 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Technical Documents Retrieval for RAG
Sep 04, 2025In this paper, we introduce Technical-Embeddings, a novel framework designed to optimize semantic retrieval in technical documentation, with applications in both hardware and software development. Our approach addresses the challenges of understanding and retrieving complex technical content by leveraging the capabilities of Large Language Models (LLMs). First, we enhance user queries by generating expanded representations that better capture user intent and improve dataset diversity, thereby enriching the fine-tuning process for embedding models. Second, we apply summary extraction techniques to encode essential contextual information, refining the representation of technical documents. To further enhance retrieval performance, we fine-tune a bi-encoder BERT model using soft prompting, incorporating separate learning parameters for queries and document context to capture fine-grained semantic nuances. We evaluate our approach on two public datasets, RAG-EDA and Rust-Docs-QA, demonstrating that Technical-Embeddings significantly outperforms baseline models in both precision and recall. Our findings highlight the effectiveness of integrating query expansion and contextual summarization to enhance information access and comprehension in technical domains. This work advances the state of Retrieval-Augmented Generation (RAG) systems, offering new avenues for efficient and accurate technical document retrieval in engineering and product development workflows.
Automatic Prompt Generation and Grounding Object Detection for Zero-Shot Image Anomaly Detection
Nov 28, 2024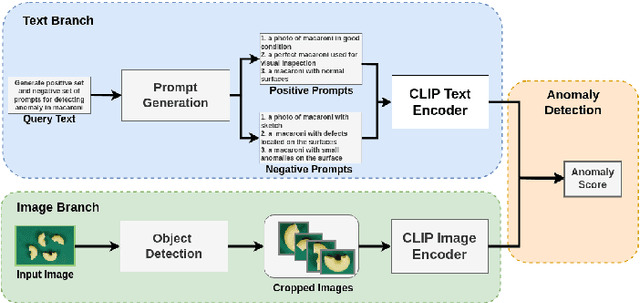

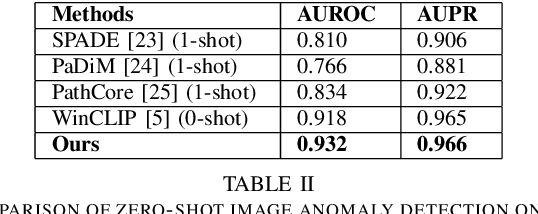
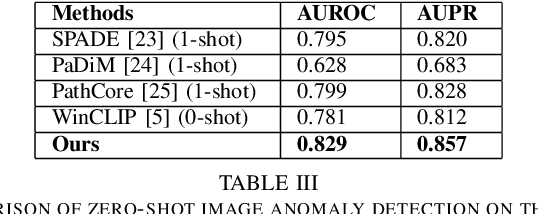
Identifying defects and anomalies in industrial products is a critical quality control task. Traditional manual inspection methods are slow, subjective, and error-prone. In this work, we propose a novel zero-shot training-free approach for automated industrial image anomaly detection using a multimodal machine learning pipeline, consisting of three foundation models. Our method first uses a large language model, i.e., GPT-3. generate text prompts describing the expected appearances of normal and abnormal products. We then use a grounding object detection model, called Grounding DINO, to locate the product in the image. Finally, we compare the cropped product image patches to the generated prompts using a zero-shot image-text matching model, called CLIP, to identify any anomalies. Our experiments on two datasets of industrial product images, namely MVTec-AD and VisA, demonstrate the effectiveness of this method, achieving high accuracy in detecting various types of defects and anomalies without the need for model training. Our proposed model enables efficient, scalable, and objective quality control in industrial manufacturing settings.
Oversampling Higher-Performing Minorities During Machine Learning Model Training Reduces Adverse Impact Slightly but Also Reduces Model Accuracy
Apr 27, 2023



Organizations are increasingly adopting machine learning (ML) for personnel assessment. However, concerns exist about fairness in designing and implementing ML assessments. Supervised ML models are trained to model patterns in data, meaning ML models tend to yield predictions that reflect subgroup differences in applicant attributes in the training data, regardless of the underlying cause of subgroup differences. In this study, we systematically under- and oversampled minority (Black and Hispanic) applicants to manipulate adverse impact ratios in training data and investigated how training data adverse impact ratios affect ML model adverse impact and accuracy. We used self-reports and interview transcripts from job applicants (N = 2,501) to train 9,702 ML models to predict screening decisions. We found that training data adverse impact related linearly to ML model adverse impact. However, removing adverse impact from training data only slightly reduced ML model adverse impact and tended to negatively affect ML model accuracy. We observed consistent effects across self-reports and interview transcripts, whether oversampling real (i.e., bootstrapping) or synthetic observations. As our study relied on limited predictor sets from one organization, the observed effects on adverse impact may be attenuated among more accurate ML models.
Multimodal Propaganda Processing
Feb 17, 2023


Propaganda campaigns have long been used to influence public opinion via disseminating biased and/or misleading information. Despite the increasing prevalence of propaganda content on the Internet, few attempts have been made by AI researchers to analyze such content. We introduce the task of multimodal propaganda processing, where the goal is to automatically analyze propaganda content. We believe that this task presents a long-term challenge to AI researchers and that successful processing of propaganda could bring machine understanding one important step closer to human understanding. We discuss the technical challenges associated with this task and outline the steps that need to be taken to address it.
CrossCodeBench: Benchmarking Cross-Task Generalization of Source Code Models
Feb 10, 2023



Despite the recent advances showing that a model pre-trained on large-scale source code data is able to gain appreciable generalization capability, it still requires a sizeable amount of data on the target task for fine-tuning. And the effectiveness of the model generalization is largely affected by the size and quality of the fine-tuning data, which is detrimental for target tasks with limited or unavailable resources. Therefore, cross-task generalization, with the goal of improving the generalization of the model to unseen tasks that have not been seen before, is of strong research and application value. In this paper, we propose a large-scale benchmark that includes 216 existing code-related tasks. Then, we annotate each task with the corresponding meta information such as task description and instruction, which contains detailed information about the task and a solution guide. This also helps us to easily create a wide variety of ``training/evaluation'' task splits to evaluate the various cross-task generalization capabilities of the model. Then we perform some preliminary experiments to demonstrate that the cross-task generalization of models can be largely improved by in-context learning methods such as few-shot learning and learning from task instructions, which shows the promising prospects of conducting cross-task learning research on our benchmark. We hope that the collection of the datasets and our benchmark will facilitate future work that is not limited to cross-task generalization.
End-to-End Neural Discourse Deixis Resolution in Dialogue
Dec 03, 2022



We adapt Lee et al.'s (2018) span-based entity coreference model to the task of end-to-end discourse deixis resolution in dialogue, specifically by proposing extensions to their model that exploit task-specific characteristics. The resulting model, dd-utt, achieves state-of-the-art results on the four datasets in the CODI-CRAC 2021 shared task.
DiscoSense: Commonsense Reasoning with Discourse Connectives
Oct 22, 2022
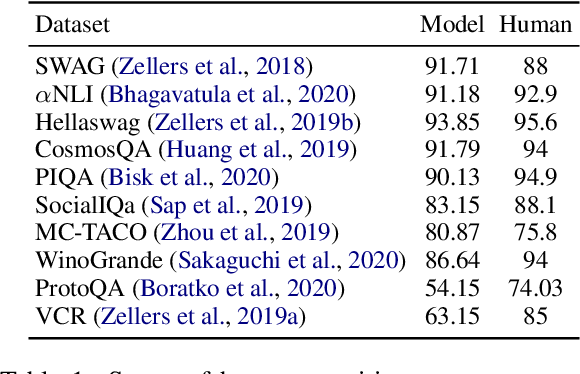
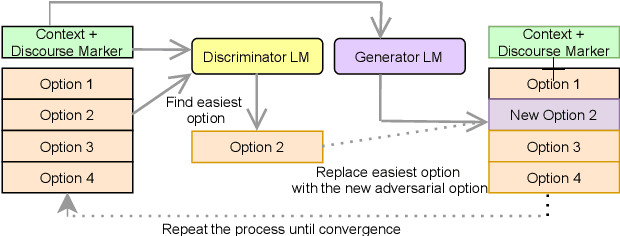
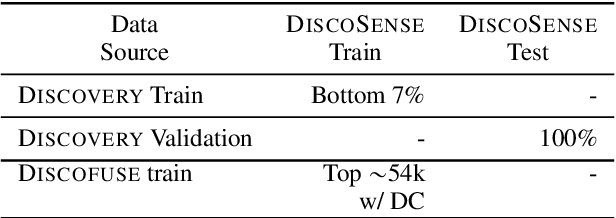
We present DiscoSense, a benchmark for commonsense reasoning via understanding a wide variety of discourse connectives. We generate compelling distractors in DiscoSense using Conditional Adversarial Filtering, an extension of Adversarial Filtering that employs conditional generation. We show that state-of-the-art pre-trained language models struggle to perform well on DiscoSense, which makes this dataset ideal for evaluating next-generation commonsense reasoning systems.
Deep Learning Meets Software Engineering: A Survey on Pre-Trained Models of Source Code
May 24, 2022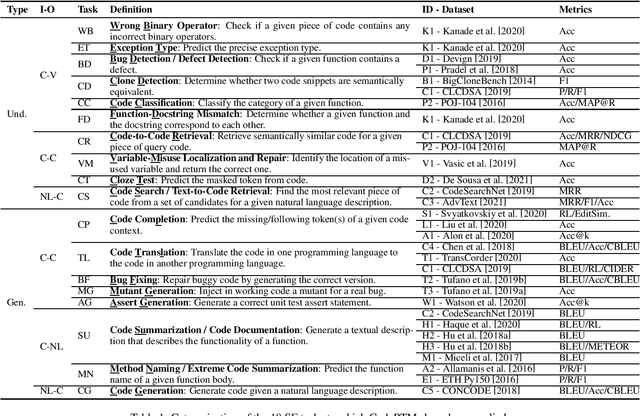

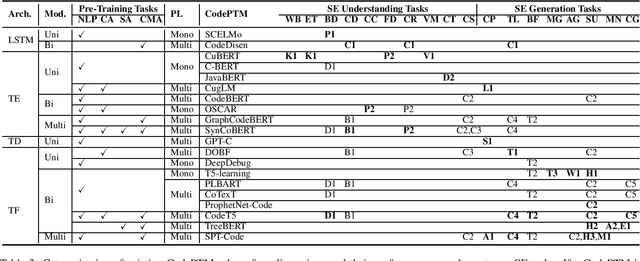
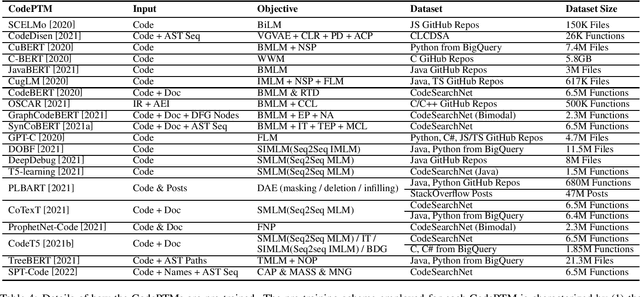
Recent years have seen the successful application of deep learning to software engineering (SE). In particular, the development and use of pre-trained models of source code has enabled state-of-the-art results to be achieved on a wide variety of SE tasks. This paper provides an overview of this rapidly advancing field of research and reflects on future research directions.
Commonsense Knowledge Reasoning and Generation with Pre-trained Language Models: A Survey
Jan 28, 2022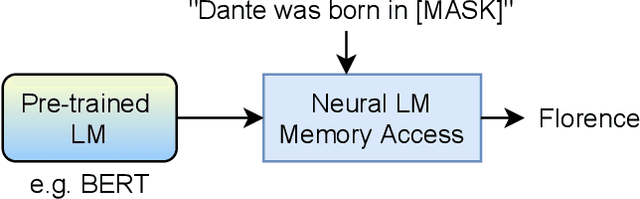

While commonsense knowledge acquisition and reasoning has traditionally been a core research topic in the knowledge representation and reasoning community, recent years have seen a surge of interest in the natural language processing community in developing pre-trained models and testing their ability to address a variety of newly designed commonsense knowledge reasoning and generation tasks. This paper presents a survey of these tasks, discusses the strengths and weaknesses of state-of-the-art pre-trained models for commonsense reasoning and generation as revealed by these tasks, and reflects on future research directions.
Synergy between Machine/Deep Learning and Software Engineering: How Far Are We?
Aug 12, 2020


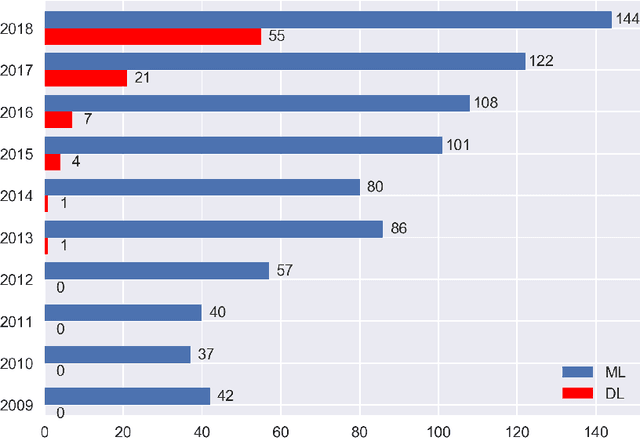
Since 2009, the deep learning revolution, which was triggered by the introduction of ImageNet, has stimulated the synergy between Machine Learning (ML)/Deep Learning (DL) and Software Engineering (SE). Meanwhile, critical reviews have emerged that suggest that ML/DL should be used cautiously. To improve the quality (especially the applicability and generalizability) of ML/DL-related SE studies, and to stimulate and enhance future collaborations between SE/AI researchers and industry practitioners, we conducted a 10-year Systematic Literature Review (SLR) on 906 ML/DL-related SE papers published between 2009 and 2018. Our trend analysis demonstrated the mutual impacts that ML/DL and SE have had on each other. At the same time, however, we also observed a paucity of replicable and reproducible ML/DL-related SE studies and identified five factors that influence their replicability and reproducibility. To improve the applicability and generalizability of research results, we analyzed what ingredients in a study would facilitate an understanding of why a ML/DL technique was selected for a specific SE problem. In addition, we identified the unique trends of impacts of DL models on SE tasks, as well as five unique challenges that needed to be met in order to better leverage DL to improve the productivity of SE tasks. Finally, we outlined a road-map that we believe can facilitate the transfer of ML/DL-based SE research results into real-world industry practices.