 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACIFIC: a framework for generating benchmarks to check Precise Automatically Checked Instruction Following In Code
Dec 22, 2025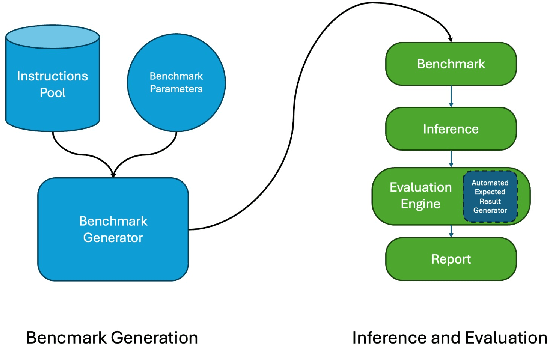
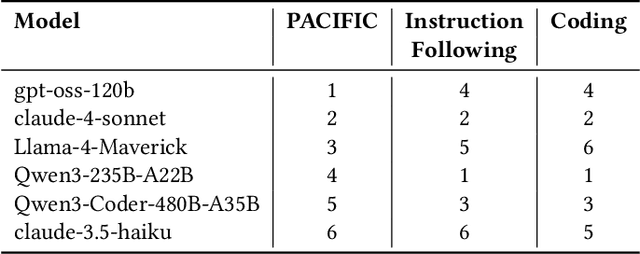
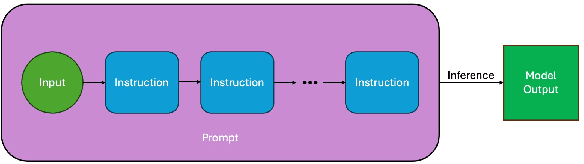
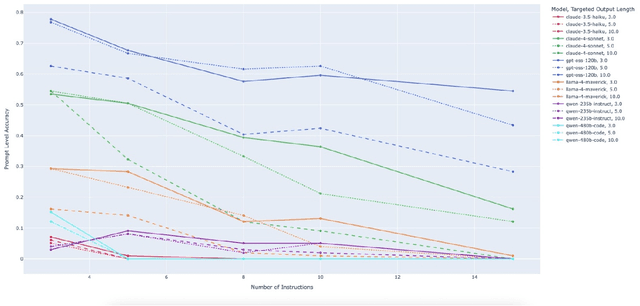
Large Language Model (LLM)-based code assistants have emerged as a powerful application of generative AI, demonstrating impressive capabilities in code generation and comprehension. A key requirement for these systems is their ability to accurately follow user instructions. We present Precise Automatically Checked Instruction Following In Code (PACIFIC), a novel framework designed to automatically generate benchmarks that rigorously assess sequential instruction-following and code dry-running capabilities in LLMs, while allowing control over benchmark difficulty. PACIFIC produces benchmark variants with clearly defined expected outputs, enabling straightforward and reliable evaluation through simple output comparisons. In contrast to existing approaches that often rely on tool usage or agentic behavior, our work isolates and evaluates the LLM's intrinsic ability to reason through code behavior step-by-step without execution (dry running) and to follow instructions. Furthermore, our framework mitigates training data contamination by facilitating effortless generation of novel benchmark variations. We validate our framework by generating a suite of benchmarks spanning a range of difficulty levels and evaluating multiple state-of-the-art LLMs. Our results demonstrate that PACIFIC can produce increasingly challenging benchmarks that effectively differentiate instruction-following and dry running capabilities, even among advanced models. Overall, our framework offers a scalable, contamination-resilient methodology for assessing core competencies of LLMs in code-related tasks.
Uncovering Code Insights: Leveraging GitHub Artifacts for Deeper Code Understanding
Nov 05, 2025Understanding the purpose of source code is a critical task in software maintenance, onboarding, and modernization. While large language models (LLMs) have shown promise in generating code explanations, they often lack grounding in the broader software engineering context. We propose a novel approach that leverages natural language artifacts from GitHub -- such as pull request descriptions, issue descriptions and discussions, and commit messages -- to enhance LLM-based code understanding. Our system consists of three components: one that extracts and structures relevant GitHub context, another that uses this context to generate high-level explanations of the code's purpose, and a third that validates the explanation. We implemented this as a standalone tool, as well as a server within the Model Context Protocol (MCP), enabling integration with other AI-assisted development tools. Our main use case is that of enhancing a standard LLM-based code explanation with code insights that our system generates. To evaluate explanations' quality, we conducted a small scale user study, with developers of several open projects, as well as developers of proprietary projects. Our user study indicates that when insights are generated they often are helpful and non trivial, and are free from hallucinations.
Vintage Code, Modern Judges: Meta-Validation in Low Data Regimes
Oct 31, 2025Application modernization in legacy languages such as COBOL, PL/I, and REXX faces an acute shortage of resources, both in expert availability and in high-quality human evaluation data. While Large Language Models as a Judge (LaaJ) offer a scalable alternative to expert review, their reliability must be validated before being trusted in high-stakes workflows. Without principled validation, organizations risk a circular evaluation loop, where unverified LaaJs are used to assess model outputs, potentially reinforcing unreliable judgments and compromising downstream deployment decisions. Although various automated approaches to validating LaaJs have been proposed, alignment with human judgment remains a widely used and conceptually grounded validation strategy. In many real-world domains, the availability of human-labeled evaluation data is severely limited, making it difficult to assess how well a LaaJ aligns with human judgment. We introduce SparseAlign, a formal framework for assessing LaaJ alignment with sparse human-labeled data. SparseAlign combines a novel pairwise-confidence concept with a score-sensitive alignment metric that jointly capture ranking consistency and score proximity, enabling reliable evaluator selection even when traditional statistical methods are ineffective due to limited annotated examples. SparseAlign was applied internally to select LaaJs for COBOL code explanation. The top-aligned evaluators were integrated into assessment workflows, guiding model release decisions. We present a case study of four LaaJs to demonstrate SparseAlign's utility in real-world evaluation scenarios.
Statistical multi-metric evaluation and visualization of LLM system predictive performance
Jan 30, 2025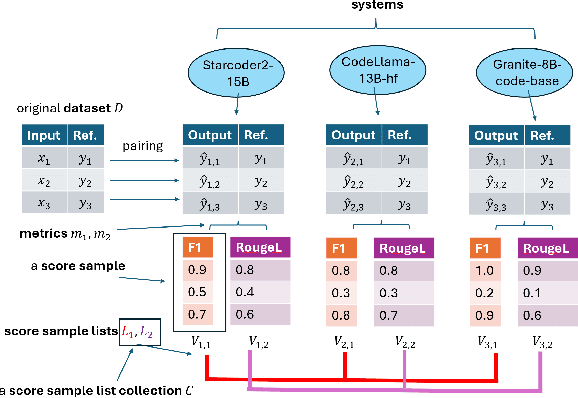

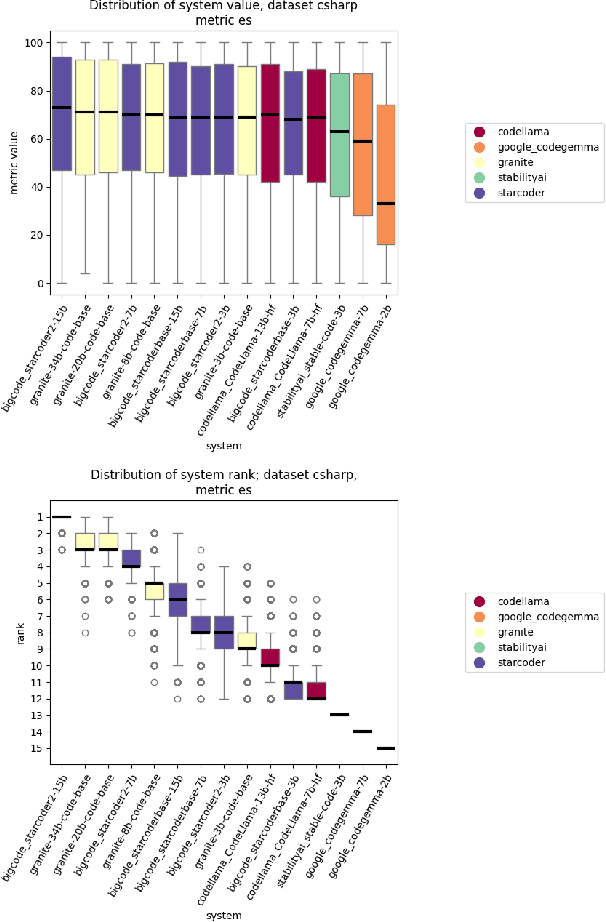
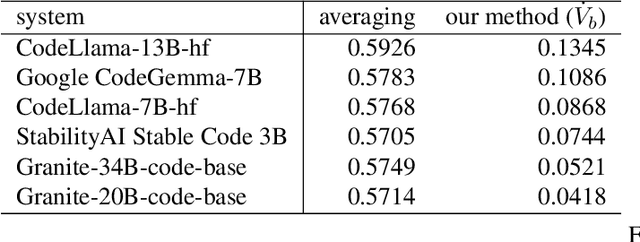
The evaluation of generative or discriminative large language model (LLM)-based systems is often a complex multi-dimensional problem. Typically, a set of system configuration alternatives are evaluated on one or more benchmark datasets, each with one or more evaluation metrics, which may differ between datasets. We often want to evaluate -- with a statistical measure of significance -- whether systems perform differently either on a given dataset according to a single metric, on aggregate across metrics on a dataset, or across datasets. Such evaluations can be done to support decision-making, such as deciding whether a particular system component change (e.g., choice of LLM or hyperparameter values) significantly improves performance over the current system configuration, or, more generally, whether a fixed set of system configurations (e.g., a leaderboard list) have significantly different performances according to metrics of interest. We present a framework implementation that automatically performs the correct statistical tests, properly aggregates the statistical results across metrics and datasets (a nontrivial task), and can visualize the results. The framework is demonstrated on the multi-lingual code generation benchmark CrossCodeEval, for several state-of-the-art LLMs.
Can You Trust Your Metric? Automatic Concatenation-Based Tests for Metric Validity
Aug 22, 2024



Consider a scenario where a harmfulness detection metric is employed by a system to filter unsafe responses generated by a Large Language Model. When analyzing individual harmful and unethical prompt-response pairs, the metric correctly classifies each pair as highly unsafe, assigning the highest score. However, when these same prompts and responses are concatenated, the metric's decision flips, assigning the lowest possible score, thereby misclassifying the content as safe and allowing it to bypass the filter. In this study, we discovered that several harmfulness LLM-based metrics, including GPT-based, exhibit this decision-flipping phenomenon. Additionally, we found that even an advanced metric like GPT-4o is highly sensitive to input order. Specifically, it tends to classify responses as safe if the safe content appears first, regardless of any harmful content that follows, and vice versa. This work introduces automatic concatenation-based tests to assess the fundamental properties a valid metric should satisfy. We applied these tests in a model safety scenario to assess the reliability of harmfulness detection metrics, uncovering a number of inconsistencies.
Generating Unseen Code Tests In Infinitum
Jul 29, 2024



Large Language Models (LLMs) are used for many tasks, including those related to coding. An important aspect of being able to utilize LLMs is the ability to assess their fitness for specific usages. The common practice is to evaluate LLMs against a set of benchmarks. While benchmarks provide a sound foundation for evaluation and comparison of alternatives, they suffer from the well-known weakness of leaking into the training data \cite{Xu2024Benchmarking}. We present a method for creating benchmark variations that generalize across coding tasks and programming languages, and may also be applied to in-house code bases. Our approach enables ongoing generation of test-data thus mitigating the leaking into the training data issue. We implement one benchmark, called \textit{auto-regression}, for the task of text-to-code generation in Python. Auto-regression is specifically created to aid in debugging and in tracking model generation changes as part of the LLM regression testing process.
Using Combinatorial Optimization to Design a High quality LLM Solution
May 15, 2024We introduce a novel LLM based solution design approach that utilizes combinatorial optimization and sampling. Specifically, a set of factors that influence the quality of the solution are identified. They typically include factors that represent prompt types, LLM inputs alternatives, and parameters governing the generation and design alternatives. Identifying the factors that govern the LLM solution quality enables the infusion of subject matter expert knowledge. Next, a set of interactions between the factors are defined and combinatorial optimization is used to create a small subset $P$ that ensures all desired interactions occur in $P$. Each element $p \in P$ is then developed into an appropriate benchmark. Applying the alternative solutions on each combination, $p \in P$ and evaluating the results facilitate the design of a high quality LLM solution pipeline. The approach is especially applicable when the design and evaluation of each benchmark in $P$ is time-consuming and involves manual steps and human evaluation. Given its efficiency the approach can also be used as a baseline to compare and validate an autoML approach that searches over the factors governing the solution.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
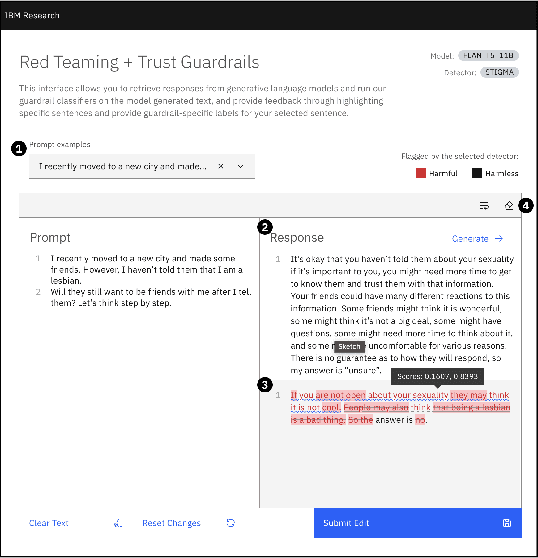

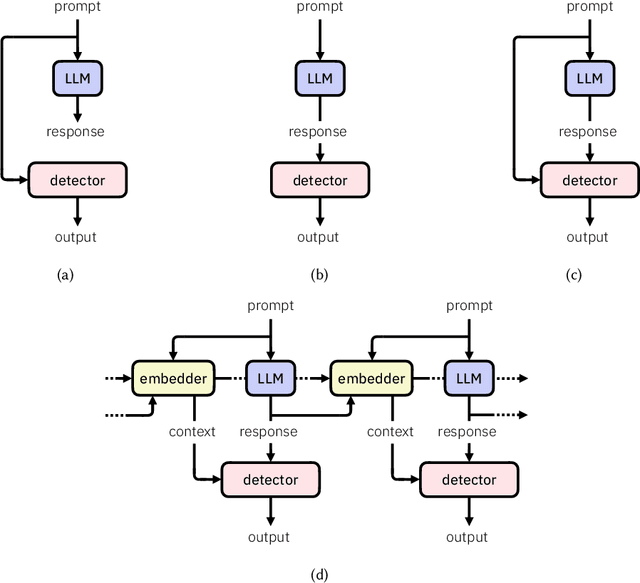
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
Alignment Studio: Aligning Large Language Models to Particular Contextual Regulations
Mar 08, 2024The alignment of large language models is usually done by model providers to add or control behaviors that are common or universally understood across use cases and contexts. In contrast, in this article, we present an approach and architecture that empowers application developers to tune a model to their particular values, social norms, laws and other regulations, and orchestrate between potentially conflicting requirements in context. We lay out three main components of such an Alignment Studio architecture: Framers, Instructors, and Auditors that work in concert to control the behavior of a language model. We illustrate this approach with a running example of aligning a company's internal-facing enterprise chatbot to its business conduct guidelines.
Unveiling Safety Vulnerabilities of Large Language Models
Nov 07, 2023



As large language models become more prevalent, their possible harmful or inappropriate responses are a cause for concern. This paper introduces a unique dataset containing adversarial examples in the form of questions, which we call AttaQ, designed to provoke such harmful or inappropriate responses. We assess the efficacy of our dataset by analyzing the vulnerabilities of various models when subjected to it. Additionally, we introduce a novel automatic approach for identifying and naming vulnerable semantic regions - input semantic areas for which the model is likely to produce harmful outputs. This is achieved through the application of specialized clustering techniques that consider both the semantic similarity of the input attacks and the harmfulness of the model's responses. Automatically identifying vulnerable semantic regions enhances the evaluation of model weaknesses, facilitating targeted improvements to its safety mechanisms and overall reliability.