 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Hyper-Parameter Optimization Methods for Retrieval Augmented Generation
May 06, 2025Finding the optimal Retrieval-Augmented Generation (RAG) configuration for a given use case can be complex and expensive. Motivated by this challenge, frameworks for RAG hyper-parameter optimization (HPO) have recently emerged, yet their effectiveness has not been rigorously benchmarked. To address this gap, we present a comprehensive study involving 5 HPO algorithms over 5 datasets from diverse domains, including a new one collected for this work on real-world product documentation. Our study explores the largest HPO search space considered to date, with two optimized evaluation metrics. Analysis of the results shows that RAG HPO can be done efficiently, either greedily or with iterative random search, and that it significantly boosts RAG performance for all datasets. For greedy HPO approaches, we show that optimizing models first is preferable to the prevalent practice of optimizing sequentially according to the RAG pipeline order.
Statistical multi-metric evaluation and visualization of LLM system predictive performance
Jan 30, 2025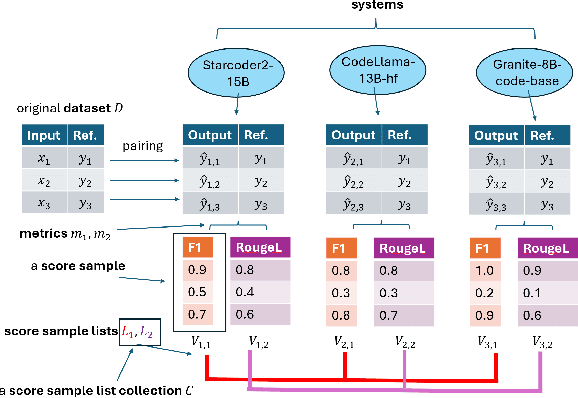

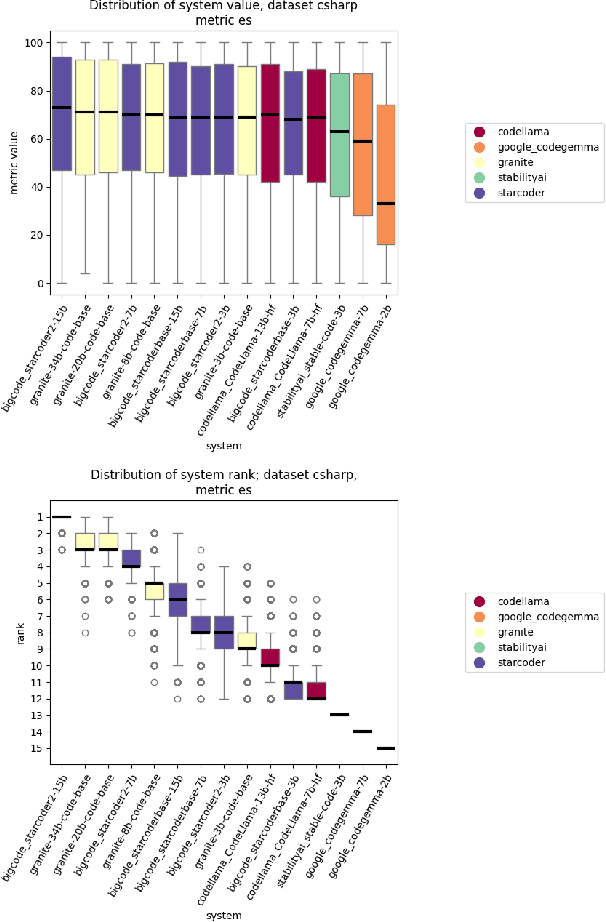
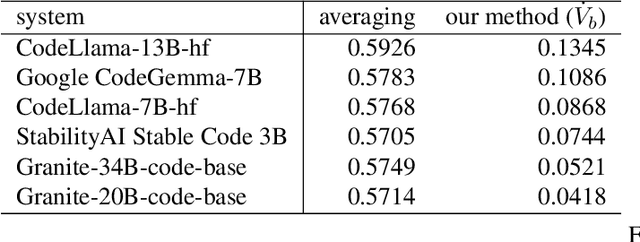
The evaluation of generative or discriminative large language model (LLM)-based systems is often a complex multi-dimensional problem. Typically, a set of system configuration alternatives are evaluated on one or more benchmark datasets, each with one or more evaluation metrics, which may differ between datasets. We often want to evaluate -- with a statistical measure of significance -- whether systems perform differently either on a given dataset according to a single metric, on aggregate across metrics on a dataset, or across datasets. Such evaluations can be done to support decision-making, such as deciding whether a particular system component change (e.g., choice of LLM or hyperparameter values) significantly improves performance over the current system configuration, or, more generally, whether a fixed set of system configurations (e.g., a leaderboard list) have significantly different performances according to metrics of interest. We present a framework implementation that automatically performs the correct statistical tests, properly aggregates the statistical results across metrics and datasets (a nontrivial task), and can visualize the results. The framework is demonstrated on the multi-lingual code generation benchmark CrossCodeEval, for several state-of-the-art LLMs.
Genie: Achieving Human Parity in Content-Grounded Datasets Generation
Jan 25, 2024The lack of high-quality data for content-grounded generation tasks has been identified as a major obstacle to advancing these tasks. To address this gap, we propose Genie, a novel method for automatically generating high-quality content-grounded data. It consists of three stages: (a) Content Preparation, (b) Generation: creating task-specific examples from the content (e.g., question-answer pairs or summaries). (c) Filtering mechanism aiming to ensure the quality and faithfulness of the generated data. We showcase this methodology by generating three large-scale synthetic data, making wishes, for Long-Form Question-Answering (LFQA), summarization, and information extraction. In a human evaluation, our generated data was found to be natural and of high quality. Furthermore, we compare models trained on our data with models trained on human-written data -- ELI5 and ASQA for LFQA and CNN-DailyMail for Summarization. We show that our models are on par with or outperforming models trained on human-generated data and consistently outperforming them in faithfulness. Finally, we applied our method to create LFQA data within the medical domain and compared a model trained on it with models trained on other domains.
VIRATrustData: A Trust-Annotated Corpus of Human-Chatbot Conversations About COVID-19 Vaccines
May 24, 2022
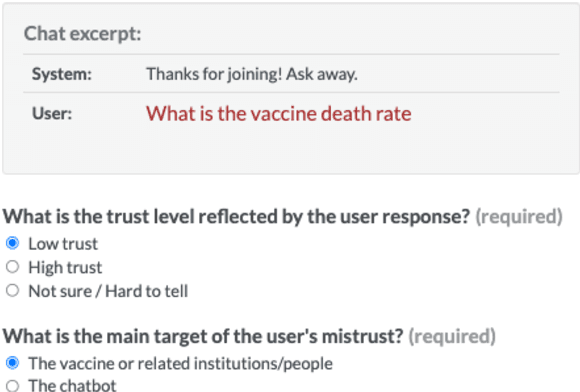
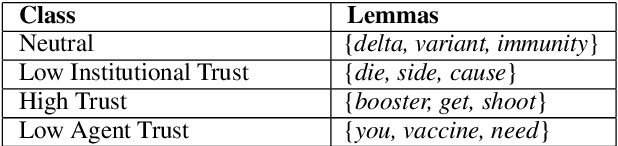
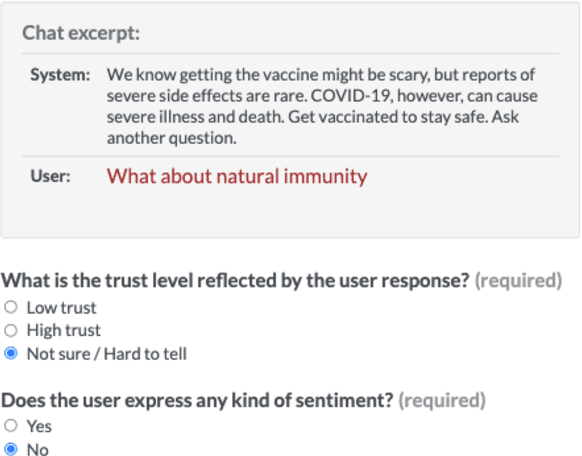
Public trust in medical information is crucial for successful application of public health policies such as vaccine uptake. This is especially true when the information is offered remotely, by chatbots, which have become increasingly popular in recent years. Here, we explore the challenging task of human-bot turn-level trust classification. We rely on a recently released data of observationally-collected (rather than crowdsourced) dialogs with VIRA chatbot, a COVID-19 Vaccine Information Resource Assistant. These dialogs are centered around questions and concerns about COVID-19 vaccines, where trust is particularly acute. We annotated $3k$ VIRA system-user conversational turns for Low Institutional Trust or Low Agent Trust vs. Neutral or High Trust. We release the labeled dataset, VIRATrustData, the first of its kind to the best of our knowledge. We demonstrate how this task is non-trivial and compare several models that predict the different levels of trust.
Benchmark Data and Evaluation Framework for Intent Discovery Around COVID-19 Vaccine Hesitancy
May 24, 2022
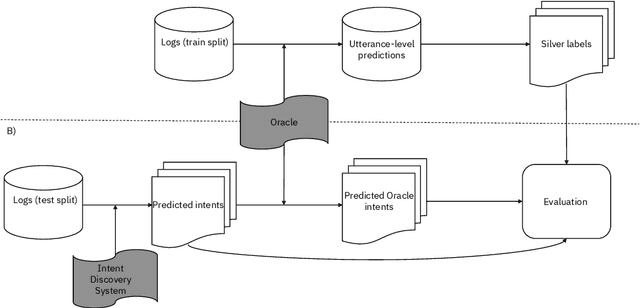

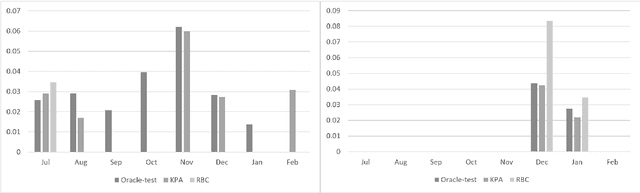
The COVID-19 pandemic has made a huge global impact and cost millions of lives. As COVID-19 vaccines were rolled out, they were quickly met with widespread hesitancy. To address the concerns of hesitant people, we launched VIRA, a public dialogue system aimed at addressing questions and concerns surrounding the COVID-19 vaccines. Here, we release VIRADialogs, a dataset of over 8k dialogues conducted by actual users with VIRA, providing a unique real-world conversational dataset. In light of rapid changes in users' intents, due to updates in guidelines or as a response to new information, we highlight the important task of intent discovery in this use-case. We introduce a novel automatic evaluation framework for intent discovery, leveraging the existing intent classifier of a given dialogue system. We use this framework to report baseline intent-discovery results over VIRADialogs, that highlight the difficulty of this task.
Out of the Echo Chamber: Detecting Countering Debate Speeches
May 03, 2020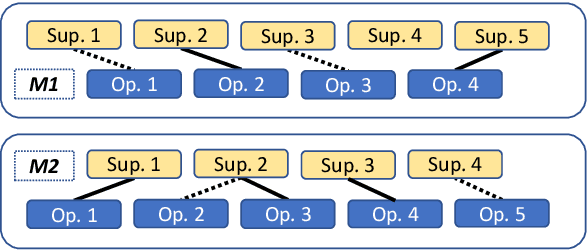
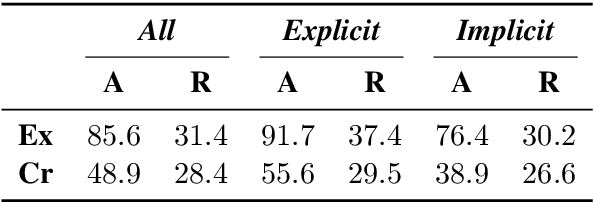
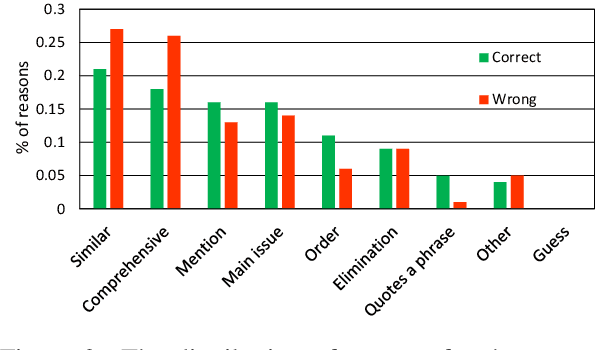

An educated and informed consumption of media content has become a challenge in modern times. With the shift from traditional news outlets to social media and similar venues, a major concern is that readers are becoming encapsulated in "echo chambers" and may fall prey to fake news and disinformation, lacking easy access to dissenting views. We suggest a novel task aiming to alleviate some of these concerns -- that of detecting articles that most effectively counter the arguments -- and not just the stance -- made in a given text. We study this problem in the context of debate speeches. Given such a speech, we aim to identify, from among a set of speeches on the same topic and with an opposing stance, the ones that directly counter it. We provide a large dataset of 3,685 such speeches (in English), annotated for this relation, which hopefully would be of general interest to the NLP community. We explore several algorithms addressing this task, and while some are successful, all fall short of expert human performance, suggesting room for further research. All data collected during this work is freely available for research.
A Large-scale Dataset for Argument Quality Ranking: Construction and Analysis
Nov 26, 2019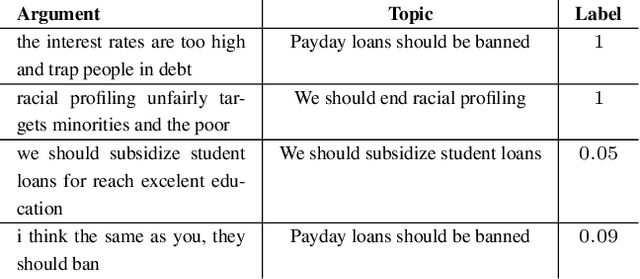
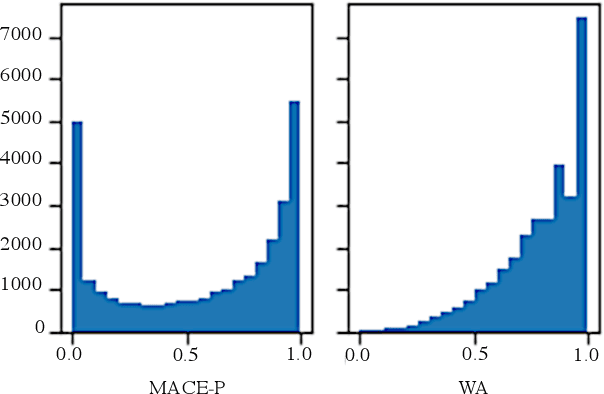

Identifying the quality of free-text arguments has become an important task in the rapidly expanding field of computational argumentation. In this work, we explore the challenging task of argument quality ranking. To this end, we created a corpus of 30,497 arguments carefully annotated for point-wise quality, released as part of this work. To the best of our knowledge, this is the largest dataset annotated for point-wise argument quality, larger by a factor of five than previously released datasets. Moreover, we address the core issue of inducing a labeled score from crowd annotations by performing a comprehensive evaluation of different approaches to this problem. In addition, we analyze the quality dimensions that characterize this dataset. Finally, we present a neural method for argument quality ranking, which outperforms several baselines on our own dataset, as well as previous methods published for another dataset.
Automatic Argument Quality Assessment -- New Datasets and Methods
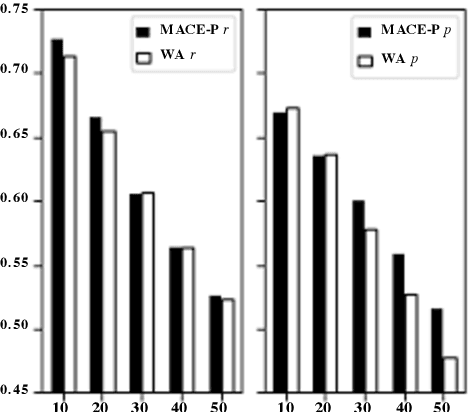
Sep 03, 2019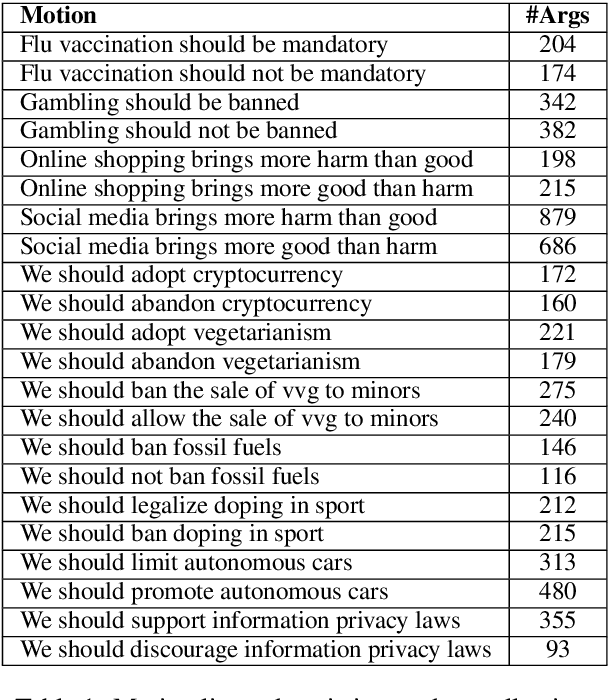
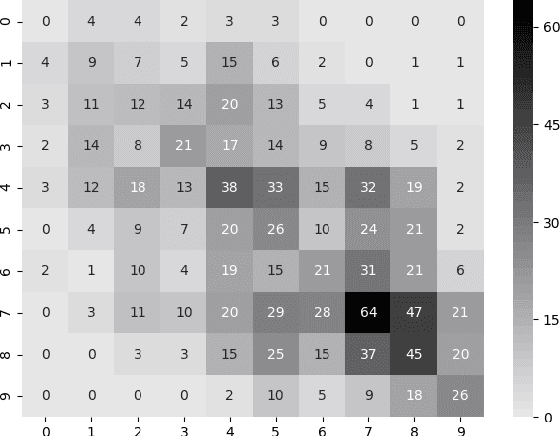
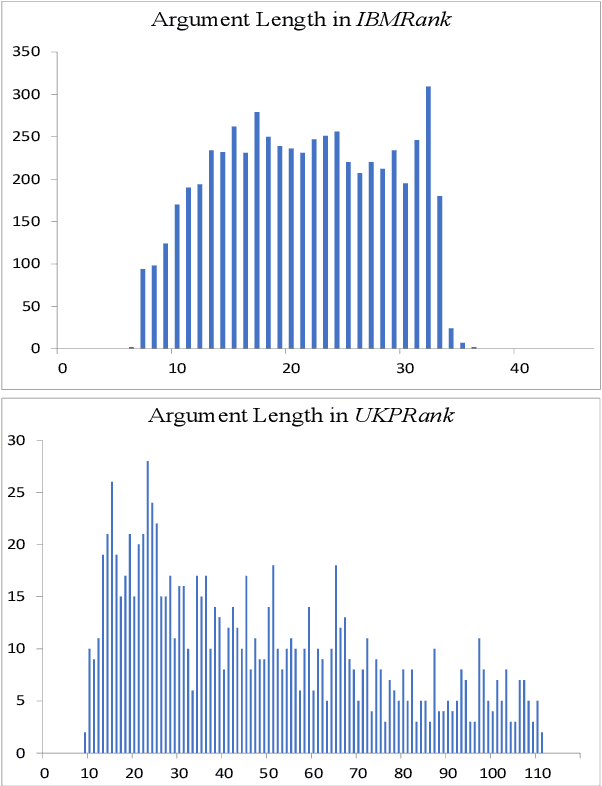
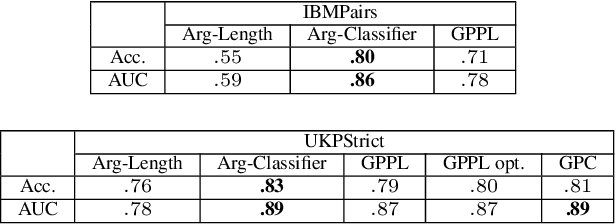
We explore the task of automatic assessment of argument quality. To that end, we actively collected 6.3k arguments, more than a factor of five compared to previously examined data. Each argument was explicitly and carefully annotated for its quality. In addition, 14k pairs of arguments were annotated independently, identifying the higher quality argument in each pair. In spite of the inherent subjective nature of the task, both annotation schemes led to surprisingly consistent results. We release the labeled datasets to the community. Furthermore, we suggest neural methods based on a recently released language model, for argument ranking as well as for argument-pair classification. In the former task, our results are comparable to state-of-the-art; in the latter task our results significantly outperform earlier methods.
Learning to combine Grammatical Error Corrections
Jun 10, 2019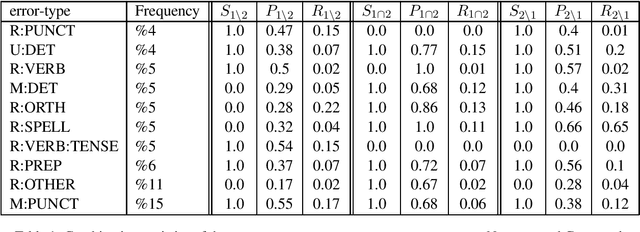
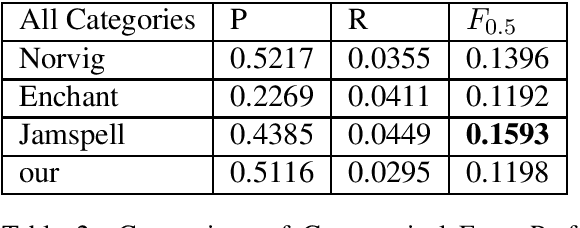
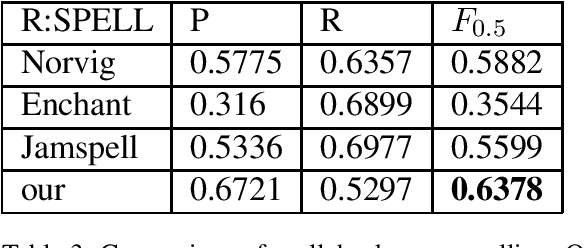
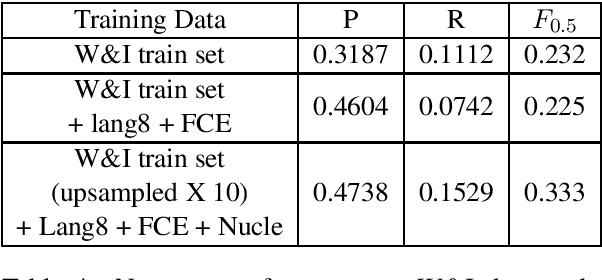
The field of Grammatical Error Correction (GEC) has produced various systems to deal with focused phenomena or general text editing. We propose an automatic way to combine black-box systems. Our method automatically detects the strength of a system or the combination of several systems per error type, improving precision and recall while optimizing $F$ score directly. We show consistent improvement over the best standalone system in all the configurations tested. This approach also outperforms average ensembling of different RNN models with random initializations. In addition, we analyze the use of BERT for GEC - reporting promising results on this end. We also present a spellchecker created for this task which outperforms standard spellcheckers tested on the task of spellchecking. This paper describes a system submission to Building Educational Applications 2019 Shared Task: Grammatical Error Correction. Combining the output of top BEA 2019 shared task systems using our approach, currently holds the highest reported score in the open phase of the BEA 2019 shared task, improving F0.5 by 3.7 points over the best result reported.
Syntactic Interchangeability in Word Embedding Models
Apr 12, 2019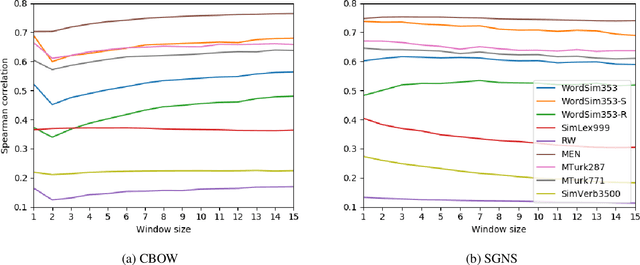
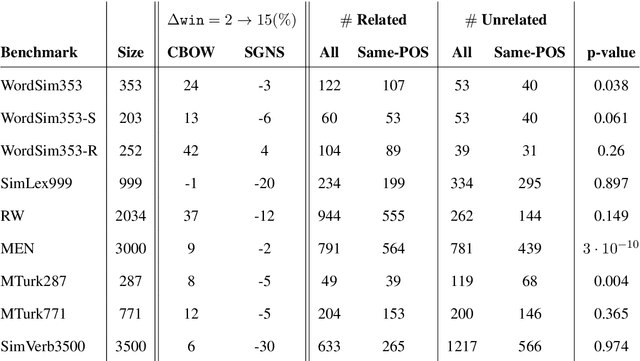
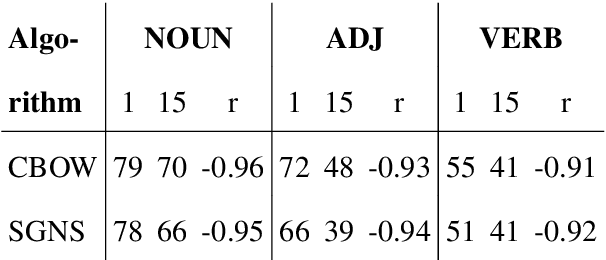
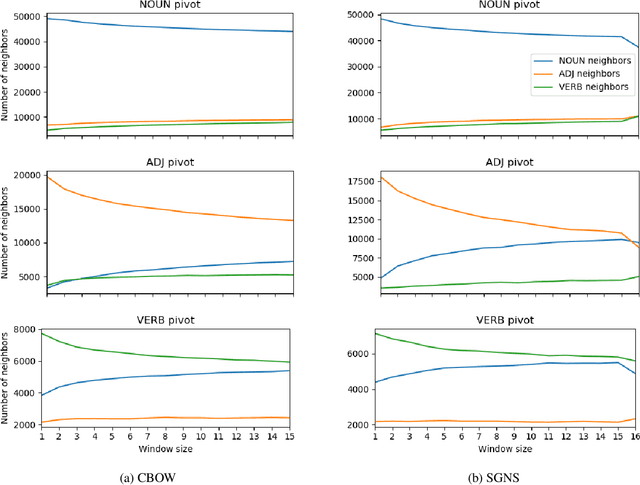
Nearest neighbors in word embedding models are commonly observed to be semantically similar, but the relations between them can vary greatly. We investigate the extent to which word embedding models preserve syntactic interchangeability, as reflected by distances between word vectors, and the effect of hyper-parameters---context window size in particular. We use part of speech (POS) as a proxy for syntactic interchangeability, as generally speaking, words with the same POS are syntactically valid in the same contexts. We also investigate the relationship between interchangeability and similarity as judged by commonly-used word similarity benchmarks, and correlate the result with the performance of word embedding models on these benchmarks. Our results will inform future research and applications in the selection of word embedding model, suggesting a principle for an appropriate selection of the context window size parameter depending on the use-case.