 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhither Bias Goes, I Will Go: An Integrative, Systematic Review of Algorithmic Bias Mitigation
Paper and Code
Oct 21, 2024
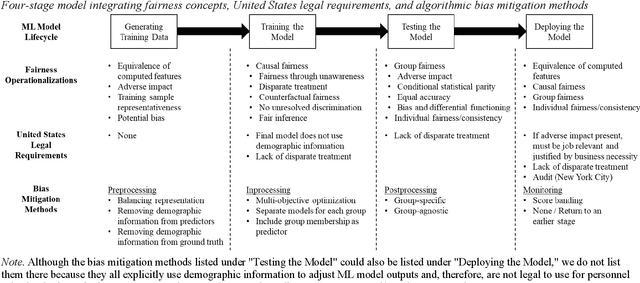

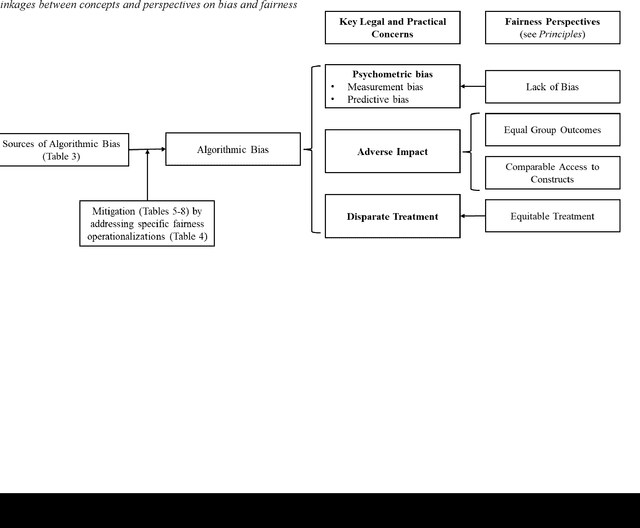
Machine learning (ML) models are increasingly used for personnel assessment and selection (e.g., resume screeners, automatically scored interviews). However, concerns have been raised throughout society that ML assessments may be biased and perpetuate or exacerbate inequality. Although organizational researchers have begun investigating ML assessments from traditional psychometric and legal perspectives, there is a need to understand, clarify, and integrate fairness operationalizations and algorithmic bias mitigation methods from the computer science, data science, and organizational research literatures. We present a four-stage model of developing ML assessments and applying bias mitigation methods, including 1) generating the training data, 2) training the model, 3) testing the model, and 4) deploying the model. When introducing the four-stage model, we describe potential sources of bias and unfairness at each stage. Then, we systematically review definitions and operationalizations of algorithmic bias, legal requirements governing personnel selection from the United States and Europe, and research on algorithmic bias mitigation across multiple domains and integrate these findings into our framework. Our review provides insights for both research and practice by elucidating possible mechanisms of algorithmic bias while identifying which bias mitigation methods are legal and effective. This integrative framework also reveals gaps in the knowledge of algorithmic bias mitigation that should be addressed by future collaborative research between organizational researchers, computer scientists, and data scientists. We provide recommendations for developing and deploying ML assessments, as well as recommendations for future research into algorithmic bias and fairness.