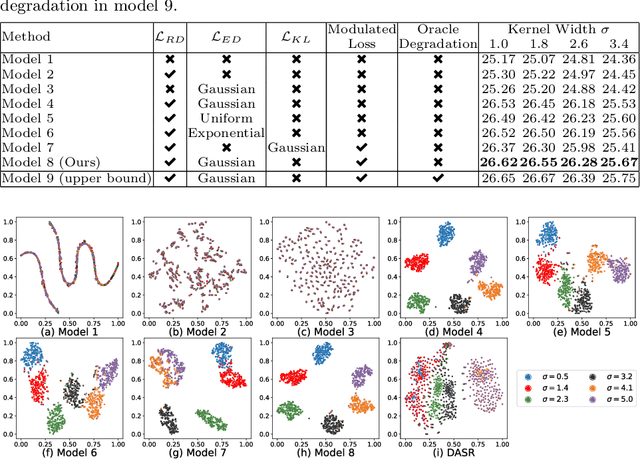
The performance of image super-resolution relies heavily on the accuracy of degradation information, especially under blind settings. Due to absence of true degradation models in real-world scenarios, previous methods learn distinct representations by distinguishing different degradations in a batch. However, the most significant degradation differences may provide shortcuts for the learning of representations such that subtle difference may be discarded. In this paper, we propose an alternative to learn degradation representations through reproducing degraded low-resolution (LR) images. By guiding the degrader to reconstruct input LR images, full degradation information can be encoded into the representations. In addition, we develop an energy distance loss to facilitate the learning of the degradation representations by introducing a bounded constraint. Experiments show that our representations can extract accurate and highly robust degradation information. Moreover, evaluations on both synthetic and real images demonstrate that our ReDSR achieves state-of-the-art performance for the blind SR tasks.
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
Jun 06, 2024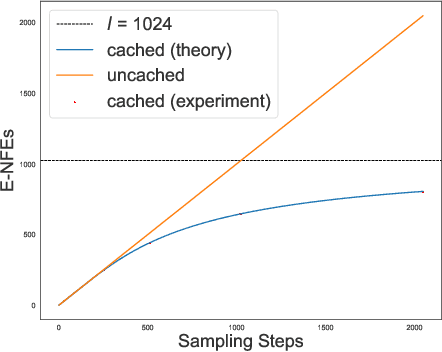
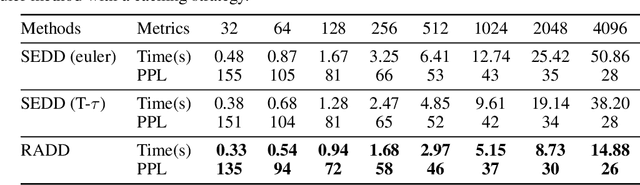
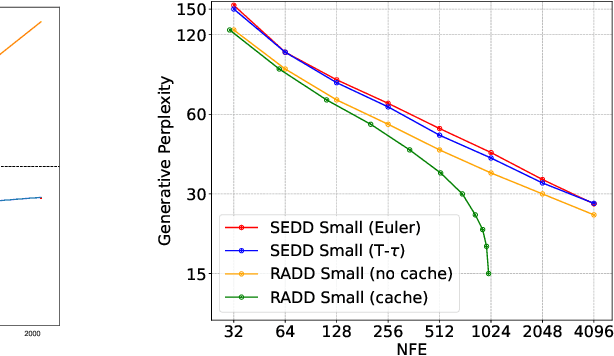
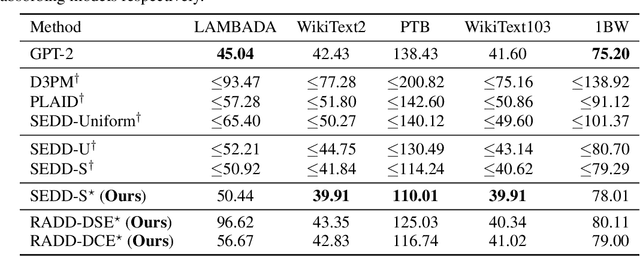
Discrete diffusion models with absorbing processes have shown promise in language modeling. The key quantities to be estimated are the ratios between the marginal probabilities of two transitive states at all timesteps, called the concrete score. In this paper, we reveal that the concrete score in absorbing diffusion can be expressed as conditional probabilities of clean data, multiplied by a time-dependent scalar in an analytic form. Motivated by the finding, we propose reparameterized absorbing discrete diffusion (RADD), a dedicated diffusion model that characterizes the time-independent conditional probabilities. Besides its simplicity, RADD can reduce the number of function evaluations (NFEs) by caching the output of the time-independent network when the noisy sample remains unchanged in a sampling interval. Empirically, RADD is up to 3.5 times faster while consistently achieving a better performance than the strongest baseline. Built upon the new factorization of the concrete score, we further prove a surprising result that the exact likelihood of absorbing diffusion can be rewritten to a simple form (named denoising cross-entropy) and then estimated efficiently by the Monte Carlo method. The resulting approach also applies to the original parameterization of the concrete score. It significantly advances the state-of-the-art discrete diffusion on 5 zero-shot language modeling benchmarks (measured by perplexity) at the GPT-2 scale.
Unifying Bayesian Flow Networks and Diffusion Models through Stochastic Differential Equations
Apr 24, 2024
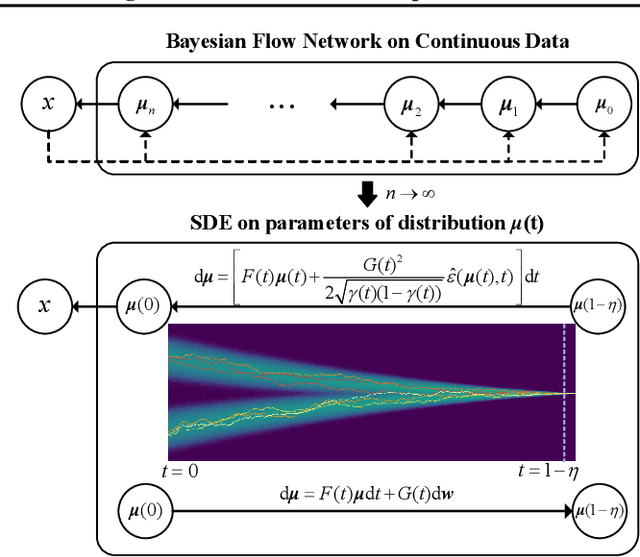
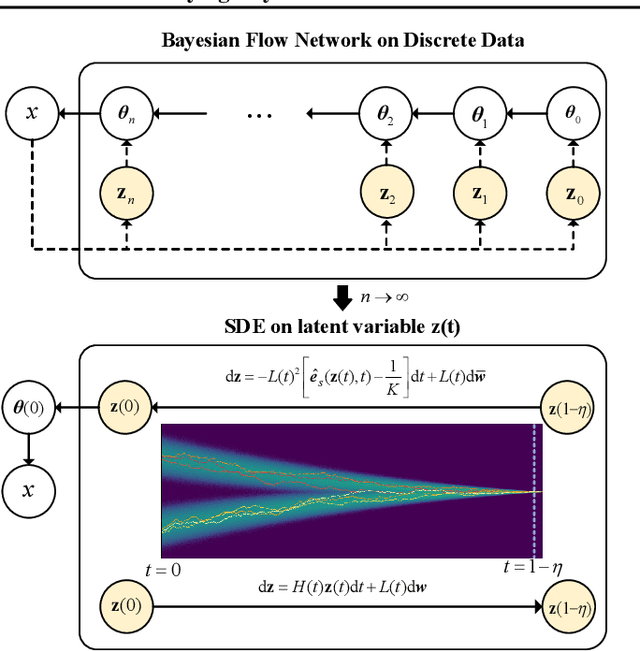

Bayesian flow networks (BFNs) iteratively refine the parameters, instead of the samples in diffusion models (DMs), of distributions at various noise levels through Bayesian inference. Owing to its differentiable nature, BFNs are promising in modeling both continuous and discrete data, while simultaneously maintaining fast sampling capabilities. This paper aims to understand and enhance BFNs by connecting them with DMs through stochastic differential equations (SDEs). We identify the linear SDEs corresponding to the noise-addition processes in BFNs, demonstrate that BFN's regression losses are aligned with denoise score matching, and validate the sampler in BFN as a first-order solver for the respective reverse-time SDE. Based on these findings and existing recipes of fast sampling in DMs, we propose specialized solvers for BFNs that markedly surpass the original BFN sampler in terms of sample quality with a limited number of function evaluations (e.g., 10) on both image and text datasets. Notably, our best sampler achieves an increase in speed of 5~20 times for free. Our code is available at https://github.com/ML-GSAI/BFN-Solver.
SCALE: Self-Correcting Visual Navigation for Mobile Robots via Anti-Novelty Estimation
Apr 16, 2024Although visual navigation has been extensively studied using deep reinforcement learning, online learning for real-world robots remains a challenging task. Recent work directly learned from offline dataset to achieve broader generalization in the real-world tasks, which, however, faces the out-of-distribution (OOD) issue and potential robot localization failures in a given map for unseen observation. This significantly drops the success rates and even induces collision. In this paper, we present a self-correcting visual navigation method, SCALE, that can autonomously prevent the robot from the OOD situations without human intervention. Specifically, we develop an image-goal conditioned offline reinforcement learning method based on implicit Q-learning (IQL). When facing OOD observation, our novel localization recovery method generates the potential future trajectories by learning from the navigation affordance, and estimates the future novelty via random network distillation (RND). A tailored cost function searches for the candidates with the least novelty that can lead the robot to the familiar places. We collect offline data and conduct evaluation experiments in three real-world urban scenarios. Experiment results show that SCALE outperforms the previous state-of-the-art methods for open-world navigation with a unique capability of localization recovery, significantly reducing the need for human intervention. Code is available at https://github.com/KubeEdge4Robotics/ScaleNav.
One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale
Mar 12, 2023

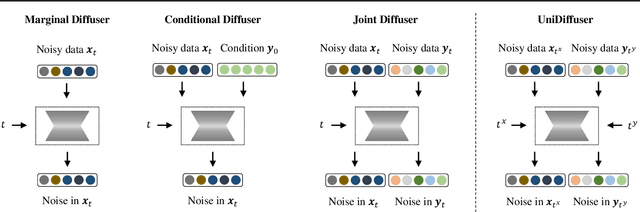

This paper proposes a unified diffusion framework (dubbed UniDiffuser) to fit all distributions relevant to a set of multi-modal data in one model. Our key insight is -- learning diffusion models for marginal, conditional, and joint distributions can be unified as predicting the noise in the perturbed data, where the perturbation levels (i.e. timesteps) can be different for different modalities. Inspired by the unified view, UniDiffuser learns all distributions simultaneously with a minimal modification to the original diffusion model -- perturbs data in all modalities instead of a single modality, inputs individual timesteps in different modalities, and predicts the noise of all modalities instead of a single modality. UniDiffuser is parameterized by a transformer for diffusion models to handle input types of different modalities. Implemented on large-scale paired image-text data, UniDiffuser is able to perform image, text, text-to-image, image-to-text, and image-text pair generation by setting proper timesteps without additional overhead. In particular, UniDiffuser is able to produce perceptually realistic samples in all tasks and its quantitative results (e.g., the FID and CLIP score) are not only superior to existing general-purpose models but also comparable to the bespoken models (e.g., Stable Diffusion and DALL-E 2) in representative tasks (e.g., text-to-image generation).
Design and Verification of a Novel Triphibian Platform
Nov 30, 2022

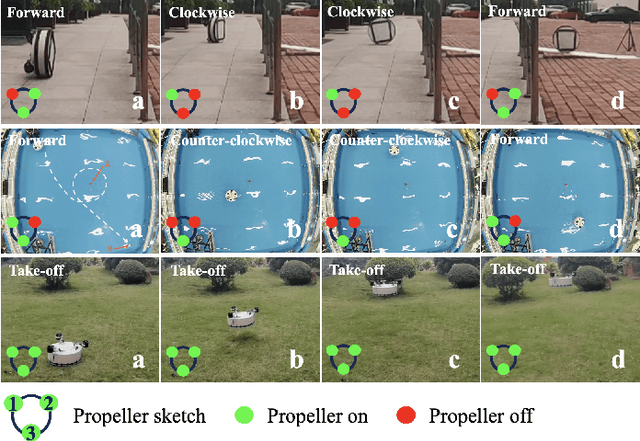

Multi-modal robots expand their operations from one working media to another, land to air for example. The majorities multi-modal robots mainly refer to platforms that operate in two different media. However, for all-terrain tasks, there is seldom research to date in the literature. In this paper, we proposed a triphibian robotic platform aiming at solving the challenges of different propulsion systems and immensely varied working media. In our design, three ducted fans are adopted to unify the propulsion system and provide the robot with driving forces to perform all-terrain operations. A morphable mechanism is designed to enable the transition between different motion modes, and specifically, a cylindrical body is implemented as the rolling mechanism in land mode. Detailed design principles of different mechanisms and the transition between various locomotion modes are analyzed in detail. Finally, a triphibian robot prototype is fabricated and tested in various working media with mono-modal and multi-modal functionalities. Experiments have verified our platform, and the results show promising adaptions for future exploration tasks in different working scenarios.