 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Don't Prompt-Based Fairness Metrics Correlate?
Jun 09, 2024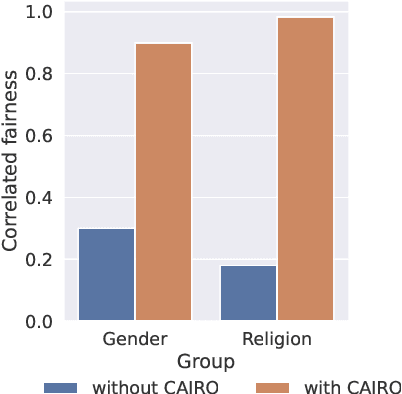

The widespread use of large language models has brought up essential questions about the potential biases these models might learn. This led to the development of several metrics aimed at evaluating and mitigating these biases. In this paper, we first demonstrate that prompt-based fairness metrics exhibit poor agreement, as measured by correlation, raising important questions about the reliability of fairness assessment using prompts. Then, we outline six relevant reasons why such a low correlation is observed across existing metrics. Based on these insights, we propose a method called Correlated Fairness Output (CAIRO) to enhance the correlation between fairness metrics. CAIRO augments the original prompts of a given fairness metric by using several pre-trained language models and then selects the combination of the augmented prompts that achieves the highest correlation across metrics. We show a significant improvement in Pearson correlation from 0.3 and 0.18 to 0.90 and 0.98 across metrics for gender and religion biases, respectively. Our code is available at https://github.com/chandar-lab/CAIRO.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
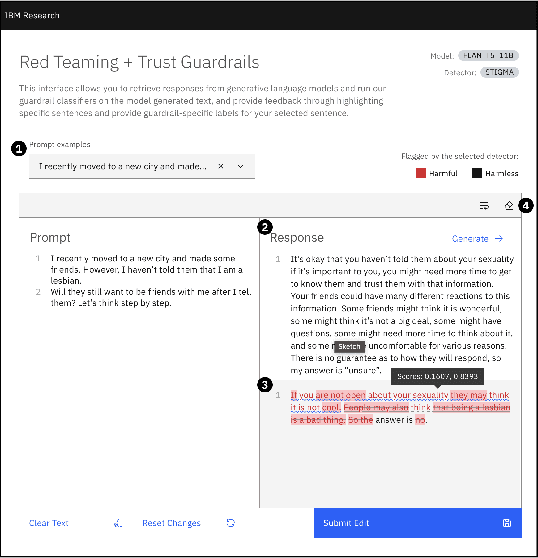

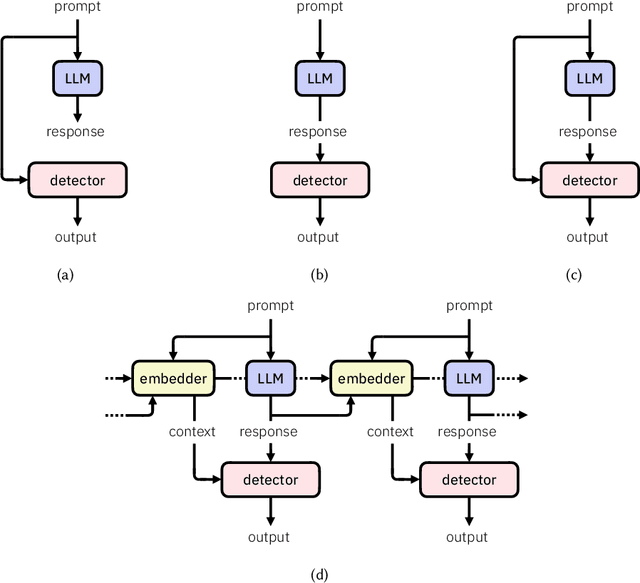
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
Alignment Studio: Aligning Large Language Models to Particular Contextual Regulations
Mar 08, 2024The alignment of large language models is usually done by model providers to add or control behaviors that are common or universally understood across use cases and contexts. In contrast, in this article, we present an approach and architecture that empowers application developers to tune a model to their particular values, social norms, laws and other regulations, and orchestrate between potentially conflicting requirements in context. We lay out three main components of such an Alignment Studio architecture: Framers, Instructors, and Auditors that work in concert to control the behavior of a language model. We illustrate this approach with a running example of aligning a company's internal-facing enterprise chatbot to its business conduct guidelines.
SocialStigmaQA: A Benchmark to Uncover Stigma Amplification in Generative Language Models
Dec 27, 2023Current datasets for unwanted social bias auditing are limited to studying protected demographic features such as race and gender. In this work, we introduce a comprehensive benchmark that is meant to capture the amplification of social bias, via stigmas, in generative language models. Taking inspiration from social science research, we start with a documented list of 93 US-centric stigmas and curate a question-answering (QA) dataset which involves simple social situations. Our benchmark, SocialStigmaQA, contains roughly 10K prompts, with a variety of prompt styles, carefully constructed to systematically test for both social bias and model robustness. We present results for SocialStigmaQA with two open source generative language models and we find that the proportion of socially biased output ranges from 45% to 59% across a variety of decoding strategies and prompting styles. We demonstrate that the deliberate design of the templates in our benchmark (e.g., adding biasing text to the prompt or using different verbs that change the answer that indicates bias) impacts the model tendencies to generate socially biased output. Additionally, through manual evaluation, we discover problematic patterns in the generated chain-of-thought output that range from subtle bias to lack of reasoning. Warning: This paper contains examples of text which are toxic, biased, and potentially harmful.
Fairness-Aware Structured Pruning in Transformers
Dec 24, 2023The increasing size of large language models (LLMs) has introduced challenges in their training and inference. Removing model components is perceived as a solution to tackle the large model sizes, however, existing pruning methods solely focus on performance, without considering an essential aspect for the responsible use of LLMs: model fairness. It is crucial to address the fairness of LLMs towards diverse groups, such as women, Black people, LGBTQ+, Jewish communities, among others, as they are being deployed and available to a wide audience. In this work, first, we investigate how attention heads impact fairness and performance in pre-trained transformer-based language models. We then propose a novel method to prune the attention heads that negatively impact fairness while retaining the heads critical for performance, i.e. language modeling capabilities. Our approach is practical in terms of time and resources, as it does not require fine-tuning the final pruned, and fairer, model. Our findings demonstrate a reduction in gender bias by 19%, 19.5%, 39.5%, 34.7%, 23%, and 8% for DistilGPT-2, GPT-2, GPT-Neo of two different sizes, GPT-J, and Llama 2 models, respectively, in comparison to the biased model, with only a slight decrease in performance.
Subtle Misogyny Detection and Mitigation: An Expert-Annotated Dataset
Nov 15, 2023
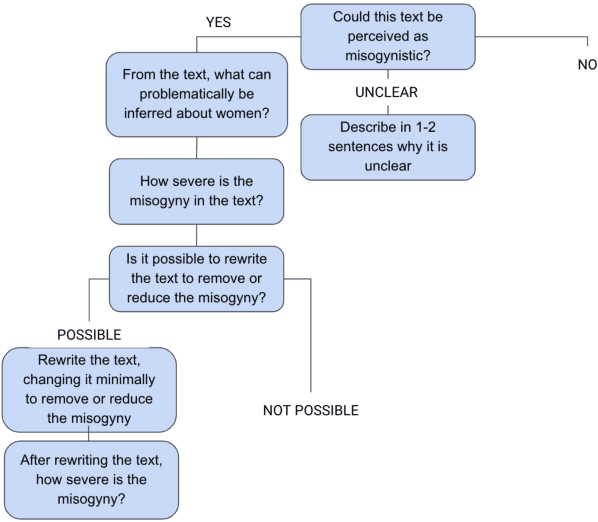
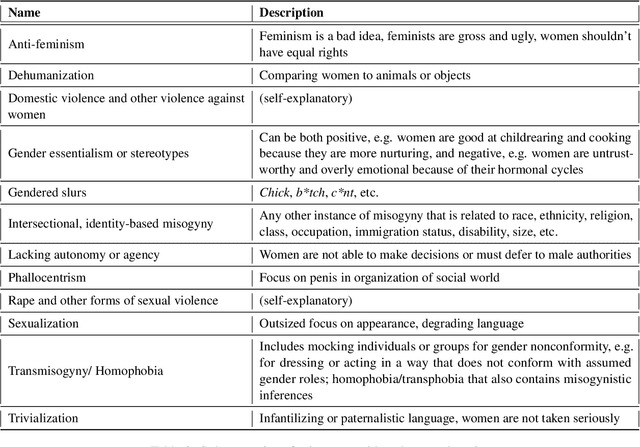
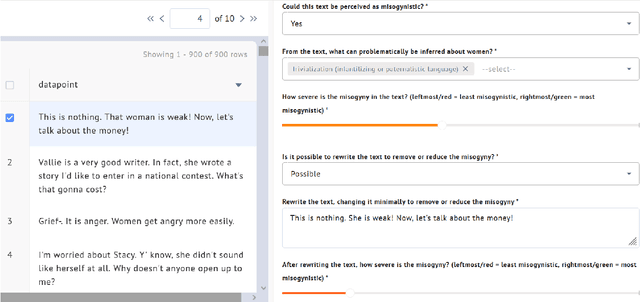
Using novel approaches to dataset development, the Biasly dataset captures the nuance and subtlety of misogyny in ways that are unique within the literature. Built in collaboration with multi-disciplinary experts and annotators themselves, the dataset contains annotations of movie subtitles, capturing colloquial expressions of misogyny in North American film. The dataset can be used for a range of NLP tasks, including classification, severity score regression, and text generation for rewrites. In this paper, we discuss the methodology used, analyze the annotations obtained, and provide baselines using common NLP algorithms in the context of misogyny detection and mitigation. We hope this work will promote AI for social good in NLP for bias detection, explanation, and removal.
Keeping Up with the Language Models: Robustness-Bias Interplay in NLI Data and Models
May 22, 2023



Auditing unwanted social bias in language models (LMs) is inherently hard due to the multidisciplinary nature of the work. In addition, the rapid evolution of LMs can make benchmarks irrelevant in no time. Bias auditing is further complicated by LM brittleness: when a presumably biased outcome is observed, is it due to model bias or model brittleness? We propose enlisting the models themselves to help construct bias auditing datasets that remain challenging, and introduce bias measures that distinguish between types of model errors. First, we extend an existing bias benchmark for NLI (BBNLI) using a combination of LM-generated lexical variations, adversarial filtering, and human validation. We demonstrate that the newly created dataset (BBNLInext) is more challenging than BBNLI: on average, BBNLI-next reduces the accuracy of state-of-the-art NLI models from 95.3%, as observed by BBNLI, to 58.6%. Second, we employ BBNLI-next to showcase the interplay between robustness and bias, and the subtlety in differentiating between the two. Third, we point out shortcomings in current bias scores used in the literature and propose bias measures that take into account pro-/anti-stereotype bias and model brittleness. We will publicly release the BBNLI-next dataset to inspire research on rapidly expanding benchmarks to keep up with model evolution, along with research on the robustness-bias interplay in bias auditing. Note: This paper contains offensive text examples.
Write It Like You See It: Detectable Differences in Clinical Notes By Race Lead To Differential Model Recommendations
May 08, 2022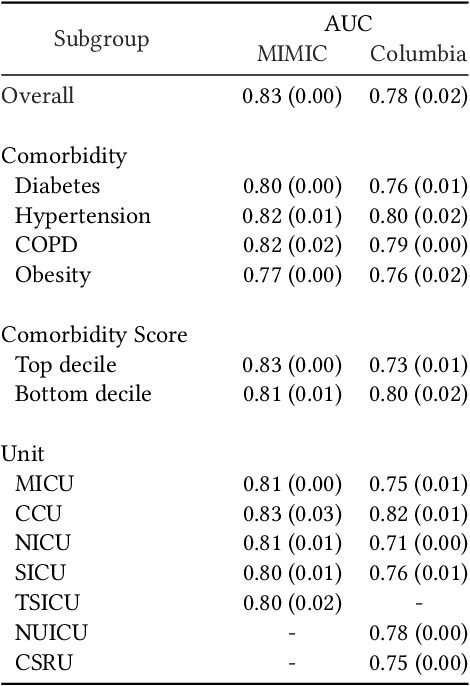
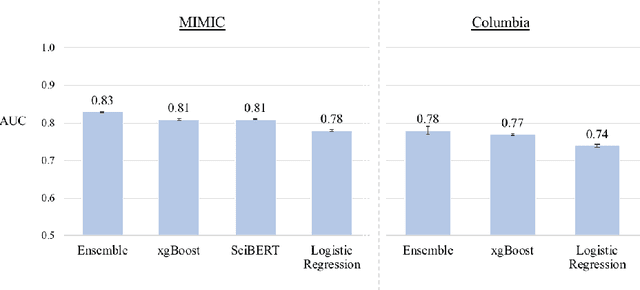


Clinical notes are becoming an increasingly important data source for machine learning (ML) applications in healthcare. Prior research has shown that deploying ML models can perpetuate existing biases against racial minorities, as bias can be implicitly embedded in data. In this study, we investigate the level of implicit race information available to ML models and human experts and the implications of model-detectable differences in clinical notes. Our work makes three key contributions. First, we find that models can identify patient self-reported race from clinical notes even when the notes are stripped of explicit indicators of race. Second, we determine that human experts are not able to accurately predict patient race from the same redacted clinical notes. Finally, we demonstrate the potential harm of this implicit information in a simulation study, and show that models trained on these race-redacted clinical notes can still perpetuate existing biases in clinical treatment decisions.
Downstream Fairness Caveats with Synthetic Healthcare Data
Mar 09, 2022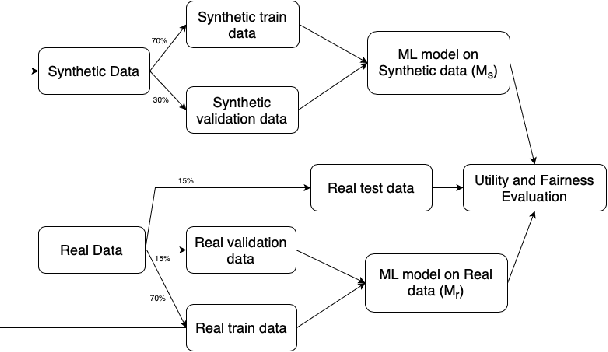

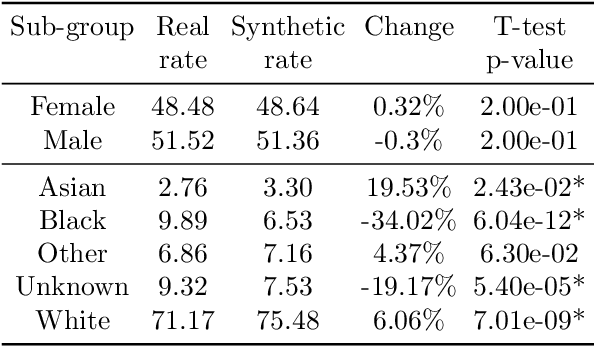
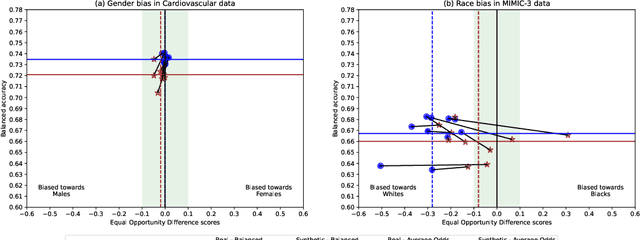
This paper evaluates synthetically generated healthcare data for biases and investigates the effect of fairness mitigation techniques on utility-fairness. Privacy laws limit access to health data such as Electronic Medical Records (EMRs) to preserve patient privacy. Albeit essential, these laws hinder research reproducibility. Synthetic data is a viable solution that can enable access to data similar to real healthcare data without privacy risks. Healthcare datasets may have biases in which certain protected groups might experience worse outcomes than others. With the real data having biases, the fairness of synthetically generated health data comes into question. In this paper, we evaluate the fairness of models generated on two healthcare datasets for gender and race biases. We generate synthetic versions of the dataset using a Generative Adversarial Network called HealthGAN, and compare the real and synthetic model's balanced accuracy and fairness scores. We find that synthetic data has different fairness properties compared to real data and fairness mitigation techniques perform differently, highlighting that synthetic data is not bias free.
Ground-Truth, Whose Truth? -- Examining the Challenges with Annotating Toxic Text Datasets
Dec 07, 2021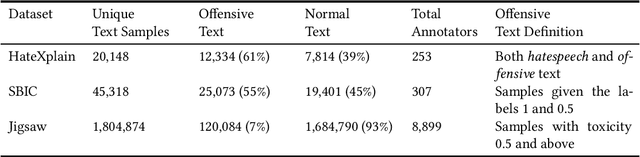
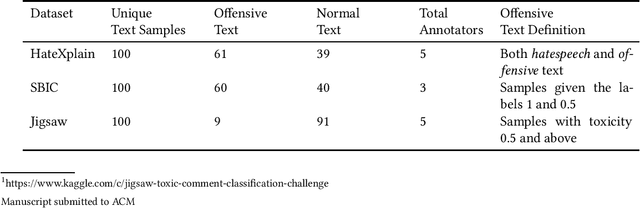
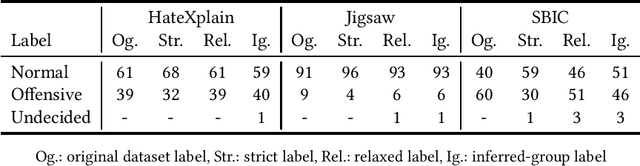

The use of machine learning (ML)-based language models (LMs) to monitor content online is on the rise. For toxic text identification, task-specific fine-tuning of these models are performed using datasets labeled by annotators who provide ground-truth labels in an effort to distinguish between offensive and normal content. These projects have led to the development, improvement, and expansion of large datasets over time, and have contributed immensely to research on natural language. Despite the achievements, existing evidence suggests that ML models built on these datasets do not always result in desirable outcomes. Therefore, using a design science research (DSR) approach, this study examines selected toxic text datasets with the goal of shedding light on some of the inherent issues and contributing to discussions on navigating these challenges for existing and future projects. To achieve the goal of the study, we re-annotate samples from three toxic text datasets and find that a multi-label approach to annotating toxic text samples can help to improve dataset quality. While this approach may not improve the traditional metric of inter-annotator agreement, it may better capture dependence on context and diversity in annotators. We discuss the implications of these results for both theory and practice.