 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Causal Inference of Group Effects in Non-Targeted Trials with Finitely Many Effect Levels
Apr 22, 2025A treatment may be appropriate for some group (the ``sick" group) on whom it has a positive effect, but it can also have a detrimental effect on subjects from another group (the ``healthy" group). In a non-targeted trial both sick and healthy subjects may be treated, producing heterogeneous effects within the treated group. Inferring the correct treatment effect on the sick population is then difficult, because the effects on the different groups get tangled. We propose an efficient nonparametric approach to estimating the group effects, called {\bf PCM} (pre-cluster and merge). We prove its asymptotic consistency in a general setting and show, on synthetic data, more than a 10x improvement in accuracy over existing state-of-the-art. Our approach applies more generally to consistent estimation of functions with a finite range.
Whither Bias Goes, I Will Go: An Integrative, Systematic Review of Algorithmic Bias Mitigation
Oct 21, 2024
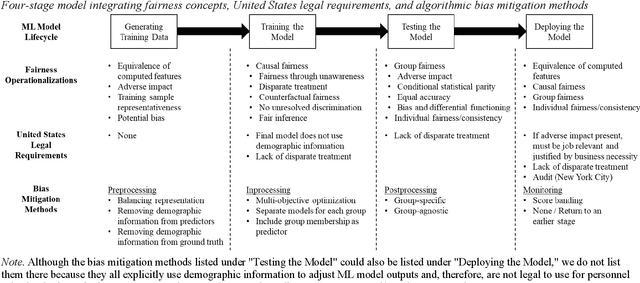

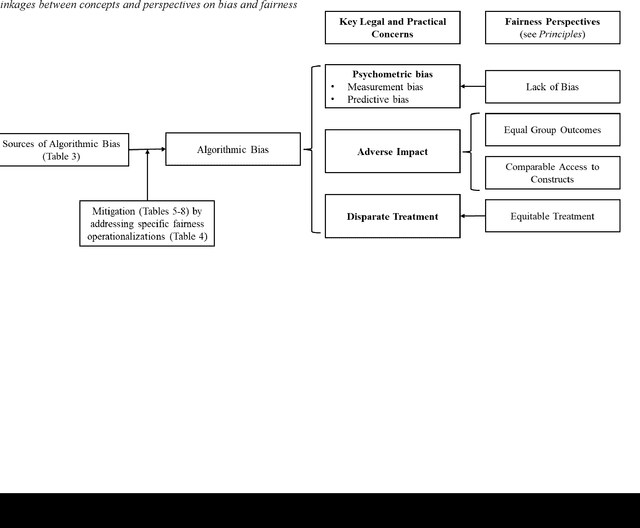
Machine learning (ML) models are increasingly used for personnel assessment and selection (e.g., resume screeners, automatically scored interviews). However, concerns have been raised throughout society that ML assessments may be biased and perpetuate or exacerbate inequality. Although organizational researchers have begun investigating ML assessments from traditional psychometric and legal perspectives, there is a need to understand, clarify, and integrate fairness operationalizations and algorithmic bias mitigation methods from the computer science, data science, and organizational research literatures. We present a four-stage model of developing ML assessments and applying bias mitigation methods, including 1) generating the training data, 2) training the model, 3) testing the model, and 4) deploying the model. When introducing the four-stage model, we describe potential sources of bias and unfairness at each stage. Then, we systematically review definitions and operationalizations of algorithmic bias, legal requirements governing personnel selection from the United States and Europe, and research on algorithmic bias mitigation across multiple domains and integrate these findings into our framework. Our review provides insights for both research and practice by elucidating possible mechanisms of algorithmic bias while identifying which bias mitigation methods are legal and effective. This integrative framework also reveals gaps in the knowledge of algorithmic bias mitigation that should be addressed by future collaborative research between organizational researchers, computer scientists, and data scientists. We provide recommendations for developing and deploying ML assessments, as well as recommendations for future research into algorithmic bias and fairness.
Oversampling Higher-Performing Minorities During Machine Learning Model Training Reduces Adverse Impact Slightly but Also Reduces Model Accuracy
Apr 27, 2023



Organizations are increasingly adopting machine learning (ML) for personnel assessment. However, concerns exist about fairness in designing and implementing ML assessments. Supervised ML models are trained to model patterns in data, meaning ML models tend to yield predictions that reflect subgroup differences in applicant attributes in the training data, regardless of the underlying cause of subgroup differences. In this study, we systematically under- and oversampled minority (Black and Hispanic) applicants to manipulate adverse impact ratios in training data and investigated how training data adverse impact ratios affect ML model adverse impact and accuracy. We used self-reports and interview transcripts from job applicants (N = 2,501) to train 9,702 ML models to predict screening decisions. We found that training data adverse impact related linearly to ML model adverse impact. However, removing adverse impact from training data only slightly reduced ML model adverse impact and tended to negatively affect ML model accuracy. We observed consistent effects across self-reports and interview transcripts, whether oversampling real (i.e., bootstrapping) or synthetic observations. As our study relied on limited predictor sets from one organization, the observed effects on adverse impact may be attenuated among more accurate ML models.