 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Technical Documents Retrieval for RAG
Sep 04, 2025In this paper, we introduce Technical-Embeddings, a novel framework designed to optimize semantic retrieval in technical documentation, with applications in both hardware and software development. Our approach addresses the challenges of understanding and retrieving complex technical content by leveraging the capabilities of Large Language Models (LLMs). First, we enhance user queries by generating expanded representations that better capture user intent and improve dataset diversity, thereby enriching the fine-tuning process for embedding models. Second, we apply summary extraction techniques to encode essential contextual information, refining the representation of technical documents. To further enhance retrieval performance, we fine-tune a bi-encoder BERT model using soft prompting, incorporating separate learning parameters for queries and document context to capture fine-grained semantic nuances. We evaluate our approach on two public datasets, RAG-EDA and Rust-Docs-QA, demonstrating that Technical-Embeddings significantly outperforms baseline models in both precision and recall. Our findings highlight the effectiveness of integrating query expansion and contextual summarization to enhance information access and comprehension in technical domains. This work advances the state of Retrieval-Augmented Generation (RAG) systems, offering new avenues for efficient and accurate technical document retrieval in engineering and product development workflows.
Automatic Prompt Generation and Grounding Object Detection for Zero-Shot Image Anomaly Detection
Nov 28, 2024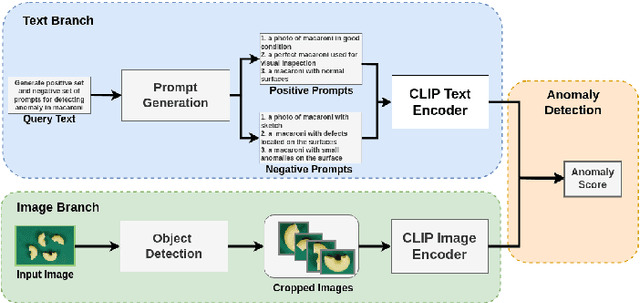

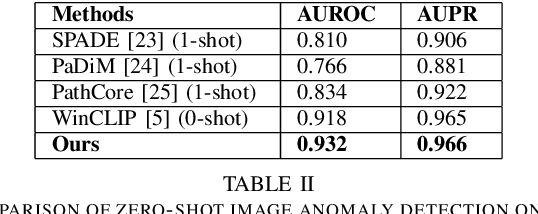
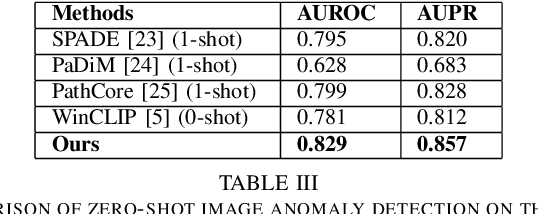
Identifying defects and anomalies in industrial products is a critical quality control task. Traditional manual inspection methods are slow, subjective, and error-prone. In this work, we propose a novel zero-shot training-free approach for automated industrial image anomaly detection using a multimodal machine learning pipeline, consisting of three foundation models. Our method first uses a large language model, i.e., GPT-3. generate text prompts describing the expected appearances of normal and abnormal products. We then use a grounding object detection model, called Grounding DINO, to locate the product in the image. Finally, we compare the cropped product image patches to the generated prompts using a zero-shot image-text matching model, called CLIP, to identify any anomalies. Our experiments on two datasets of industrial product images, namely MVTec-AD and VisA, demonstrate the effectiveness of this method, achieving high accuracy in detecting various types of defects and anomalies without the need for model training. Our proposed model enables efficient, scalable, and objective quality control in industrial manufacturing settings.
Residual Attention Single-Head Vision Transformer Network for Rolling Bearing Fault Diagnosis in Noisy Environments
Nov 27, 2024



Rolling bearings play a crucial role in industrial machinery, directly influencing equipment performance, durability, and safety. However, harsh operating conditions, such as high speeds and temperatures, often lead to bearing malfunctions, resulting in downtime, economic losses, and safety hazards. This paper proposes the Residual Attention Single-Head Vision Transformer Network (RA-SHViT-Net) for fault diagnosis in rolling bearings. Vibration signals are transformed from the time to frequency domain using the Fast Fourier Transform (FFT) before being processed by RA-SHViT-Net. The model employs the Single-Head Vision Transformer (SHViT) to capture local and global features, balancing computational efficiency and predictive accuracy. To enhance feature extraction, the Adaptive Hybrid Attention Block (AHAB) integrates channel and spatial attention mechanisms. The network architecture includes Depthwise Convolution, Single-Head Self-Attention, Residual Feed-Forward Networks (Res-FFN), and AHAB modules, ensuring robust feature representation and mitigating gradient vanishing issues. Evaluation on the Case Western Reserve University and Paderborn University datasets demonstrates the RA-SHViT-Net's superior accuracy and robustness in complex, noisy environments. Ablation studies further validate the contributions of individual components, establishing RA-SHViT-Net as an effective tool for early fault detection and classification, promoting efficient maintenance strategies in industrial settings. Keywords: rolling bearings, fault diagnosis, Vision Transformer, attention mechanism, noisy environments, Fast Fourier Transform (FFT)
HAAT: Hybrid Attention Aggregation Transformer for Image Super-Resolution
Nov 27, 2024In the research area of image super-resolution, Swin-transformer-based models are favored for their global spatial modeling and shifting window attention mechanism. However, existing methods often limit self-attention to non overlapping windows to cut costs and ignore the useful information that exists across channels. To address this issue, this paper introduces a novel model, the Hybrid Attention Aggregation Transformer (HAAT), designed to better leverage feature information. HAAT is constructed by integrating Swin-Dense-Residual-Connected Blocks (SDRCB) with Hybrid Grid Attention Blocks (HGAB). SDRCB expands the receptive field while maintaining a streamlined architecture, resulting in enhanced performance. HGAB incorporates channel attention, sparse attention, and window attention to improve nonlocal feature fusion and achieve more visually compelling results. Experimental evaluations demonstrate that HAAT surpasses state-of-the-art methods on benchmark datasets. Keywords: Image super-resolution, Computer vision, Attention mechanism, Transformer
An End-to-End Two-Stream Network Based on RGB Flow and Representation Flow for Human Action Recognition
Nov 27, 2024



With the rapid advancements in deep learning, computer vision tasks have seen significant improvements, making two-stream neural networks a popular focus for video based action recognition. Traditional models using RGB and optical flow streams achieve strong performance but at a high computational cost. To address this, we introduce a representation flow algorithm to replace the optical flow branch in the egocentric action recognition model, enabling end-to-end training while reducing computational cost and prediction time. Our model, designed for egocentric action recognition, uses class activation maps (CAMs) to improve accuracy and ConvLSTM for spatio temporal encoding with spatial attention. When evaluated on the GTEA61, EGTEA GAZE+, and HMDB datasets, our model matches the accuracy of the original model on GTEA61 and exceeds it by 0.65% and 0.84% on EGTEA GAZE+ and HMDB, respectively. Prediction runtimes are significantly reduced to 0.1881s, 0.1503s, and 0.1459s, compared to the original model's 101.6795s, 25.3799s, and 203.9958s. Ablation studies were also conducted to study the impact of different parameters on model performance. Keywords: two-stream, egocentric, action recognition, CAM, representation flow, CAM, ConvLSTM