 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWrite It Like You See It: Detectable Differences in Clinical Notes By Race Lead To Differential Model Recommendations
May 08, 2022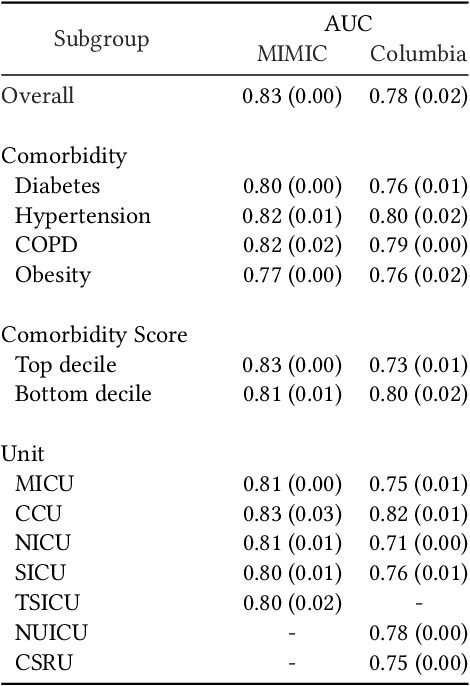


Clinical notes are becoming an increasingly important data source for machine learning (ML) applications in healthcare. Prior research has shown that deploying ML models can perpetuate existing biases against racial minorities, as bias can be implicitly embedded in data. In this study, we investigate the level of implicit race information available to ML models and human experts and the implications of model-detectable differences in clinical notes. Our work makes three key contributions. First, we find that models can identify patient self-reported race from clinical notes even when the notes are stripped of explicit indicators of race. Second, we determine that human experts are not able to accurately predict patient race from the same redacted clinical notes. Finally, we demonstrate the potential harm of this implicit information in a simulation study, and show that models trained on these race-redacted clinical notes can still perpetuate existing biases in clinical treatment decisions.
Downstream Fairness Caveats with Synthetic Healthcare Data
Mar 09, 2022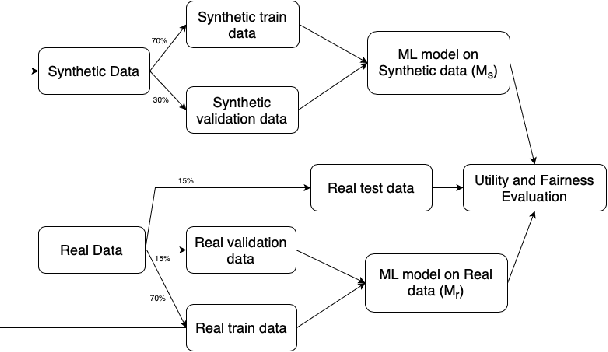

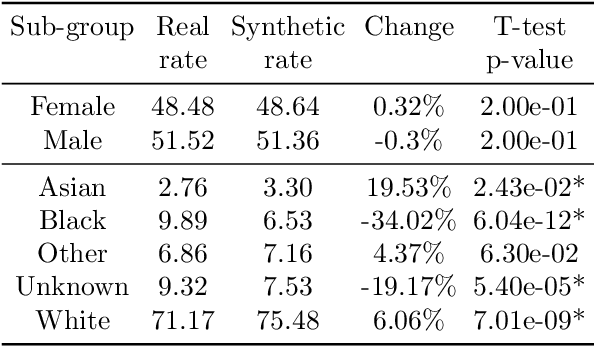
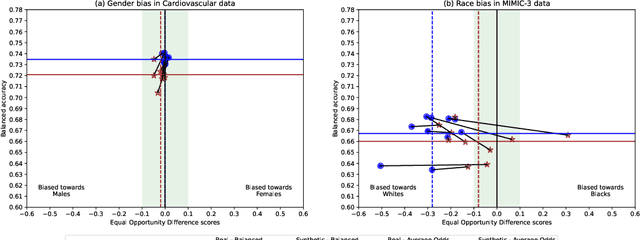
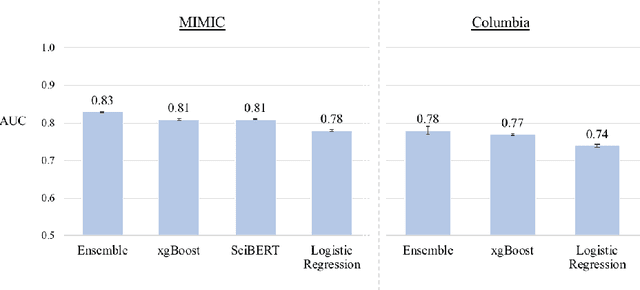
This paper evaluates synthetically generated healthcare data for biases and investigates the effect of fairness mitigation techniques on utility-fairness. Privacy laws limit access to health data such as Electronic Medical Records (EMRs) to preserve patient privacy. Albeit essential, these laws hinder research reproducibility. Synthetic data is a viable solution that can enable access to data similar to real healthcare data without privacy risks. Healthcare datasets may have biases in which certain protected groups might experience worse outcomes than others. With the real data having biases, the fairness of synthetically generated health data comes into question. In this paper, we evaluate the fairness of models generated on two healthcare datasets for gender and race biases. We generate synthetic versions of the dataset using a Generative Adversarial Network called HealthGAN, and compare the real and synthetic model's balanced accuracy and fairness scores. We find that synthetic data has different fairness properties compared to real data and fairness mitigation techniques perform differently, highlighting that synthetic data is not bias free.
The Relevance of Bayesian Layer Positioning to Model Uncertainty in Deep Bayesian Active Learning
Nov 29, 2018



One of the main challenges of deep learning tools is their inability to capture model uncertainty. While Bayesian deep learning can be used to tackle the problem, Bayesian neural networks often require more time and computational power to train than deterministic networks. Our work explores whether fully Bayesian networks are needed to successfully capture model uncertainty. We vary the number and position of Bayesian layers in a network and compare their performance on active learning with the MNIST dataset. We found that we can fully capture the model uncertainty by using only a few Bayesian layers near the output of the network, combining the advantages of deterministic and Bayesian networks.
Interpretable Classification Models for Recidivism Prediction
Jul 08, 2016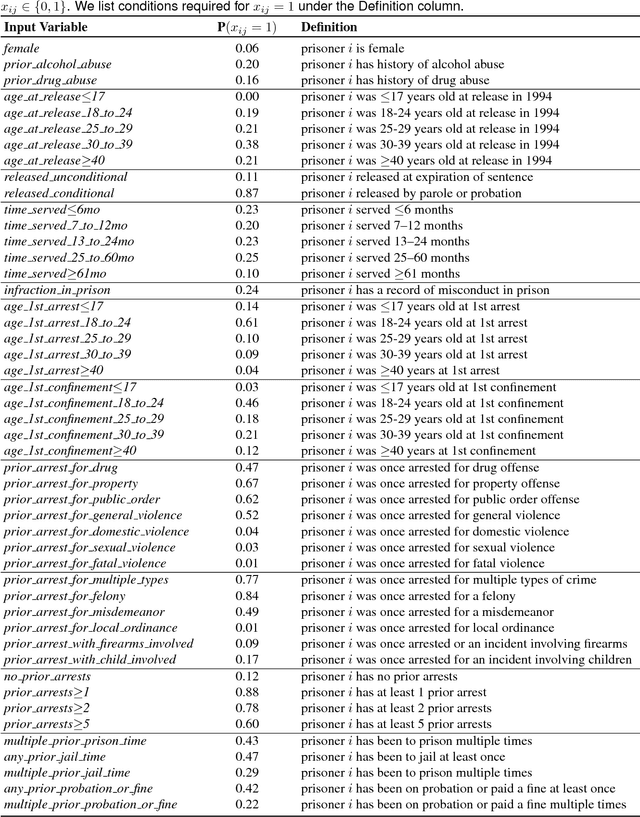



We investigate a long-debated question, which is how to create predictive models of recidivism that are sufficiently accurate, transparent, and interpretable to use for decision-making. This question is complicated as these models are used to support different decisions, from sentencing, to determining release on probation, to allocating preventative social services. Each use case might have an objective other than classification accuracy, such as a desired true positive rate (TPR) or false positive rate (FPR). Each (TPR, FPR) pair is a point on the receiver operator characteristic (ROC) curve. We use popular machine learning methods to create models along the full ROC curve on a wide range of recidivism prediction problems. We show that many methods (SVM, Ridge Regression) produce equally accurate models along the full ROC curve. However, methods that designed for interpretability (CART, C5.0) cannot be tuned to produce models that are accurate and/or interpretable. To handle this shortcoming, we use a new method known as SLIM (Supersparse Linear Integer Models) to produce accurate, transparent, and interpretable models along the full ROC curve. These models can be used for decision-making for many different use cases, since they are just as accurate as the most powerful black-box machine learning models, but completely transparent, and highly interpretable.
* 45 pages, 17 figures