 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Markov Chain Model for Identifying Changes in Daily Activity Patterns of People Living with Dementia
Jul 20, 2023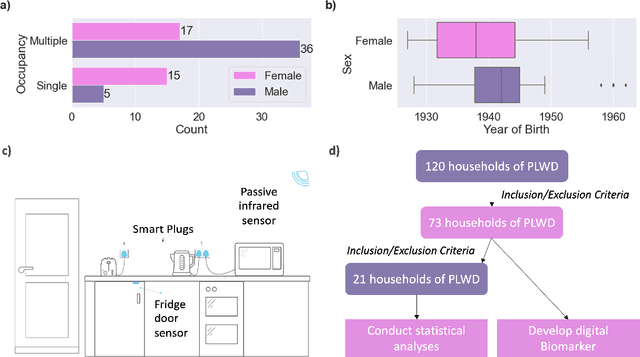
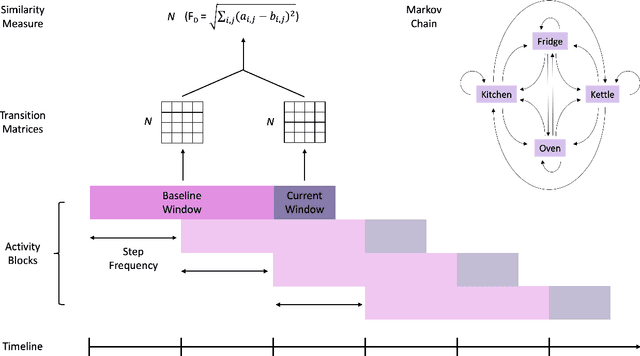
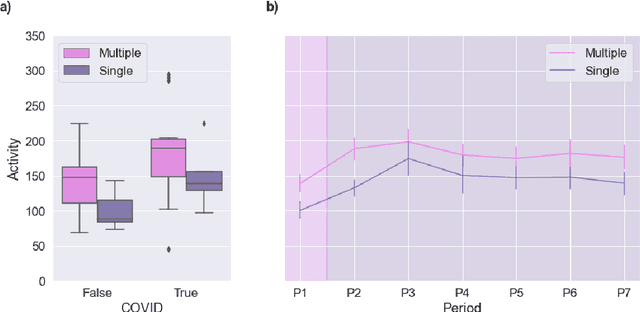
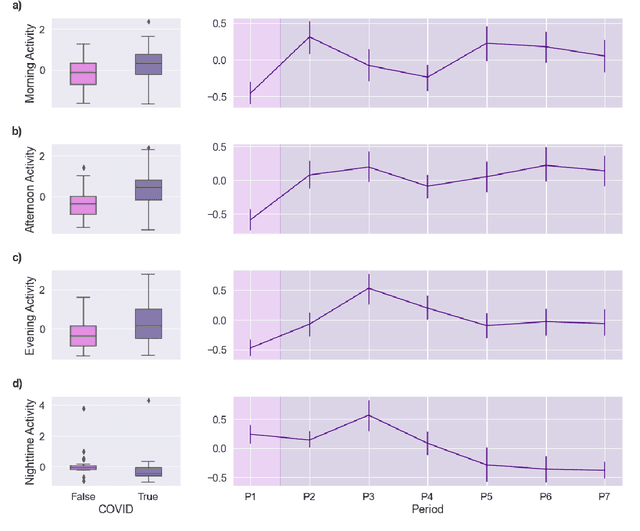
Malnutrition and dehydration are strongly associated with increased cognitive and functional decline in people living with dementia (PLWD), as well as an increased rate of hospitalisations in comparison to their healthy counterparts. Extreme changes in eating and drinking behaviours can often lead to malnutrition and dehydration, accelerating the progression of cognitive and functional decline and resulting in a marked reduction in quality of life. Unfortunately, there are currently no established methods by which to objectively detect such changes. Here, we present the findings of an extensive quantitative analysis conducted on in-home monitoring data collected from 73 households of PLWD using Internet of Things technologies. The Coronavirus 2019 (COVID-19) pandemic has previously been shown to have dramatically altered the behavioural habits, particularly the eating and drinking habits, of PLWD. Using the COVID-19 pandemic as a natural experiment, we conducted linear mixed-effects modelling to examine changes in mean kitchen activity within a subset of 21 households of PLWD that were continuously monitored for 499 days. We report an observable increase in day-time kitchen activity and a significant decrease in night-time kitchen activity (t(147) = -2.90, p < 0.001). We further propose a novel analytical approach to detecting changes in behaviours of PLWD using Markov modelling applied to remote monitoring data as a proxy for behaviours that cannot be directly measured. Together, these results pave the way to introduce improvements into the monitoring of PLWD in naturalistic settings and for shifting from reactive to proactive care.
Oversampling Higher-Performing Minorities During Machine Learning Model Training Reduces Adverse Impact Slightly but Also Reduces Model Accuracy
Apr 27, 2023



Organizations are increasingly adopting machine learning (ML) for personnel assessment. However, concerns exist about fairness in designing and implementing ML assessments. Supervised ML models are trained to model patterns in data, meaning ML models tend to yield predictions that reflect subgroup differences in applicant attributes in the training data, regardless of the underlying cause of subgroup differences. In this study, we systematically under- and oversampled minority (Black and Hispanic) applicants to manipulate adverse impact ratios in training data and investigated how training data adverse impact ratios affect ML model adverse impact and accuracy. We used self-reports and interview transcripts from job applicants (N = 2,501) to train 9,702 ML models to predict screening decisions. We found that training data adverse impact related linearly to ML model adverse impact. However, removing adverse impact from training data only slightly reduced ML model adverse impact and tended to negatively affect ML model accuracy. We observed consistent effects across self-reports and interview transcripts, whether oversampling real (i.e., bootstrapping) or synthetic observations. As our study relied on limited predictor sets from one organization, the observed effects on adverse impact may be attenuated among more accurate ML models.