 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOversampling Higher-Performing Minorities During Machine Learning Model Training Reduces Adverse Impact Slightly but Also Reduces Model Accuracy
Apr 27, 2023



Organizations are increasingly adopting machine learning (ML) for personnel assessment. However, concerns exist about fairness in designing and implementing ML assessments. Supervised ML models are trained to model patterns in data, meaning ML models tend to yield predictions that reflect subgroup differences in applicant attributes in the training data, regardless of the underlying cause of subgroup differences. In this study, we systematically under- and oversampled minority (Black and Hispanic) applicants to manipulate adverse impact ratios in training data and investigated how training data adverse impact ratios affect ML model adverse impact and accuracy. We used self-reports and interview transcripts from job applicants (N = 2,501) to train 9,702 ML models to predict screening decisions. We found that training data adverse impact related linearly to ML model adverse impact. However, removing adverse impact from training data only slightly reduced ML model adverse impact and tended to negatively affect ML model accuracy. We observed consistent effects across self-reports and interview transcripts, whether oversampling real (i.e., bootstrapping) or synthetic observations. As our study relied on limited predictor sets from one organization, the observed effects on adverse impact may be attenuated among more accurate ML models.
Ground-Truth, Whose Truth? -- Examining the Challenges with Annotating Toxic Text Datasets
Dec 07, 2021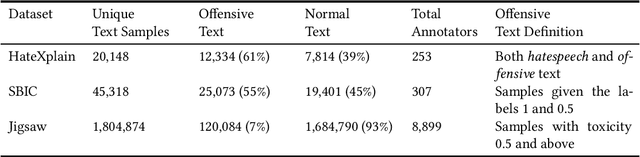
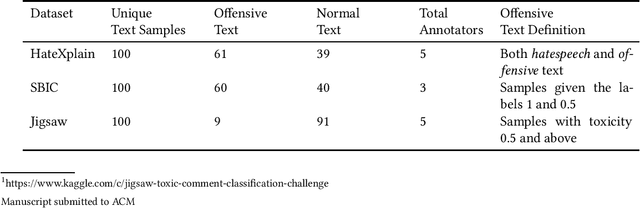
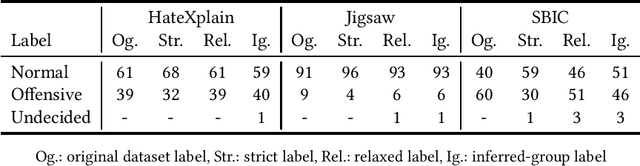

The use of machine learning (ML)-based language models (LMs) to monitor content online is on the rise. For toxic text identification, task-specific fine-tuning of these models are performed using datasets labeled by annotators who provide ground-truth labels in an effort to distinguish between offensive and normal content. These projects have led to the development, improvement, and expansion of large datasets over time, and have contributed immensely to research on natural language. Despite the achievements, existing evidence suggests that ML models built on these datasets do not always result in desirable outcomes. Therefore, using a design science research (DSR) approach, this study examines selected toxic text datasets with the goal of shedding light on some of the inherent issues and contributing to discussions on navigating these challenges for existing and future projects. To achieve the goal of the study, we re-annotate samples from three toxic text datasets and find that a multi-label approach to annotating toxic text samples can help to improve dataset quality. While this approach may not improve the traditional metric of inter-annotator agreement, it may better capture dependence on context and diversity in annotators. We discuss the implications of these results for both theory and practice.