 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Formal Software Specification with Artificial Intelligence
Jan 11, 2026Formal software specification is known to enable early error detection and explicit invariants, yet it has seen limited industrial adoption due to its high notation overhead and the expertise required to use traditional formal languages. This paper presents a case study showing that recent advances in artificial intelligence make it possible to retain many of the benefits of formal specification while substantially reducing these costs. The necessity of a clear distinction between what is controlled by the system analyst and can highly benefits from the rigor of formal specification and what need not be controlled is demonstrated. We use natural language augmented with lightweight mathematical notation and written in \LaTeX\ as an intermediate specification language, which is reviewed and refined by AI prior to code generation. Applied to a nontrivial simulation of organizational knowledge growth, this approach enables early validation, explicit invariants, and correctness by design, while significantly reducing development effort and producing a correct implementation on the first attempt.
PACIFIC: a framework for generating benchmarks to check Precise Automatically Checked Instruction Following In Code
Dec 22, 2025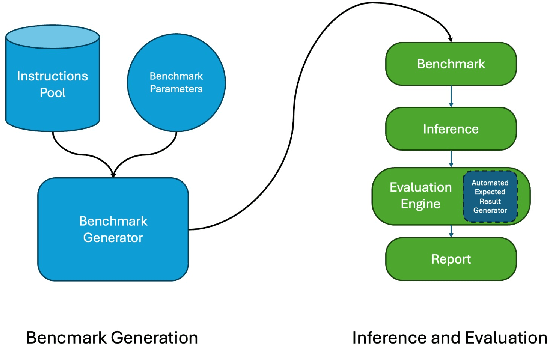
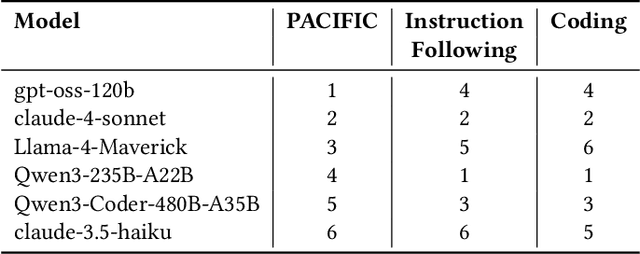
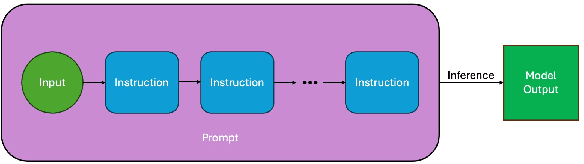
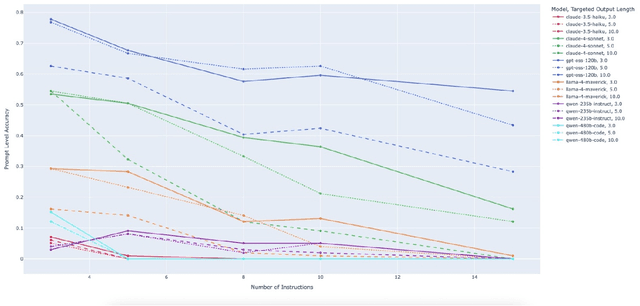
Large Language Model (LLM)-based code assistants have emerged as a powerful application of generative AI, demonstrating impressive capabilities in code generation and comprehension. A key requirement for these systems is their ability to accurately follow user instructions. We present Precise Automatically Checked Instruction Following In Code (PACIFIC), a novel framework designed to automatically generate benchmarks that rigorously assess sequential instruction-following and code dry-running capabilities in LLMs, while allowing control over benchmark difficulty. PACIFIC produces benchmark variants with clearly defined expected outputs, enabling straightforward and reliable evaluation through simple output comparisons. In contrast to existing approaches that often rely on tool usage or agentic behavior, our work isolates and evaluates the LLM's intrinsic ability to reason through code behavior step-by-step without execution (dry running) and to follow instructions. Furthermore, our framework mitigates training data contamination by facilitating effortless generation of novel benchmark variations. We validate our framework by generating a suite of benchmarks spanning a range of difficulty levels and evaluating multiple state-of-the-art LLMs. Our results demonstrate that PACIFIC can produce increasingly challenging benchmarks that effectively differentiate instruction-following and dry running capabilities, even among advanced models. Overall, our framework offers a scalable, contamination-resilient methodology for assessing core competencies of LLMs in code-related tasks.
Beyond Blind Spots: Analytic Hints for Mitigating LLM-Based Evaluation Pitfalls
Dec 18, 2025



Large Language Models are increasingly deployed as judges (LaaJ) in code generation pipelines. While attractive for scalability, LaaJs tend to overlook domain specific issues raising concerns about their reliability in critical evaluation tasks. To better understand these limitations in practice, we examine LaaJ behavior in a concrete industrial use case: legacy code modernization via COBOL code generation. In this setting, we find that even production deployed LaaJs can miss domain critical errors, revealing consistent blind spots in their evaluation capabilities. To better understand these blind spots, we analyze generated COBOL programs and associated LaaJs judgments, drawing on expert knowledge to construct a preliminary taxonomy. Based on this taxonomy, we develop a lightweight analytic checker tool that flags over 30 domain specific issues observed in practice. We use its outputs as analytic hints, dynamically injecting them into the judges prompt to encourage LaaJ to revisit aspects it may have overlooked. Experiments on a test set of 100 programs using four production level LaaJs show that LaaJ alone detects only about 45% of the errors present in the code (in all judges we tested), while the analytic checker alone lacks explanatory depth. When combined, the LaaJ+Hints configuration achieves up to 94% coverage (for the best performing judge and injection prompt) and produces qualitatively richer, more accurate explanations, demonstrating that analytic-LLM hybrids can substantially enhance evaluation reliability in deployed pipelines. We release the dataset and all used prompts.
Vintage Code, Modern Judges: Meta-Validation in Low Data Regimes
Oct 31, 2025Application modernization in legacy languages such as COBOL, PL/I, and REXX faces an acute shortage of resources, both in expert availability and in high-quality human evaluation data. While Large Language Models as a Judge (LaaJ) offer a scalable alternative to expert review, their reliability must be validated before being trusted in high-stakes workflows. Without principled validation, organizations risk a circular evaluation loop, where unverified LaaJs are used to assess model outputs, potentially reinforcing unreliable judgments and compromising downstream deployment decisions. Although various automated approaches to validating LaaJs have been proposed, alignment with human judgment remains a widely used and conceptually grounded validation strategy. In many real-world domains, the availability of human-labeled evaluation data is severely limited, making it difficult to assess how well a LaaJ aligns with human judgment. We introduce SparseAlign, a formal framework for assessing LaaJ alignment with sparse human-labeled data. SparseAlign combines a novel pairwise-confidence concept with a score-sensitive alignment metric that jointly capture ranking consistency and score proximity, enabling reliable evaluator selection even when traditional statistical methods are ineffective due to limited annotated examples. SparseAlign was applied internally to select LaaJs for COBOL code explanation. The top-aligned evaluators were integrated into assessment workflows, guiding model release decisions. We present a case study of four LaaJs to demonstrate SparseAlign's utility in real-world evaluation scenarios.
LaajMeter: A Framework for LaaJ Evaluation
Aug 13, 2025Large Language Models (LLMs) are increasingly used as evaluators in natural language processing tasks, a paradigm known as LLM-as-a-Judge (LaaJ). While effective in general domains, LaaJs pose significant challenges in domain-specific contexts, where annotated data is scarce and expert evaluation is costly. In such cases, meta-evaluation is often performed using metrics that have not been validated for the specific domain in which they are applied. As a result, it becomes difficult to determine which metrics effectively identify LaaJ quality, and further, what threshold indicates sufficient evaluator performance. In this work, we introduce LaaJMeter, a simulation-based framework for controlled meta-evaluation of LaaJs. LaaJMeter enables engineers to generate synthetic data representing virtual models and judges, allowing systematic analysis of evaluation metrics under realistic conditions. This helps practitioners validate and refine LaaJs for specific evaluation tasks: they can test whether their metrics correctly distinguish between better and worse (virtual) LaaJs, and estimate appropriate thresholds for evaluator adequacy. We demonstrate the utility of LaaJMeter in a code translation task involving a legacy programming language, showing how different metrics vary in sensitivity to evaluator quality. Our results highlight the limitations of common metrics and the importance of principled metric selection. LaaJMeter provides a scalable and extensible solution for assessing LaaJs in low-resource settings, contributing to the broader effort to ensure trustworthy and reproducible evaluation in NLP.
Statistical multi-metric evaluation and visualization of LLM system predictive performance
Jan 30, 2025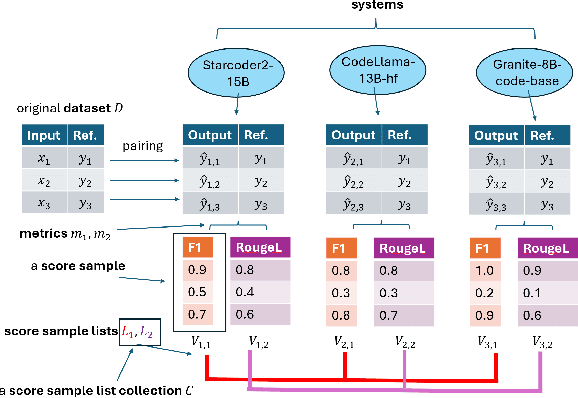

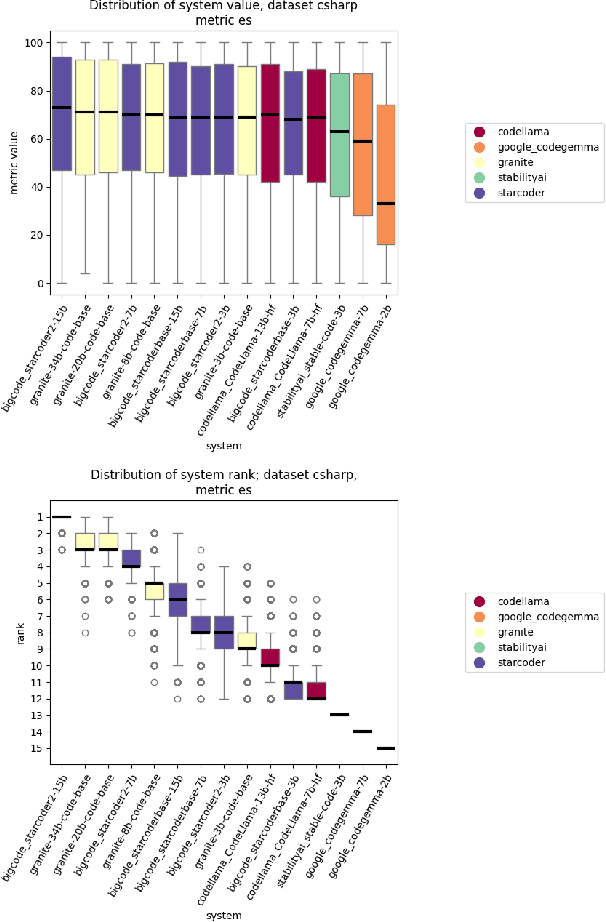
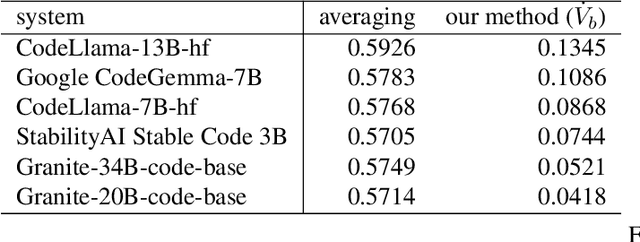
The evaluation of generative or discriminative large language model (LLM)-based systems is often a complex multi-dimensional problem. Typically, a set of system configuration alternatives are evaluated on one or more benchmark datasets, each with one or more evaluation metrics, which may differ between datasets. We often want to evaluate -- with a statistical measure of significance -- whether systems perform differently either on a given dataset according to a single metric, on aggregate across metrics on a dataset, or across datasets. Such evaluations can be done to support decision-making, such as deciding whether a particular system component change (e.g., choice of LLM or hyperparameter values) significantly improves performance over the current system configuration, or, more generally, whether a fixed set of system configurations (e.g., a leaderboard list) have significantly different performances according to metrics of interest. We present a framework implementation that automatically performs the correct statistical tests, properly aggregates the statistical results across metrics and datasets (a nontrivial task), and can visualize the results. The framework is demonstrated on the multi-lingual code generation benchmark CrossCodeEval, for several state-of-the-art LLMs.
Exploring Straightforward Conversational Red-Teaming
Sep 07, 2024



Large language models (LLMs) are increasingly used in business dialogue systems but they pose security and ethical risks. Multi-turn conversations, where context influences the model's behavior, can be exploited to produce undesired responses. In this paper, we examine the effectiveness of utilizing off-the-shelf LLMs in straightforward red-teaming approaches, where an attacker LLM aims to elicit undesired output from a target LLM, comparing both single-turn and conversational red-teaming tactics. Our experiments offer insights into various usage strategies that significantly affect their performance as red teamers. They suggest that off-the-shelf models can act as effective red teamers and even adjust their attack strategy based on past attempts, although their effectiveness decreases with greater alignment.
Can You Trust Your Metric? Automatic Concatenation-Based Tests for Metric Validity
Aug 22, 2024



Consider a scenario where a harmfulness detection metric is employed by a system to filter unsafe responses generated by a Large Language Model. When analyzing individual harmful and unethical prompt-response pairs, the metric correctly classifies each pair as highly unsafe, assigning the highest score. However, when these same prompts and responses are concatenated, the metric's decision flips, assigning the lowest possible score, thereby misclassifying the content as safe and allowing it to bypass the filter. In this study, we discovered that several harmfulness LLM-based metrics, including GPT-based, exhibit this decision-flipping phenomenon. Additionally, we found that even an advanced metric like GPT-4o is highly sensitive to input order. Specifically, it tends to classify responses as safe if the safe content appears first, regardless of any harmful content that follows, and vice versa. This work introduces automatic concatenation-based tests to assess the fundamental properties a valid metric should satisfy. We applied these tests in a model safety scenario to assess the reliability of harmfulness detection metrics, uncovering a number of inconsistencies.
A Novel Metric for Measuring the Robustness of Large Language Models in Non-adversarial Scenarios
Aug 04, 2024We evaluate the robustness of several large language models on multiple datasets. Robustness here refers to the relative insensitivity of the model's answers to meaning-preserving variants of their input. Benchmark datasets are constructed by introducing naturally-occurring, non-malicious perturbations, or by generating semantically equivalent paraphrases of input questions or statements. We further propose a novel metric for assessing a model robustness, and demonstrate its benefits in the non-adversarial scenario by empirical evaluation of several models on the created datasets.
Generating Unseen Code Tests In Infinitum
Jul 29, 2024



Large Language Models (LLMs) are used for many tasks, including those related to coding. An important aspect of being able to utilize LLMs is the ability to assess their fitness for specific usages. The common practice is to evaluate LLMs against a set of benchmarks. While benchmarks provide a sound foundation for evaluation and comparison of alternatives, they suffer from the well-known weakness of leaking into the training data \cite{Xu2024Benchmarking}. We present a method for creating benchmark variations that generalize across coding tasks and programming languages, and may also be applied to in-house code bases. Our approach enables ongoing generation of test-data thus mitigating the leaking into the training data issue. We implement one benchmark, called \textit{auto-regression}, for the task of text-to-code generation in Python. Auto-regression is specifically created to aid in debugging and in tracking model generation changes as part of the LLM regression testing process.